






环境:python3.6.4,keras2.1.5,tensorflow2.1.0,4g专用gpu,cuda10.0
图片链接:http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz。
目前运行结果,训练集loss0.01,测试集loss0.2.
书上的结果图:
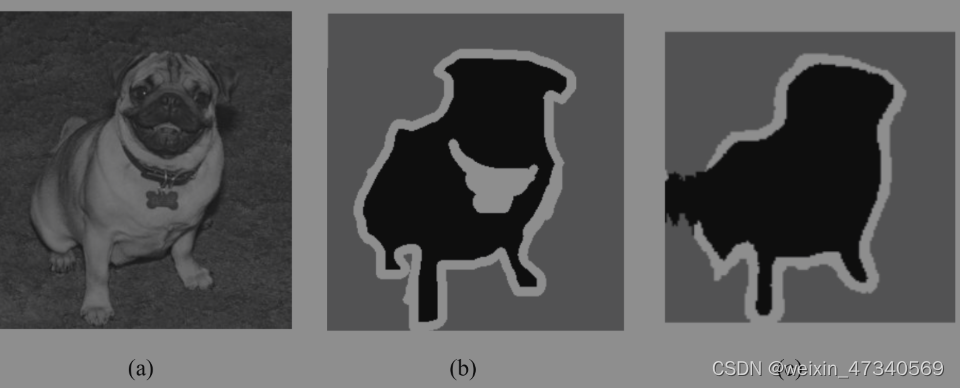
我的运行结果:

2023.11.7
目标:把数据集替换成自己的数据集
自己的数据集:tif格式,4通道,大小512*512.
尝试一:
1.用gdal.Open()和gdal.ReadAsArray()替换,示例代码里的OxfordPets类里的load_img()函数,能跑通,但是loss为nan。
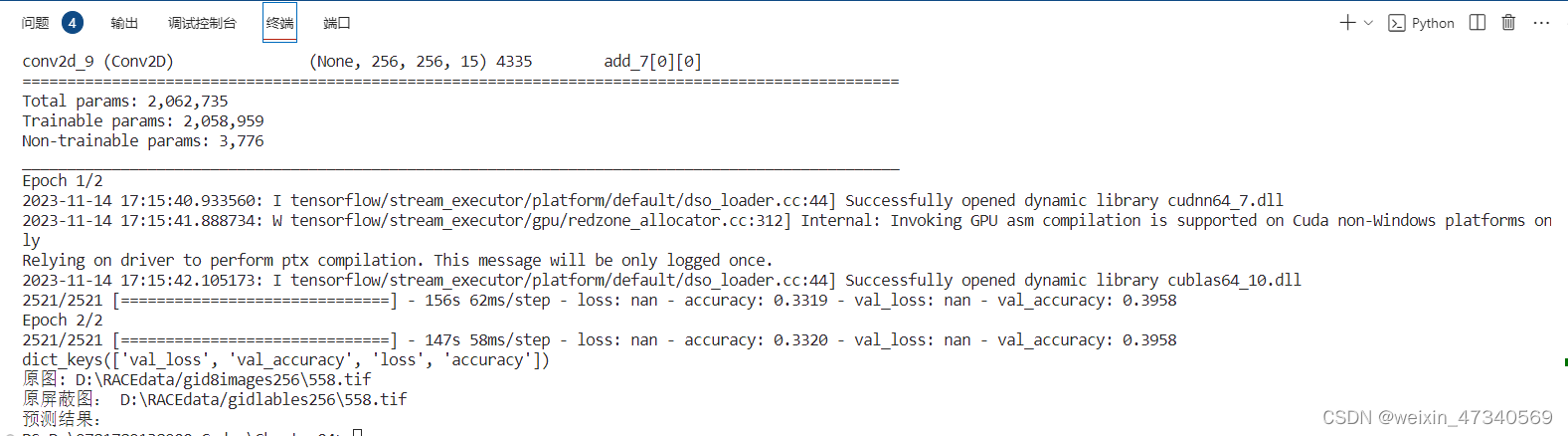
没解决。
实验一:
用gdal.open()打开猫狗数据集试验,猫狗数据集里图像尺寸大小不固定。
1.比较cv2.imread(),skimage.io.imread(),gdal.Open(),load_img()的打开图像功能。
cv2.imread()最多支持4波段。load_img()只支持3波段
gdal.open()和skimage.io.imread()支持多波段,打开后数组的shape为(波段数,长,宽,)
左为load_img()函数, 右为gdal.Open()函数打开的图像,交换两次轴的结果。


