









一.字典树概念
字典树又被称作Trie树,其效率非常高,所以在字符串查找,前缀匹配中应用非常广泛,其高效率是以空间为代价的。典型应用是用于统计和排序大量的字符串,它的优点是,最大限度地减少无谓的字符串比较,查询效率比哈希表更高。
字典树类似于查字典的操作
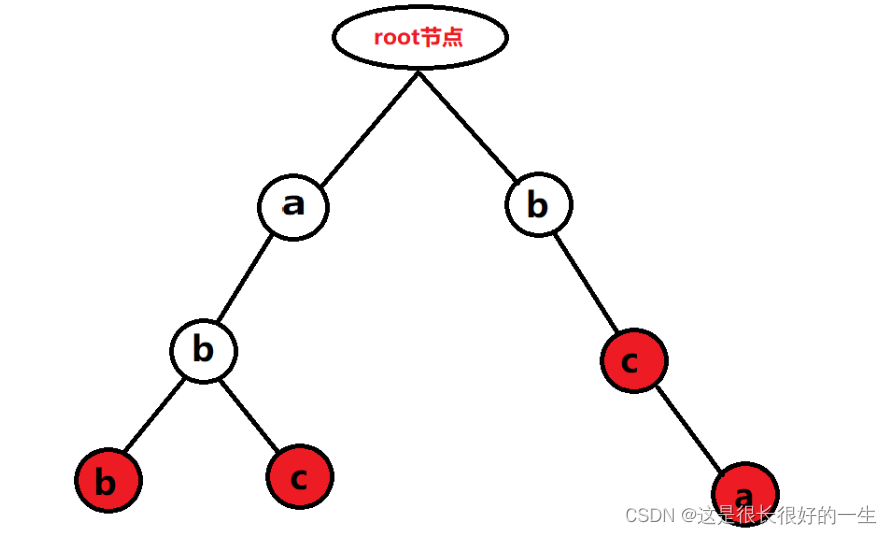
如果你要在字典中查找单词“Black”,先找到首字母为‘B’的部分,然后再找第二个单词为‘l’的部分······最后,可能可以找到这个单词,当然,也有可能这本词典并没有这个单词。如图
struct TrieNode {
bool isWord;
struct TrieNode [26]children;
}
isWord为true的节点,举个例子,两个字符串"cat"和"catch",字符t和字符h对应的节点,就是红色的(isWord = true)
第二点利用了一个长度为26的TrieNode[]数组,用下标表示字符(char - 'a'),用该下标对应的值表示指向子节点的引用。例如字符串"cat",根节点只有c对应的那个下标(‘c’ - ‘a’ = 2)才是有值的,其余的全为null,表示这条路走不通。
struct TrieNode { // 节点
bool isWord;
struct TrieNode[26] children ;
TrieNode *TrieInit() {
struct TrieNode *root; // 根节点
root->isWord=false;
//【向字典树插入单词word】
// 思路:按照word的字符,从根节点开始,一直向下走:
// 如果遇到null,就new出新节点;如果节点已经存在,cur顺着往下走就可以
void insert(struct TrieNode *root,char * word) {
struct TrieNode *cur = root; // 先指向根节点
for (int i = 0; i < word.length(); i++) { // 如果是【后缀树】而不是【前缀树】,把单词倒着插就可以了,即for(len-1; 0; i--)
int c = word[i] - 'a'; // (关键) 将一个字符用数字表示出来,并作为下标
if (cur.children[c] == null) {
cur.children[c] = TrieInit();
}
cur = cur.children[c];
}
cur.isWord = true; // 一个单词插入完毕,此时cur指向的节点即为一个单词的结尾
}
//【判断一个单词word是否完整存在于字典树中】
// 思路:cur从根节点开始,按照word的字符一直尝试向下走:
// 如果走到了null,说明这个word不是前缀树的任何一条路径,返回false;
// 如果按照word顺利的走完,就要判断此时cur是否为单词尾端:如果是,返回true;如果不是,说明word仅仅是一个前缀,并不完整,返回false
bool search(char *word) {
struct TrieNode* cur = root;
for (int i = 0; i < word.length(); i++) {
int c = word[i] - 'a';
if (cur.children[c] == null) {
return false;
}
cur = cur.children[c];
}
return cur.isWord;
}
//【判断一个单词word是否是字典树中的前缀】
// 思路:和sesrch方法一样,根据word从根节点开始一直尝试向下走:
// 如果遇到null了,说明这个word不是前缀树的任何一条路径,返回false;
// 如果安全走完了,直接返回true就行了———我们并不关心此事cur是不是末尾(isWord)
bool startsWith(char * word) {
struct TrieNode *cur = root;
for (int i = 0; i < word.length(); i++) {
int c = word[i] - 'a';
if (cur.children[c] == null) {
return false;
}
cur = cur.children[c];
}
return true;
}
}
例题
在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
#define MAX_STR_LEN 1024
typedef struct Trie {
bool isEnd;
struct Trie *children[26];
} Trie;
Trie * creatTrie() {
Trie *node = (Trie *)malloc(sizeof(Trie));
for (int i = 0; i < 26; i++) {
node->children[i] = NULL;
}
node->isEnd = false;
return node;
}
void freeTrie(Trie *root) {
for (int i = 0; i < 26; i++) {
if (root->children[i]) {
freeTrie(root->children[i]);
}
}
free(root);
}
char *findRoot(const char *word, Trie *trie) {
char *root = (char *)malloc(sizeof(char) * MAX_STR_LEN);
Trie *cur = trie;
int len = strlen(word);
int pos = 0;
for (int i = 0; i < len; i++) {
char c = word[i];
if (cur->isEnd) {
root[pos] = 0;
return root;
}
if (!cur->children[c - 'a']) {
free(root);
return word;
}
root[pos++] = c;
cur = cur->children[c - 'a'];
}
root[pos] = 0;
return root;
}
char ** split(char *str, char ch, int *returnSize) {
int len = strlen(str);
char **res = (char **)malloc(sizeof(char *) * len);
int i = 0, pos = 0;
while (i < len) {
while (i < len && str[i] == ch) {
i++;
}
int start = i;
while (i < len && str[i] != ch) {
i++;
}
if (start < len) {
res[pos] = (char *)malloc(sizeof(char) * (i - start + 1));
memcpy(res[pos], str + start, sizeof(char) * (i - start));
res[pos][i - start] = '\0';
pos++;
}
}
*returnSize = pos;
return res;
}
char * replaceWords(char ** dictionary, int dictionarySize, char * sentence){
Trie *trie = creatTrie();
for (int i = 0; i < dictionarySize; i++) {
Trie *cur = trie;
int len = strlen(dictionary[i]);
for (int j = 0; j < len; j++) {
char c = dictionary[i][j];
if (!cur->children[c - 'a']) {
cur->children[c - 'a'] = creatTrie();
}
cur = cur->children[c - 'a'];
}
cur->isEnd = true;
}
int wordsSize = 0, pos = 0;
char **words = split(sentence, ' ', &wordsSize);
char *ans = (char *)malloc(sizeof(char) * (strlen(sentence) + 2));
for (int i = 0; i < wordsSize; i++) {
char * ret = findRoot(words[i], trie);
pos += sprintf(ans + pos, "%s ", ret);
free(words[i]);
if (ret != words[i]) {
free(ret);
}
}
ans[pos - 1] = '\0';
freeTrie(trie);
return ans;
}
作者:LeetCode-Solution
链接:https://leetcode.cn/problems/replace-words/solution/dan-ci-ti-huan-by-leetcode-solution-pl6v/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









