









简介
本项目是参加飞桨常规赛:中文场景文字识别(已结束)的项目,项目score为85.87141。
生成的预测文件为work/PaddleOCR中的test2.txt文件
项目任务为识别包含中文文字的街景图片,准确识别图片中的文字
本项目源于https://aistudio.baidu.com/aistudio/projectdetail/681670,在此基础上进行修改
感谢开发者为开源社区做出的贡献
运行代码请点击:https://aistudio.baidu.com/aistudio/projectdetail/1757733
欢迎各位fork,star,以及讨论分享。
本方案在最终测试得到的分数
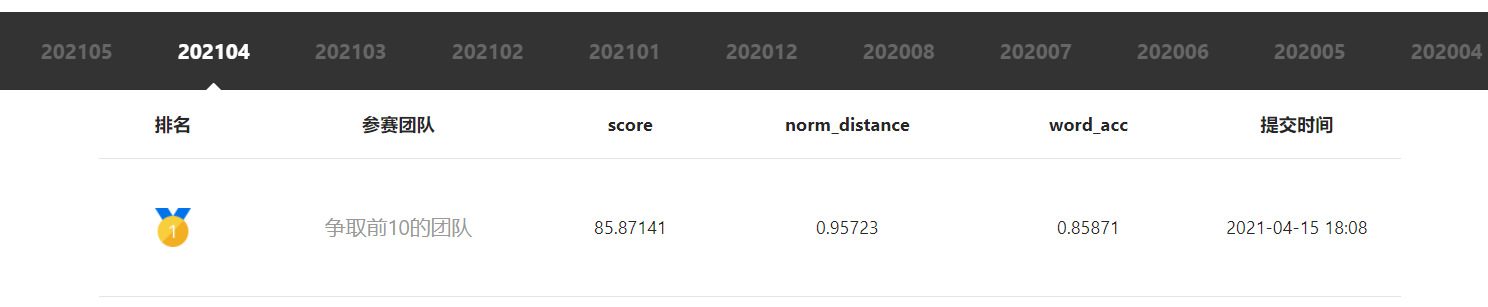
比原作者提供最优的方案略有涨点,并且实现了正确输出结果。
赛题说明
赛题背景
中文场景文字识别技术在人们的日常生活中受到广泛关注,具有丰富的应用场景,如:拍照翻译、图像检索、场景理解等。然而,中文场景中的文字面临着包括光照变化、低分辨率、字体以及排布多样性、中文字符种类多等复杂情况。如何解决上述问题成为一项极具挑战性的任务。
本次飞桨常规赛以 中文场景文字识别 为主题,由2019第二届中国AI+创新创业全国大赛降低难度而来,提供大规模的中文场景文字识别数据,旨在为研究者提供学术交流平台,进一步推动中文场景文字识别算法与技术的突破。
比赛任务
要求选手必须使用飞桨对图像区域中的文字行进行预测,返回文字行的内容。
数据集介绍
本次竞赛数据集共包括33万张图片,其中21万张图片作为训练集,12万张作为测试集。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如下图1所示:

(a) 标注:魅派集成吊顶

(b) 标注:母婴用品连锁
图1
标注文件
平台提供的标注文件为.txt文件格式。样例如下:
| h | w | name | value |
|---|---|---|---|
| 128 | 48 | img_1.jpg | 文本1 |
| 56 | 48 | img_2.jpg | 文本2 |
其中,文件中的四列分别是图片的宽、高、文件名和文字标注。
比赛重点:
准确识别图片的文字,提升准确率
比赛难点:
准确识别并且把输出结果正确输入文档
安装第三方库
将安装目录设置为external-libraries,这样项目重启后安装的库不会消失。
!mkdir /home/aistudio/external-libraries
import sys
sys.path.append('/home/aistudio/external-libraries')
! pip install tqdm paddlepaddle-gpu==1.7.1.post97 -i https://mirror.baidu.com/pypi/simple
! pip install pqi
! pqi use aliyun
! pip install tqdm imgaug lmdb matplotlib opencv-python Pillow python-Levenshtein PyYAML trdg anyconfig # -t /home/aistudio/external-libraries
解压文件
压缩包内含训练集图片、训练集图片信息
import os
os.chdir('/home/aistudio/data/data10879')
! tar -zxf train_img.tar.gz
#! tar -zxf test_img.tar.gz
预处理
-
文件 langconv(language convert),这个文件用来把繁体字转成简体字
-
函数 read_ims_list:读取train.list文件,生成图片的信息字典
-
函数 modify_ch:对标签label进行修改,进行四项操作,分别是“繁体->简体”、“大写->小写”、“删除空格”、“删除符号”。
-
函数 pipeline:调用定义的函数,对训练数据进行初步处理。
from work.langconv import Converter
import codecs
import random
import sys
import os
from os.path import join as pjoin
os.chdir('/home/aistudio')
sys.path.append('/home/aistudio/work')
def read_ims_list(path_ims_list):
"""
读取 train.list 文件
"""
ims_info_dic = {}
with open(path_ims_list, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split(maxsplit=3)
w, h, file, label = parts[0], parts[1], parts[2], parts[3]
ims_info_dic[file] = {'label': label, 'w': int(w)}
return ims_info_dic
def modify_ch(label):
# 繁体 -> 简体
label = Converter("zh-hans").convert(label)
# 大写 -> 小写
label = label.lower()
# 删除空格
label = label.replace(' ', '')
# 删除符号
for ch in label:
if (not '\u4e00' <= ch <= '\u9fff') and (not ch.isalnum()):
label = label.replace(ch, '')
return label
def save_txt(data, file_path):
