







什么是子查询?
子查询是一种嵌套在其他SQL查询中的查询方式,也可以称作内查询或嵌套查询。当一个查询是另一个查询的条件时,就称之为子查询。子查询的语法格式与普通查询相同,但其在查询过程中起着临时结果集的作用,为主查询提供所需数据或对检索数据进行进一步的限制。
子查询最重要的方面是有所谓的相关子查询和不相关子查询。
相关子查询与不相关子查询
不相关子查询是不从外部引用任何其他内容的查询,而相关子查询是指子 SELECT 内部的查询从外部引用某些内容。
这个区别很重要,因为当 PostgreSQL规划器遇到不相关的子查询时,PostgreSQL不会将其拉入整体查询计划,会将其与主查询分开处理。当这种情况发生时,在计划中看到EXPLAIN所谓的InitPlan.这本质上是一个独立于查询的其余部分完成的初始计划,例如,可以用于执行其他一些查找。但该子查询本身不需要主查询的结果集。
不相关的子查询几乎从来都不是性能问题。原因是它们通常只执行一次。

标量子查询
标量子查询是指查询仅返回单个数据点、单个值。例如,当我们说WHERE我们正在匹配元素的数量时,我们SELECT COUNT(*) FROM something。那么这将是返回的单个值,返回的单个行。这是一个标量子查询。
在FROM返回多行的列表可以使用公共表表达式(CTE)以及IN 或 EXISTS 或 NOT EXISTS 表达式。
标量相关子查询实际上有时候会存在性能问题,如果有标量子查询,由于 PostgreSQL执行它的方式,它必须作为嵌套循环实现。对于遇到的每一行,它都必须评估相关标量子查询。这意味着,如果从开始的表扫描中获得了大量结果,则必须对每个结果运行标量子查询。这会变得非常慢。
优化方式:
将标量子查询重写为join时,PostgreSQL将能够使用除嵌套循环之外的其他连接。或者使用group by having来使PostgreSQL选择更好的连接策略。
IN 与 NOT IN的相关问题
在我们平时写SQL时,如果遇到需要排除某些数据时,往往使用id <> xxx and id <> xxx,进而改进为id not in (xxx, xxx)。
这样写没有问题,而且简化了SQL,但是有时候,使用not in就会造成极大的性能损耗,例如:
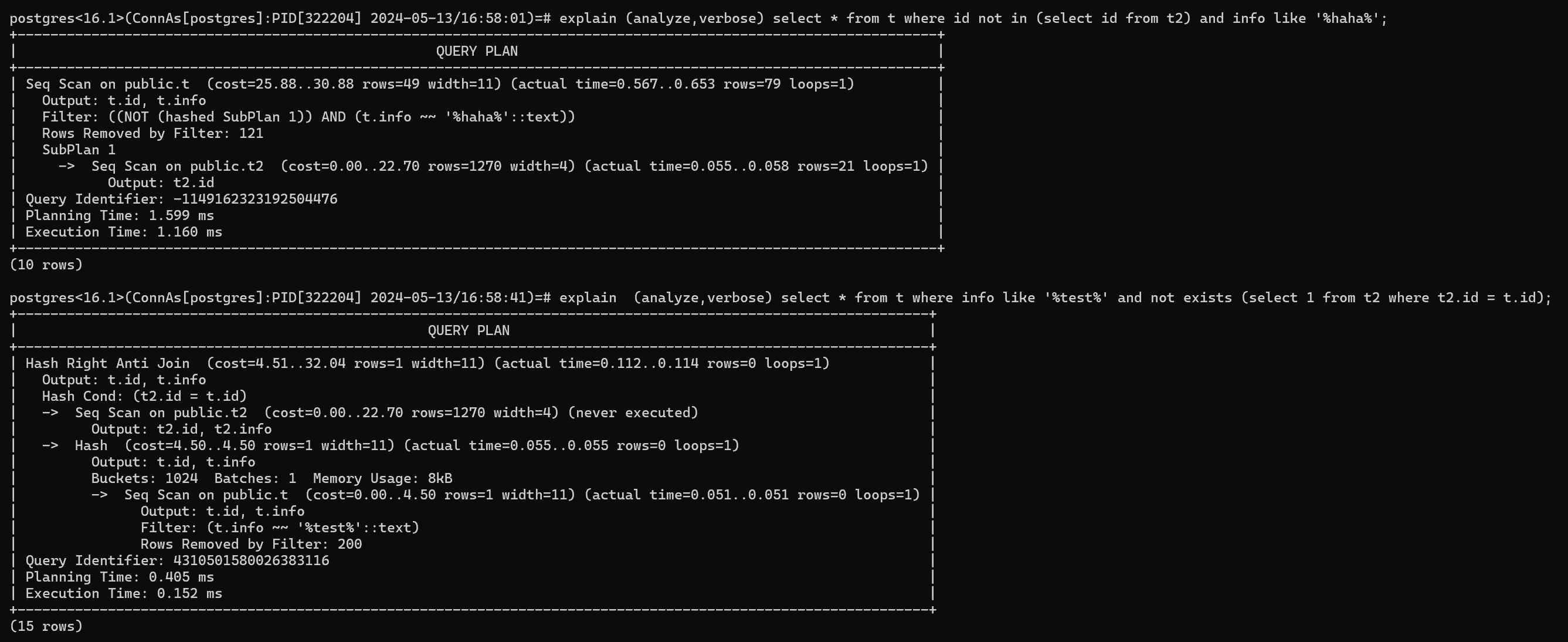
select * from t where id not in (select id from t2) and info like '%haha%';
这样的话select id from t2将成为一个子查询,而且不会走索引,每次走一遍全表扫描。
每一条满足info like '%haha%'的记录都会去调用这个方法去判断id是否不在子查询中,正确的方式应该使用not exists,将条件下推到里面,就不会出现子查询了
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:53:54)=# create table t(id int,info text);
CREATE TABLE
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:53:58)=# insert into t select generate_series(1, 100), 'haha'||round(random()*10000)::text;
INSERT 0 100
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:54:39)=# select * from t limit 10;