左为skimage.io.imread()函数, 右为cv2.imread()函数


实验二:
数组转置与数组交换两次轴的结果对比:
testarray=np.array([[[1,2],[3,4]],[[5,6],[7,8]],[[9,10],[11,12]]])
print(testarray,testarray.shape)
print("转置:",testarray.transpose())
testarray2=testarray.swapaxes(1,0)
testarray2=testarray2.swapaxes(1,2)
print(testarray2)testarray输出结果:

testarray.transpose()输出结果:

交换轴(1,0) 从(3,2,2,)换成(2,3,2)

交换两次轴(1,0),(1,2)从(3,2,2)到(2,3,2)到(2,2,3)

实验三:
2.使用skimage中的resize,np.resize,cv2.resize 修改输入图片的尺寸
cv2.resize支持3波段,修改后能保存为图片。
skimage中的resize和np.resize支持多波段,但是skimage中的resize会自动将图片的像素值转到【0,1】之间。
使用skimage中的.io.imsave函数保存为‘png’格式,需要将(通道数,长,宽)的数组转为(长,宽,通道数)的格式。保存的3通道图片显示为混乱的像素点叠加。
原图是小狗图片,resize之后的数组保存成图片如右图。。

3.再回头输入自己的数据集时报错。AttributeError: module 'tensorflow' has no attribute 'reset_default_graph'
百度有的说改语句,有的说是keras和tensorflow版本不一致造成的。重新安装keras2.3.1.问题解决。
2023.11.14
为了解决替换成自己的数据集,loss为nan的问题。
尝试一:
搜索《深度学习全书》9-3语义分割实践示例代码,和《python 深度学习》一书中9.2图像分割示例,发现数据集,训练集和测试集的划分方式都一样。
区别在于:
1.本次示例代码,编写了OxfordPets类来生成小批量数据,数据是PIL.image格式,《python 深度学习》一书中9.2是完全加载数据,数据是img_to_array(load_img())格式。
2.在get_model函数中,《python 深度学习》多了一句,x=layers.rescaling(1./255)。
本次示例代码中没进行图片像素值/255的操作。
3.在示例代码中,添加像素值/255的语句。由于数据集是gid数据集,有16bit的有8bit的,用8bit的数据集,添加了像素值/255的语句后,没有变化。
4.确认在本次示例代码中,小批量数据生成器的数据为,[batchsize,图像长,图像宽,图像波段数]的形状的数组。没有/255的语句。
尝试二:
keras遥感图像Unet语义分割(支持多波段&多类) - 知乎 (zhihu.com)
对上述链接里的代码研究了一下,这个代码更加复杂,对标签文件进行onehot编码。其他划分数据集,传递数据,训练模型大致相似。
主要区别在对标签文件的处理上。
1.本次示例代码书上所给的猫狗数据集的标签文件,标注的像素值只有【1 2 3】
自己的数据集里的标签文件,标注像素值有[0, 1, 2, 3, 5, 6, 11, 12, 13, 14, 17, 18, 20, 21, 22]
2.在知乎专栏这个代码里,先将标签文件读入的numpy数组里的元素值替换成对应的[0 1 2 3 4 5 6 7 8 9]等等,再进行独热编码。
3.在本次的示例代码中,仿照2中的colordict函数,获取标签文件夹里所有标签的像素值范围,并转成对应的[0 1 2 3 ]等等。
4.用gdal.Open函数打开猫狗数据集,用numpy.resize读入固定尺寸大小的数据,运行时loss不是nan。
5.将自己的标签数据集按3处理以后,loss不是nan。
def color_dict(labelFolder, classNum):
colorDict = []
# 获取文件夹内的文件名
#ImageNameList = os.listdir(labelFolder)
#print(labelFolder)
#print(ImageNameList)
for i in range(len(labelFolder)):
ImagePath = labelFolder[i]
#print(ImagePath)
data1=gdal.Open(ImagePath)
img=data1.ReadAsArray()
#print(img.shape)
unique = np.unique(img)
#print(unique)
# 将第i个像素矩阵的唯一值添加到colorDict中
for j in range(unique.shape[0]):
colorDict.append(unique[j])
# 对目前i个像素矩阵里的唯一值再取唯一值
colorDict = sorted(set(colorDict))
# 若唯一值数目等于总类数(包括背景)ClassNum,停止遍历剩余的图像
if(len(colorDict) == classNum):
break
colorDict=np.array(colorDict)
#print(colorDict.shape)
colorDict=colorDict.reshape(colorDict.shape[0],1).astype(np.uint8)
return colorDictfor i in range(colordict.shape[0]):
img[img == colordict[i][0]] = i 将这个语句加入OxfordPets类中存储标签数据的数组中。