"""
将一个list的数组写入txt文件里
:param data:
:param file_path:
:return:
"""
if not isinstance(data, list):
data = [data]
with open(file_path, mode='w', encoding='utf8') as f:
f.write('\n'.join(data))
def pipeline(dataset_dir):
path_ims = pjoin(dataset_dir, "train_images")
path_ims_list = pjoin(dataset_dir, "train.list")
path_train_list = pjoin('/home/aistudio/work', "train.txt")
path_test_list = pjoin('/home/aistudio/work', "test.txt")
path_label_list = pjoin('/home/aistudio/work', "dict.txt")
# 读取数据信息
file_info_dic = read_ims_list(path_ims_list)
# 创建 train.txt
class_set = set()
data_list = []
for file, info in file_info_dic.items():
label = info['label']
label = modify_ch(label)
# 异常: 标签为空
if label == '':
continue
for e in label:
class_set.add(e)
data_list.append("{0}\t{1}".format(pjoin('/home/aistudio/',path_ims, file), label))
# 创建 label_list.txt
class_list = list(class_set)
class_list.sort()
print("class num: {0}".format(len(class_list)))
with codecs.open(path_label_list, "w", encoding='utf-8') as label_list:
for id, c in enumerate(class_list):
# label_list.write("{0}\t{1}\n".format(c, id))
label_list.write("{0}\n".format(c))
# 随机切分
random.shuffle(data_list)
val_len = int(len(data_list) * 0.05)
val_list = data_list[-val_len:]
train_list = data_list[:-val_len]
print('训练集数量: {}, 验证集数量: {}'.format(len(train_list),len(val_list)))
save_txt(train_list,path_train_list)
save_txt(val_list,path_test_list)
random.seed(0)
pipeline(dataset_dir="data/data10879")
class num: 3827
训练集数量: 200342, 验证集数量: 10544
os.chdir('/home/aistudio/work/PaddleOCR/')
!pwd
/home/aistudio/work/PaddleOCR
简要介绍方案
思路介绍
使用PaddleOCR库进行训练和预测
个人方案亮点
在现有的数据中进行 fine-tune,并且正确输出结果
具体方案分享–trian
大致思路和步骤:
因为最后的评定标准是准确率,所以优选考虑Resnet,常用的是Resnet34结构,所以Backbone选用Resnet34。在阅读PaddleOCR库资料,有表明CTC比Attention具有优势,
尤其是对长文本识别,因此Head,Loss选用了CTC模块。Optimizer则选用常用的Adam。
总结:
Backbone: Resnet34
Head: CTC
Loss: CTC
Optimizer: Adam
由于PaddleOCR集成度、模块化非常的好,因此可以在work/PaddleOCR/configs/rec/rec_r34_vd_none_bilstm_ctc.yml,选择适合比赛所需要的结构,只需要改相对应的参数。
大致的框架选择完毕,就进行训练,在训练前期学习率可以选择大一点,到后期的学习率要适当的降低,这是一个常用的提分trick。batch_size可以适当的提高,在AI
studio上,我本想用batch_size:256,但是内存爆了,只好相对于的降低一点。batch_size小了,学习率也要相对应降低一点。
特别说明
对于PaddleOCR提供的配置文件rec_r34_vd_none_bilstm_ctc.yml我做出了如下修改
1.将epoch_num改为120
2.将train_batch_size_per_card改为192(因为GPU限制的原因,本来想改为256,但是爆内存了,就选择了192)
3.将test_batch_size_per_card改为128
4.将base_lr改为0.00001
经测试这样能提高score
用https://aistudio.baidu.com/aistudio/projectdetail/681670 作者的预训练权重继续训练,从而得到最优结果。最优预测权重checkpionts放在work/PaddleOCR/output/rec_CRNN_aug_341/best_accuracy。
模型训练
! export PYTHONPATH=$PYTHONPATH:.