+----+----------+
| id | info |
+----+----------+
| 1 | haha8355 |
| 2 | haha677 |
| 3 | haha6474 |
| 4 | haha1194 |
| 5 | haha7640 |
| 6 | haha7955 |
| 7 | haha8621 |
| 8 | haha4712 |
| 9 | haha1299 |
| 10 | haha5464 |
+----+----------+
(10 rows)
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:54:51)=# insert into t select generate_series(101, 200), 'ha'||round(random()*10000)::text;
INSERT 0 100
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:55:19)=# create table t2 as select * from t where id between 50 and 70;
SELECT 21
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:58:01)=# explain (analyze,verbose) select * from t where id not in (select id from t2) and info like '%haha%';
+----------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+----------------------------------------------------------------------------------------------------------------+
| Seq Scan on public.t (cost=25.88..30.88 rows=49 width=11) (actual time=0.567..0.653 rows=79 loops=1) |
| Output: t.id, t.info |
| Filter: ((NOT (hashed SubPlan 1)) AND (t.info ~~ '%haha%'::text)) |
| Rows Removed by Filter: 121 |
| SubPlan 1 |
| -> Seq Scan on public.t2 (cost=0.00..22.70 rows=1270 width=4) (actual time=0.055..0.058 rows=21 loops=1) |
| Output: t2.id |
| Query Identifier: -1149162323192504476 |
| Planning Time: 1.599 ms |
| Execution Time: 1.160 ms |
+----------------------------------------------------------------------------------------------------------------+
(10 rows)
