






聚类方法
1、K-means(贪心算法的典型代表)
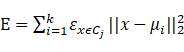 (最小化平方误差)
(最小化平方误差)
E越小,簇内样本相似度越高。
优点:速度快、复杂度低、原理简单、易理解、易于实现。
缺点:对异常点敏感、获得的是局部最优解而不是全局最优解、聚类结果与初始点选取有关、不能发现非凸形状的聚类。
2、子空间聚类(实现高维数据集聚类)
思想:谱聚类:一种基于图论的点对聚类方法。通过对样本数据的拉普拉斯矩阵的特征向量进行聚类。将聚类问题转换为图的最优划分问题。
3、高斯混合模型:由K个单高斯模型组合而成的模型。
混合模型:用来表示在总体分布中含有K个子分布的概率模型。
EM算法:EM(Expectation-Maximum)算法也称期望最大化算法。EM算法是最常见的隐变量估计方法,EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法。
4、DBSCAN聚类
一种基于密度的聚类方法,可发现任意形状的类簇,对噪声不敏感。
DBSCAN的4种关系:密度直达,密度相连,密度可达,非密度相连。
优点:对远离中心的噪声点鲁棒性好
无需知道聚类簇的数量
可以发现任意现状的聚类簇
5、密度峰值聚类
寻找被低密度区域分离的高密度区域。
聚类总结

分类方法
1、K近邻:少数服从多数(对每个特征进行归一化)。K值过小,容易发生过拟合,使用交叉验证法求K值。
2、Logistic回归:对n维输入样本线性加权后得到g(x)![]() 函数,对函数进行sigmoid变换。
函数,对函数进行sigmoid变换。
3、朴素贝叶斯:贝叶斯分类 以贝叶斯定理为基础的一类分类算法的总称,下面A为特征,B为类别。
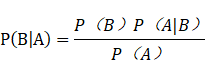
4、支持向量机(SVM):寻找最大间隔超平面,WxT+b=0![]() ,寻找最优决策边界。
,寻找最优决策边界。
5、决策树:每个节点表示一个属性上的判断,每个分支表示一个判断的输出结果,每个叶子结点表示一种分类结果。
关键点:在每一轮迭代中选择最优特征。(信息增益最大被选为划分属性)
三个主要特征:信息增益、增益率、基尼指数















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









