







目录
LlamaFactory是一个开源框架,支持多种流行的语言模型,及多种微调技术,同时,以友好的交互式界面,简化了大语言模型的训练及推理。
本章内容,从如何拉取Llamafactory镜像开始,到构建webui交互式界面,在到加载模型推理、私有化模型的训练及其验证,最后到模型的导出。全程都有示例图,一站式服务,无需你懂代码,无需你拥有高大上的AI基础知识,任何小白都可尝试训练私有模型,并部署在自己的服务器上。
一、拉取镜像
提到AI训练,尤其涉及到大语言模型,势必逃不开GPU。Autodl算力云平台,有多种显卡供你选择,租赁方式灵活多变,时租、日租、月租等等,价格相对实惠。
最主要是可一键拉取社区镜像,避免了自己部署环境时出现的种种bug。
AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
新用户需要注册登录,充值金额可自由选择,初用10块钱即可。

提供多种租赁方式,新手或者不常用者,建议时租(按量计费)或者日租即可。
建议首次选择最低配置 RTX3090 显卡就行,每小时价格约为 1.66 元。平台如果有多余的卡时,蓝色字体 "1卡可租" 点进去。
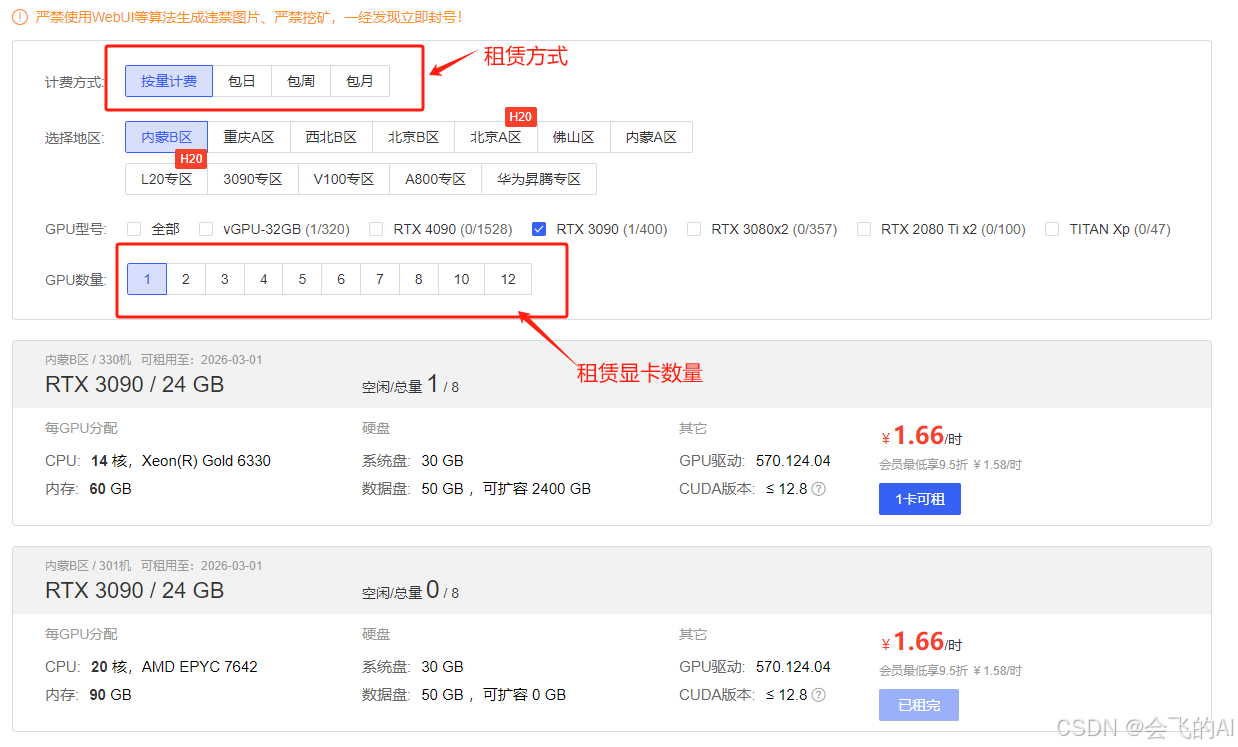
这里有两个注意事项,一是数据扩容,主要是用于存储数据的磁盘,免费50G的空间,首次不建议扩容,够用,而且后面觉得不够,可升降配置。
二是 首次拉取镜像,选择 社区镜像,输入 Llamafactory-webui,就会出现下方镜像,注意辨别账号名称为 HuiFei-AI,这里选择v2版本。
现在该平台使用的人不少,选好机器后,最好快速创建,要不可能机器就没了。
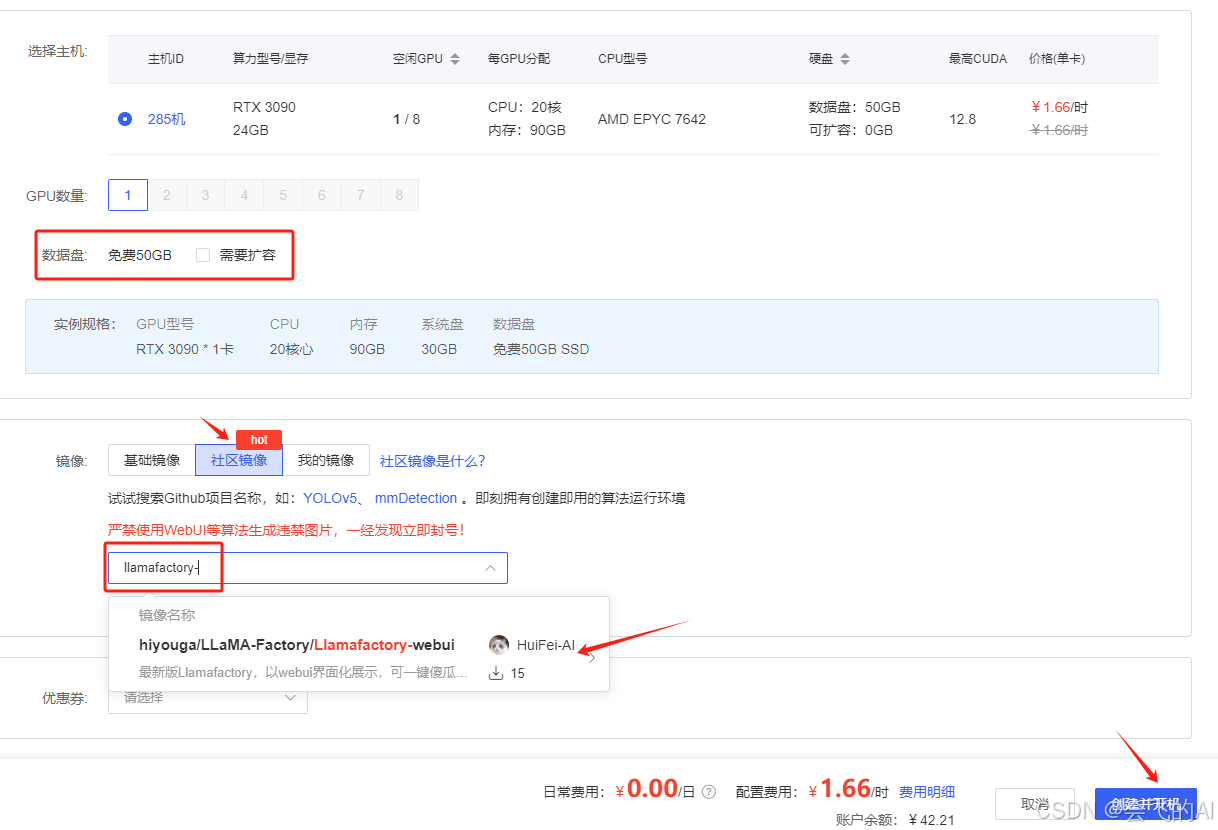
创建并开机后,我的镜像约11个G,首次拉取时可能会慢点,不过还好并不计费,他会在拉取镜像成功之后,自动开机。不过我这次试验,挺快的,2两分钟内就拉取成功开机了。
建议大家首次拉取镜像时,如果选择的GPU配置低,或者磁盘空间小。别慌,首页有个控制台,进入容器实例中,找到你现在运行的机器,点击查看详情,可升降配置,以及扩充磁盘大小。但必须在关机状态下修改,修改后重新开机即可。