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/16:58:41)=# explain (analyze,verbose) select * from t where info like '%test%' and not exists (select 1 from t2 where t2.id = t.id);
+---------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+---------------------------------------------------------------------------------------------------------------+
| Hash Right Anti Join (cost=4.51..32.04 rows=1 width=11) (actual time=0.112..0.114 rows=0 loops=1) |
| Output: t.id, t.info |
| Hash Cond: (t2.id = t.id) |
| -> Seq Scan on public.t2 (cost=0.00..22.70 rows=1270 width=4) (never executed) |
| Output: t2.id, t2.info |
| -> Hash (cost=4.50..4.50 rows=1 width=11) (actual time=0.055..0.055 rows=0 loops=1) |
| Output: t.id, t.info |
| Buckets: 1024 Batches: 1 Memory Usage: 8kB |
| -> Seq Scan on public.t (cost=0.00..4.50 rows=1 width=11) (actual time=0.051..0.051 rows=0 loops=1) |
| Output: t.id, t.info |
| Filter: (t.info ~~ '%test%'::text) |
| Rows Removed by Filter: 200 |
| Query Identifier: 4310501580026383116 |
| Planning Time: 0.405 ms |
| Execution Time: 0.152 ms |
+---------------------------------------------------------------------------------------------------------------+
(15 rows)
exits和not exits的意思是逐条将条件下放到判断条件,而join方式是先对表进行笛卡尔积,然后判断同行之间的各列值是否满足关系。exists,由于优化器会默认它只需要搜索到1条命中目标就不搜了,所以优化器评估是否使用hash table时,需要的内存相对较少,即使较小的work_mem也可能使用hashtable。in ,当出现在subquery中时,优化器评估这个subquery是否要构建哈希TABLE,直接和subquery的大小相关,所以需要较大的work_mem才会选择使用hashtable。
除此之外PostgreSQL的not in不能识别到null。not in 后面的集合中有null值,会导致查询失效。
所以可以在使用 not in 后的集合中 使用 is not null 避免查询失效,或者使用 not exists替代