下一步:提高精度。
代码如下:
from tensorflow import keras
#查看环境路径下的image所在路径
from tensorflow.python.keras.preprocessing.image import load_img
from tensorflow.python.keras import layers#
import PIL
from PIL import ImageOps
from PIL import Image
from PIL import Image as imgop
import numpy as np
import os
from IPython.display import display,Image
#训练数据集路径
#加载训练好的模型:用load_model()和先get_model()再用load_weights(),效果一样。
#之所以一直不输出结果,是因为cuda的套件后缀是100而不是10,gpu没启用。
root_path=r"D:\2306test"
input_dir=root_path+"/images/images"
target_dir=root_path+"/annotations/trimaps" #
#超参数设定
img_size=(160,160)
num_classes=4 #类别个数
batch_size=32
#取得所有图片文件绝对路径
input_img_paths=sorted(
[os.path.join(input_dir,fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
]
)
#取得所有遮罩图片文件路径
target_img_paths=sorted(
[os.path.join(target_dir,fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png")and not fname.startswith(".")
]
)
#统计所有样本个数并输出
print("样本数:",len(input_img_paths))
""" 显示第10张图,使用PIL库,显示原图和调整对比度以后的mask文件
print(input_img_paths[9])
img1=imgop.open(input_img_paths[9])
img1.show()
display(Image(filename=input_img_paths[9]))
#调整对比,将最深的颜色当作黑色(0),最浅的颜色当作白色(255)
print(target_img_paths[9])
img=PIL.ImageOps.autocontrast(load_img(target_img_paths[9]))
img.show()
display(img) """
#建立图像的iterator,传入原始图像路径和mask文件路径,传入设置好的超参数,
#iterator一次传回一批图像,不必一全部加载至内存,迭代器是numpy arrays格式
class OxfordPets(keras.utils.Sequence):
def __init__(self,batch_size,img_size,input_img_paths,target_img_paths):
self.batch_size=batch_size
self.img_size=img_size
self.input_img_paths=input_img_paths
self.target_img_paths=target_img_paths
def __len__(self):
return len(self.target_img_paths)
#这个函数,把原始数据集按batchsize大小分成一批一批,返回第idx批的(input,target)形式,(图像,对应的mask)形式
def __getitem__(self,idx):
i=idx*self.batch_size
batch_input_img_paths=self.input_img_paths[i:i+self.batch_size]
batch_input_target_paths=self.target_img_paths[i:i+self.batch_size]
x=np.zeros((batch_size,)+self.img_size+(3,),dtype="float32")
for j,path in enumerate(batch_input_img_paths):
img=load_img(path,target_size=self.img_size)
x[j]=img
y=np.zeros((batch_size,)+self.img_size+(1,),dtype="uint8")
for j,path in enumerate(batch_input_target_paths):
img=load_img(path,target_size=self.img_size,color_mode="grayscale")
y[j]=np.expand_dims(img,2)
return x,y
#搭建unet模型
def get_model(img_size,num_classes):
#separableConv2D神经层会针对色彩通道分别进行卷积
#模型output设为4,等于num_classes参数,一般filter都设置为4的倍数,作者利用后续的display_mask函数取最大值,
# 判断屏蔽图的每一个像素是黑或是白,也有人直接设为1,详情参阅understanding semantic segmentation with unet
inputs=keras.Input(shape=img_size+(3,))
#编码器
x=layers.Conv2D(32,3,strides=2,padding="same")(inputs)
x=layers.BatchNormalization()(x)
x=layers.Activation("relu")(x)
previous_block_activation=x #set aside residual
#除了特征图大小,三个区块均相同
for filters in [64,128,256]:
x=layers.Activation("relu")(x)
x=layers.SeparableConv2D(filters,3,padding="same")(x)
x=layers.BatchNormalization()(x)
x=layers.Activation("relu")(x)
x=layers.SeparableConv2D(filters,3,padding="same")(x)