二、 构建webui界面
开机后,直接使用平台提供的JupyterLab,服务器是linux系统的。

在构建webui界面前,需要做两项工作,一是内网穿透,二是模型下载
1、内网穿透
ngrok官网 ,首次注册登录,我是用github账号直接登录的
ngrok | API Gateway, Kubernetes Networking + Secure Tunnels![]() https://ngrok.com/登陆成功后,就可以直接获取你自己的认证密钥了
https://ngrok.com/登陆成功后,就可以直接获取你自己的认证密钥了

接下来就是配置你的认证密钥,开启终端,键入如下指令,记得切换你的认证密钥。
ngrok authtoken <你的auth token>成功后,会提示配置文件保存的位置。
![]()
2、模型下载
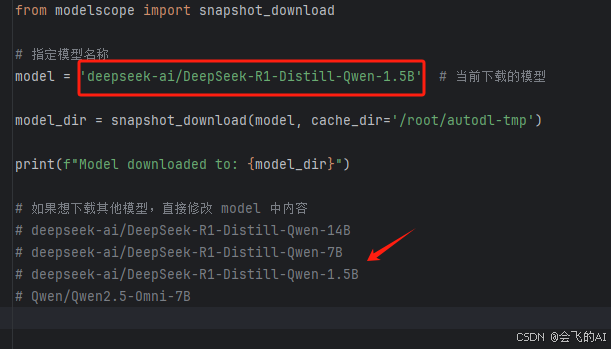
download_model.py 文件,默认是直接下载deepseek-1.5b模型,终端键入以下执行命令
python download_model.py下载进度条,默认存放在 root/autodl-tmp 磁盘中

如果想下载别的模型,修改模型名称,文件里我列举了几个deepseek系列模型。
如果大家还有别的模型需求, 去魔搭社区,点击下方官网链接
ModelScope魔搭社区![]() https://community.modelscope.cn/选择模型库,搜索自己需要的模型名
https://community.modelscope.cn/选择模型库,搜索自己需要的模型名

假如想要下载通义千问QwQ-32B,点进去,复制名称,到 download_model 文件中替换模型名称
注意:上面下载的模型,默认存在autodl-tmp磁盘下,这是数据盘,能随便扩容。
3、wandb安装
wandb是一个实例监控工具,相较于平台上的监控,该工具所展示的信息较为丰富。同ngrok一样,首次需要注册登录,点击下方官网链接
Weights & Biases: The AI Developer Platform (wandb.ai)![]() https://wandb.ai/site登录成功后,点击左上角home
https://wandb.ai/site登录成功后,点击左上角home

然后获取自己的认证密钥,后面要用到。

终端键入以下命令
wandb login --relogin然后输入自己的认证密钥,粘贴密钥后,并不会显示,直接回车确认就行

4、界面构建
上述准备工作完成后,接下来就开始构建webui界面了,终端键入以下命令
cd LLaMA-Factory
llamafactory-cli webui会弹出一个链接,打不开,此时就需要ngrok内网穿透了

打开一个新的终端,键入以下命令,端口号和上述链接保持一致。
ngrok http 7860端口号暴漏成功后,会生成一个链接, 点击链接,可在本机上,打开llamafactory的webui界面了

此时,就正式开启了我们的训练大语言模型的奇妙之旅了。

三、模型推理
在webui界面,可加载本地模型进行推理聊天了,如下图所示:
模型路径 ->填写你下载到服务器上的模型位置,默认在 /root/autodl-tmp/盘符下
选择 chat 模式,然后点击加载模型