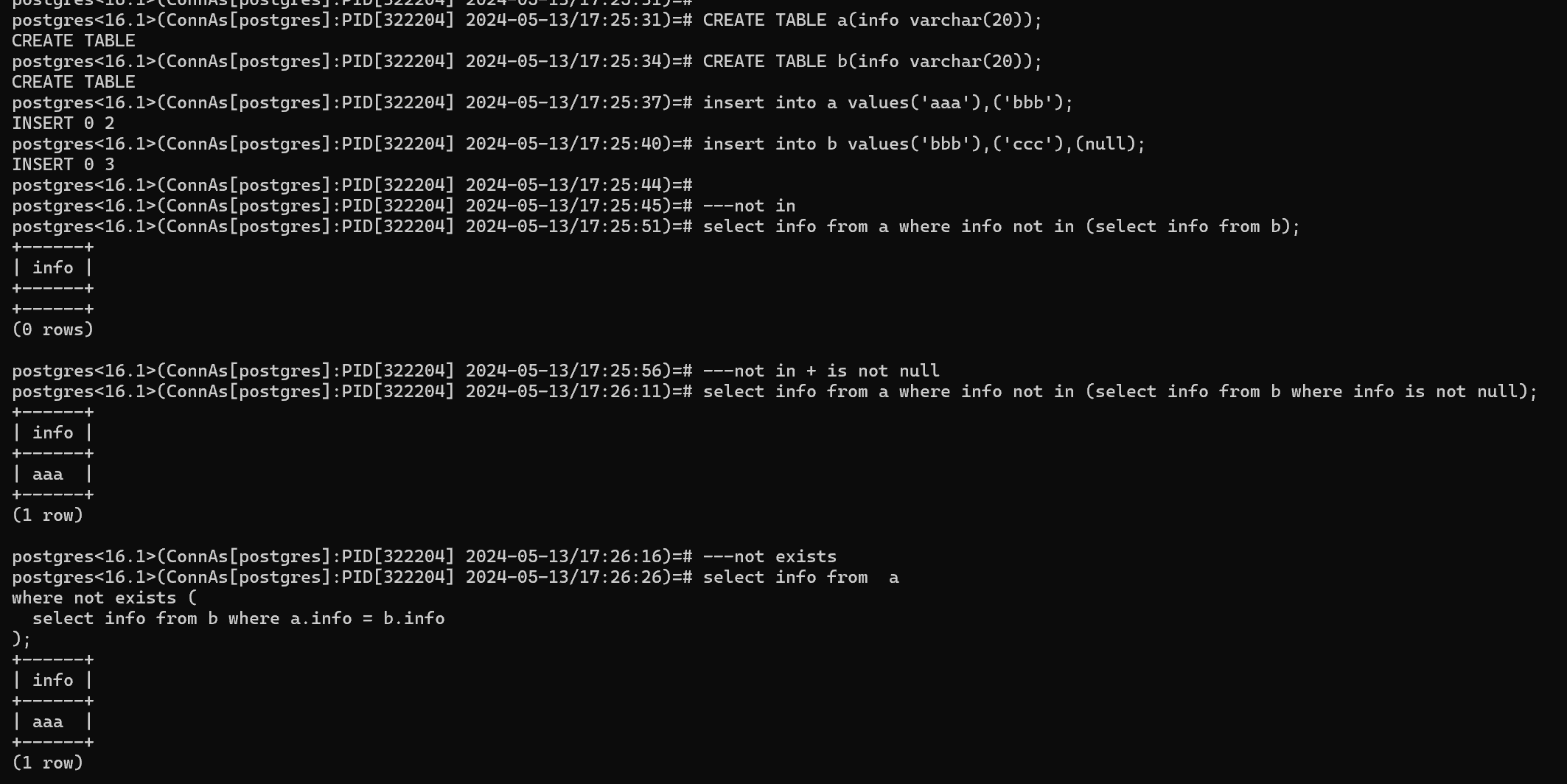
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:31)=# CREATE TABLE a(info varchar(20));
CREATE TABLE
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:34)=# CREATE TABLE b(info varchar(20));
CREATE TABLE
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:37)=# insert into a values('aaa'),('bbb');
INSERT 0 2
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:40)=# insert into b values('bbb'),('ccc'),(null);
INSERT 0 3
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:44)=#
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:45)=# ---not in
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:51)=# select info from a where info not in (select info from b);
+------+
| info |
+------+
+------+
(0 rows)
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:25:56)=# ---not in + is not null
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:26:11)=# select info from a where info not in (select info from b where info is not null);
+------+
| info |
+------+
| aaa |
+------+
(1 row)
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:26:16)=# ---not exists
postgres<16.1>(ConnAs[postgres]:PID[322204] 2024-05-13/17:26:26)=# select info from a
where not exists (
select info from b where a.info = b.info
);
+------+
| info |
+------+
| aaa |
+------+
(1 row)
执行计划对比如下
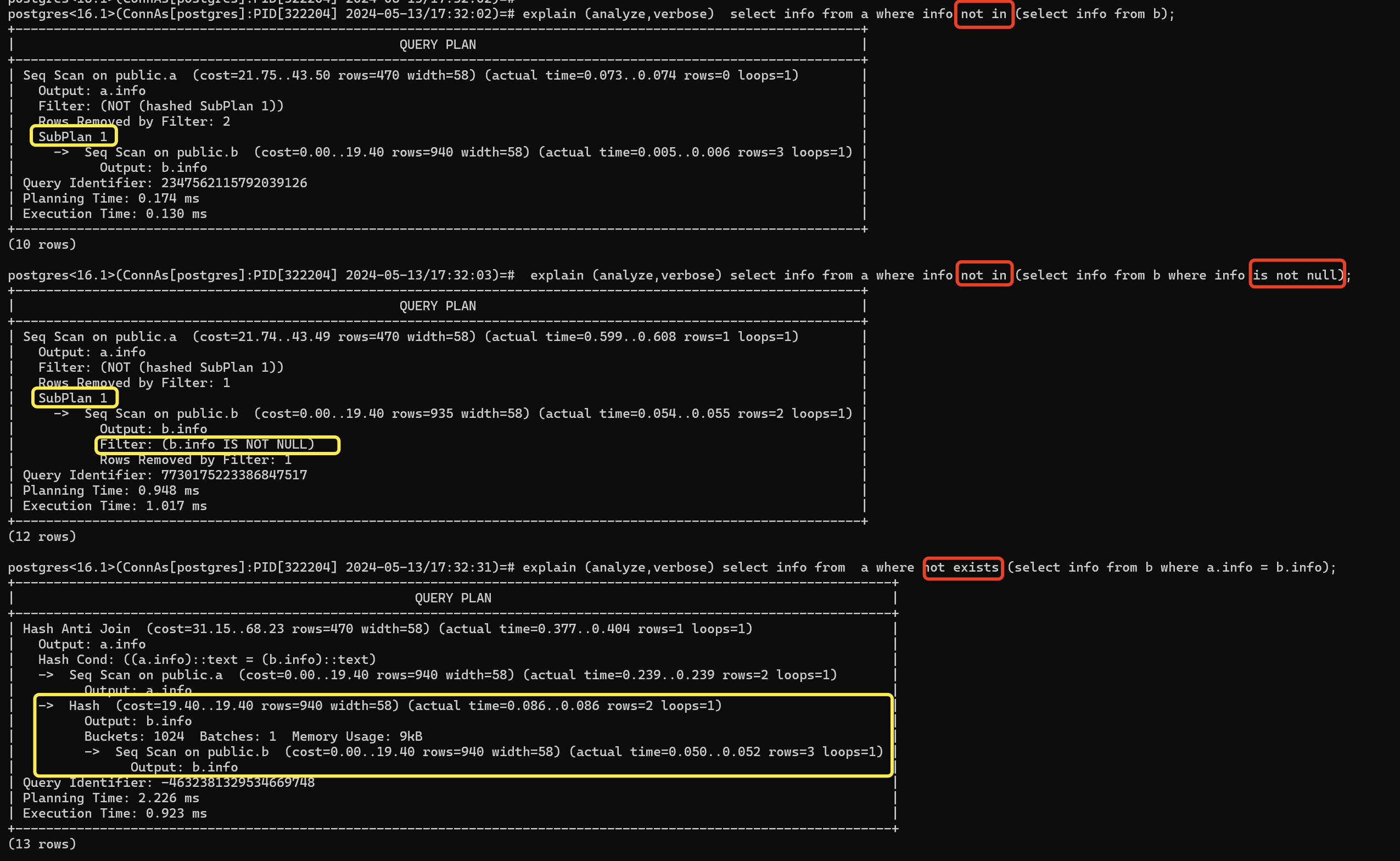
因此需要注意not in的这个集合中有null值,会导致查询失效问题,并且酌情可以考虑使用exists优化in。

















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