ONPATH:.
! python tools/train.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml
2021-05-08 11:49:40,272-INFO: {'Global': {'algorithm': 'CRNN', 'use_gpu': True, 'epoch_num': 120, 'log_smooth_window': 20, 'print_batch_step': 100, 'save_model_dir': 'output/rec_CRNN_aug_341', 'save_epoch_step': 1, 'eval_batch_step': 1800, 'train_batch_size_per_card': 192, 'test_batch_size_per_card': 128, 'image_shape': [3, 32, 256], 'max_text_length': 64, 'character_type': 'ch', 'loss_type': 'ctc', 'reader_yml': './configs/rec/rec_icdar15_reader.yml', 'pretrain_weights': '/home/aistudio/work/PaddleOCR/model/latest', 'checkpoints': None, 'save_inference_dir': '/home/aistudio/work/test', 'character_dict_path': '/home/aistudio/work/dict.txt'}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_resnet_vd,ResNet', 'layers': 34}, 'Head': {'function': 'ppocr.modeling.heads.rec_ctc_head,CTCPredict', 'encoder_type': 'rnn', 'SeqRNN': {'hidden_size': 256}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_ctc_loss,CTCLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 1e-05, 'beta1': 0.9, 'beta2': 0.999}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '/', 'label_file_path': '/home/aistudio/work/train.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'img_set_dir': '/', 'label_file_path': '/home/aistudio/work/test.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'infer_img': '/home/aistudio/work/PaddleOCR/test_images'}}
import ujson error: No module named 'ujson' use json
2021-05-08 11:49:43,523-INFO: places would be ommited when DataLoader is not iterable
W0508 11:49:44.193677 256 device_context.cc:237] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.0, Runtime API Version: 9.0
W0508 11:49:44.197623 256 device_context.cc:245] device: 0, cuDNN Version: 7.3.
2021-05-08 11:49:45,223-INFO: Loading parameters from /home/aistudio/work/PaddleOCR/model/latest...
2021-05-08 11:49:46,298-INFO: Finish initing model from /home/aistudio/work/PaddleOCR/model/latest
I0508 11:49:46.319135 256 parallel_executor.cc:440] The Program will be executed on CUDA using ParallelExecutor, 1 cards are used, so 1 programs are executed in parallel.
I0508 11:49:46.342715 256 build_strategy.cc:365] SeqOnlyAllReduceOps:0, num_trainers:1
I0508 11:49:46.372932 256 parallel_executor.cc:307] Inplace strategy is enabled, when build_strategy.enable_inplace = True
I0508 11:49:46.387321 256 parallel_executor.cc:375] Garbage collection strategy is enabled, when FLAGS_eager_delete_tensor_gb = 0
^C
pid 324 terminated, terminate group 255...
pid 322 terminated, terminate group 255...