x=layers.BatchNormalization()(x)
x=layers.MaxPooling2D(3,strides=2,padding="same")(x)
#残差层
residual=layers.Conv2D(filters,1,strides=2,padding="same")(previous_block_activation)
x=layers.add([x,residual])#加入back residual
previous_block_activation=x #set aside next residual
#解码器
for filters in[256,128,64,32]:
x=layers.Activation("relu")(x)
x=layers.Conv2DTranspose(filters,3,padding="same")(x)
x=layers.BatchNormalization()(x)
x=layers.Activation("relu")(x)
x=layers.Conv2DTranspose(filters,3,padding="same")(x)
x=layers.BatchNormalization()(x)
x=layers.UpSampling2D(2)(x)
#残差层(residual)
residual=layers.UpSampling2D(2)(previous_block_activation)
residual=layers.Conv2D(filters,1,padding="same")(residual)
x=layers.add([x,residual])
previous_block_activation=x
#卷积 per-pixel
outputs =layers.Conv2D(num_classes,3,activation="softmax",padding="same")(x)
model=keras.Model(inputs,outputs)
return model
#释放内存,以防执行多次造成内存的占用
keras.backend.clear_session()
#建立unet模型
#model=keras.models.load_model(r'D:\9781789138900_Codes\Chapter04\oxford_segmentation0925.h5')
model=get_model(img_size,num_classes)
model.summary()
#画u型图结构
import tensorflow as tf
tf.keras.utils.plot_model(model,to_file='Unet_model1008.png')
#分割数据集,在大数据集中,1000,1337,在小数据集中,20,30
import random
val_samples=1000
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_img_paths)
train_input_img_paths=input_img_paths[:-val_samples]
train_target_img_paths=target_img_paths[:-val_samples]
val_input_img_paths=input_img_paths[-val_samples:]
val_target_img_paths=target_img_paths[-val_samples:]
#把训练集,验证集分批输入
#instantiate data sequences for each split
train_gen=OxfordPets( batch_size,img_size,train_input_img_paths,train_target_img_paths)
val_gen=OxfordPets(batch_size,img_size,val_input_img_paths,val_target_img_paths)
#训练模型
#加载训练好的权重,直接预测
#model.load_weights(r'D:\9781789138900_Codes\Chapter04\oxford_segmentation0925.h5',by_name=True)
#编译模型,设定优化器(optimizer),损失函数(loss),效果衡量指教(metrics)的类别
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy")
#设定检查点callbacks
callbacks=[keras.callbacks.ModelCheckpoint("oxford_segmentation.h5",save_best_only=True)]
epochs=15
#训练模型
model.fit(train_gen,epochs=epochs,validation_data=val_gen,callbacks=callbacks)
#获取验证数据集的预测图,预测所有验证数据
val_preds=model.predict(val_gen)
#这个函数输出预测图
def display_mask(i):
mask=np.argmax(val_preds[i],axis=-1)
mask=np.expand_dims(mask,axis=-1)
img=PIL.ImageOps.autocontrast(keras.preprocessing.image.array_to_img(mask))
img.show()
#filename=val_input_img_paths[i].split('.')[0]+'_predict.png'
img.save('predict0908.png')
i=10
print("原图")
img1=imgop.open(val_input_img_paths[i])
img1.show()
#display(Image(filename=val_input_img_paths[i]))
print("原屏蔽图:")
img=PIL.ImageOps.autocontrast(load_img(val_target_img_paths[i]))
img.show()
display(img)
print("预测结果:")
display_mask(i)
#note that the model only sees inputs at 150✖150














 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