模型加载成功后的界面如下,右侧是推理时的超参调节。

切记:模型不用时,记得先卸载模型。因为模型是要加载到内存中的,而模型本身又很大,占用相当大的内存空间。
四、数据加载
llamafactory指定了数据路径,图中data,大家不用修改
数据集下拉选项,有一些 llamafactory 自带的数据集

比如 alpaca_zh_demo 这个中文数据集,选中后,可预览

那大家如何加载到自己的数据集呢 ?请看Llama-factory目录下的data目录,下图是我在本地机器上打开的,大家可在平台中查看该目录。
这里就有我们刚选中的 alpaca_zh_demo 数据集,是一个 json 文件。

大家可以将自己的数据集文件放到该目录下
这里有个注意事项:llamafactory 并不会自动检索data目录下的文件,而是通过一个配置文件,叫dataset_info,也是一个json格式的:

定义key为 “alpaca_zh_demo”,即webui界面,下拉选项中的数据集名称
value为{ "file_name": "alpaca_zh_demo.json"},记录的是数据集在data目录下的真实文件名
五、模型训练
选择 Trian 模式,即训练模式
基础模型还是选择本地路径,数据集选择自带的 alpaca_zh_demo 数据集。剩下的就是微调方式选择,以及超参数的设置
如果大家选择的显卡配置较低,建议 批处理大小为1,截断长度 1024,这些都会降低对机器的要求,保证能训练起来。

在其他参数设置选项中,启用外部记录面板,选择wandb,就可以使用该工具了。

此时在开启训练时,终端会弹出链接,直接点进去就进入到你的wandb帐号了。

这里记录的训练日志信息,比较全面。

模型、数据集、参数都配置好后,点击下方的预览命令,会出现一串指令,是llamafactory 训练的指令集,其中,一些参数就是根据我们上面配置而生成的。
保存训练参数,保存至服务器中,路径自动生成。
载入训练参数,保证模型训练被中断后,可从断点开始训练,而不用重新开启训练。
保存检查点,是模型训练完以后,保存的重要文件,llama会根据时间自动生成文件名。
整体路径,会微调方式,检查点名称自动生成,具体可看预览命令中的 output_dir。默认会放在llamafactory中的save目录下,也就是系统盘中。
这里非常不建议直接用llamafactory自动保存的检查点路径,原因和下载模型那里一样,系统盘会崩的(默认30G),建议大家在输出目录中 添加绝对路径 autodl_tmp/save/train_2025-02-06, 就类似这样的格式,主要目的是将训练后保存的检查点放到数据盘中(可扩容)。

注意:记住上面保存检查点的路径,chat模式下,加载模型检查点时,直接粘贴进去就行了。
开始训练后,webui 上会出现损失曲线,也会在下方打出日志。
当然,在终端也能查看训练进度,如下图所示

超参中,有个设备数量,这个不需要自己填写,程序会自动识别你当前用的GPU数量。
DeepSpeed stage 是一种加速器,后续参数详解会说,感兴趣的可以直接跳转。

六、模型验证及导出
训练结束后,就可以直接加载训练后的模型,进行推理了。
该工具训练后,只会保存检查点,不是一个完整的模型格式。如果大家直接在该webui上加载模型,采用如下图的方式
- 选中本地模型路径,即训练用的基础模型
- 选中保存后的检查点

加载模型,此时就是我们微调后的模型了。此时,可以用训练数据集中的问题,和模型聊天了。
下图就是我们刚才用到的数据集:

同样的问题,提问训练后的模型。

接下来就是将训练后的模型导出来,刚才说了,训练后只保存检查点,需要搭配原模型文件使用。
- 模型路径,检查点,确定都无语后
- 选中 export 模式
- 模型一般较大,分块是指每一个文件的大小,可将模型分为几块保存
- 选择导出目录,开始导出

这个也可以去终端看导出流程,页面上可能长时间没动静,后台依然在工作。
这是我导出来的模型文件,和基础模型的文件配置是一样的


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