把比赛的测试集解压到/home/aistudio/work/PaddleOCR
!unzip -oq /home/aistudio/external-libraries/test_images.zip -d /home/aistudio/work/PaddleOCR
模型预测
pyspark包里有包含re.split()
!pip install pyspark
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Collecting pyspark
[?25l Downloading https://mirrors.aliyun.com/pypi/packages/45/b0/9d6860891ab14a39d4bddf80ba26ce51c2f9dc4805e5c6978ac0472c120a/pyspark-3.1.1.tar.gz (212.3MB)
[K |████████████████████████████████| 212.3MB 10.5MB/s eta 0:00:01 |██████████████▋ | 97.2MB 7.6MB/s eta 0:00:16 |█████████████████████ | 138.8MB 11.9MB/s eta 0:00:07 |███████████████████████▋ | 156.9MB 10.7MB/s eta 0:00:06
[?25hCollecting py4j==0.10.9 (from pyspark)
[?25l Downloading https://mirrors.aliyun.com/pypi/packages/9e/b6/6a4fb90cd235dc8e265a6a2067f2a2c99f0d91787f06aca4bcf7c23f3f80/py4j-0.10.9-py2.py3-none-any.whl (198kB)
[K |████████████████████████████████| 204kB 11.5MB/s eta 0:00:01
[?25hBuilding wheels for collected packages: pyspark
Building wheel for pyspark (setup.py) ... [?25ldone
[?25h Created wheel for pyspark: filename=pyspark-3.1.1-py2.py3-none-any.whl size=212767605 sha256=700ba8bab5aeecc38be58bd68db13bfbc542bb8fef88a340be83ee70e0b5e381
Stored in directory: /home/aistudio/.cache/pip/wheels/a2/ed/29/497d35d1af7c0f79fe21a1f38c2a2beded1c92f3fd3863a6bf
Successfully built pyspark
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.9 pyspark-3.1.1
具体方案分享–test
经过几轮训练,Loss稳定了即可拿来进行预测。原作者输出文档存在2点错误,1.是没有标题。2.预测结果是乱序的。 进行提交的会出现下图错误。

所以要进行必要的修改。对症下药,第一点.没有标题。我们可以在预测结果输出前,先对预测文档进行写入标题的操作。
因此我们先找到执行预测文件:work/PaddleOCR/tools/infer_rec.py。 我们可以看见此文件第96行左右 有f = open('test2.txt',mode='w',encoding='utf8'),即创
建输出文件并授予可输入的权限。因此我们可以在它的下面进行写入标题的操作:f.write('new_name\tvalue\n')
即

这样就解决了第一个错误。
第二个错误,是把预测结果变成有序的。方案有2个:1.是对输入预测图片进行排序后再送入预测。2.是对输出结果的文档进行排序。
我们优选第一个方案,因为难度比较低,也比较符合操作思维。
我们首先要找出输入预测图片的所在代码。我们可以看到99-105行左右是执行了预测操作。
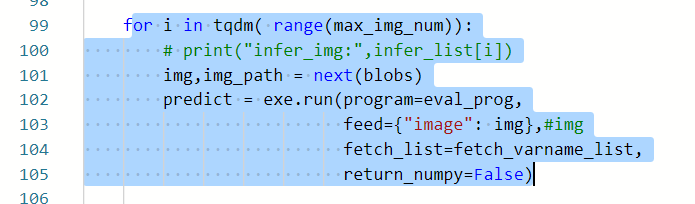
我们要特别注意img,img_path这两个参数。它是读取了blobs的参数,我们又转而去看到85行左右,它读取了执行test操作,总而言之,应该就是进行test操作。
接下来留意87-88行左右

我们可以大致知道它的意思创建了一个List存放了infer_img的路径。这里有个小窍门,就是我们要善用print函数。 我们可以把它输出的List给print出来看看,
输出看了会发现,存放的路径居然和预测结果顺序是一样的,我们也就是找到我们需要修改的地方了。也就是只要我们把存放的路径给整理成有序的,输出的结果
就可以符合比赛要求。
这是我们就可以用sort()函数。因此我们可以再它们后面,增加一行代码:infer_list.sort()。这时候我们可以执行预测文件查看结果,也可以直接进
行print()函数,看存放的路径变得如何了。个人倾向于第二个方案。然后我们发现预测结果顺序变了,变得相对规则了。但是发现从预测结果是
0.jpg xxx
1.jpg xxx
10.jpg xxx
11.jpg xxx
查了资料发现这是 因为数字数据类型是字符串,不是整型。因此我们需要把这些数字的类型把字符串转为整型,可以调用int()函数。
但是我们输出存放路径的List发现,数字之前还有一堆路径:/home/aistudio/work/PaddleOCR/test_images并且还有后缀.jpg
这时候我们可以用split函数进行路径的分割,因为我们要提取中间的数字并进行排序,所以我们要用调用两次split函数,即re.split(),并用’|'进行分开。
最后把无关的路径和后缀删去,并进行整型转换,便可完成我们的任务。
在89行 增加下图的代码

此时我们可以print查看路径是否已经有序排列了,经查看是有序的,便可执行预测文件,从输出结果来看,我们完成了比赛提交的要求。

! python3 tools/infer_rec.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.checkpoints=output/rec_CRNN_aug_341/best_accuracy
2021-04-20 22:24:32,347-INFO: {'Global': {'algorithm': 'CRNN', 'use_gpu': True, 'epoch_num': 120, 'log_smooth_window': 20, 'print_batch_step': 100, 'save_model_dir': 'output/rec_CRNN_aug_341', 'save_epoch_step': 1, 'eval_batch_step': 1800, 'train_batch_size_per_card': 192, 'test_batch_size_per_card': 128, 'image_shape': [3, 32, 256], 'max_text_length': 64, 'character_type': 'ch', 'loss_type': 'ctc', 'reader_yml': './configs/rec/rec_icdar15_reader.yml', 'pretrain_weights': '/home/aistudio/work/PaddleOCR/output/rec_CRNN_aug_341/best_accuracy', 'checkpoints': 'output/rec_CRNN_aug_341/best_accuracy', 'save_inference_dir': '/home/aistudio/work/test', 'character_dict_path': '/home/aistudio/work/dict.txt'}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_resnet_vd,ResNet', 'layers': 34}, 'Head': {'function': 'ppocr.modeling.heads.rec_ctc_head,CTCPredict', 'encoder_type': 'rnn', 'SeqRNN': {'hidden_size': 256}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_ctc_loss,CTCLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 8e-06, 'beta1': 0.9, 'beta2': 0.999}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '/', 'label_file_path': '/home/aistudio/work/train.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'img_set_dir': '/', 'label_file_path': '/home/aistudio/work/test.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'infer_img': '/home/aistudio/work/PaddleOCR/test_images'}}
['ctc_greedy_decoder_0.tmp_0']
W0420 22:24:33.271103 12579 device_context.cc:237] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.0, Runtime API Version: 9.0
W0420 22:24:33.275640 12579 device_context.cc:245] device: 0, cuDNN Version: 7.3.
2021-04-20 22:24:36,085-INFO: Finish initing model from output/rec_CRNN_aug_341/best_accuracy
100%|█████████████████████████████████████| 10000/10000 [05:12<00:00, 32.03it/s]
模型应用结果分析
调优参数优化过程分析: 前期用大的学习率,后期用小的学习率,并且进行相对应的Batch_size调整。
总结
这是第一次在百度AI studio完整的独立完成比赛,幸运的是获得较好的名次。让我对OCR这一块有了新的认识,也对百度飞桨框架有了初步的认识。
在这里要感谢百度飞桨提供训练平台,提供baseline以及优秀的方案供大家进行学习。在这次比赛,我也学到了很多东西,代码能力也进步了一点点。希望百度飞桨可以做的越来越好。
AIStudio提供了AI Studio为选手提供了免费 GPU Tesla V100算力。 对于硬件资源匮乏的同学来说,这是一个非常棒的平台。
最后也期待有更多优秀的作者可以开源他们代码给大家学习。
改进的方向:
1. 最简单的操作把backbone换成resnet50,resnet101及以上的,更深层次的网络,准确率理论上会更高。
2. 因为本次比赛预测图片的结果文字不算太长,CTC模块可以尝试换成Attention,可能效果会好一点。
3.也可以尝试重新把数据进行数据增强,加标签平滑。
4.可以尝试用模型融合
飞桨使用体验以及给其他选手学习飞桨的建议
这是第一次尝试用飞桨框架完成比赛,平常都是用Pytorch比较多,刚开始接触会有点不习惯,因为它有些细微的文件的差异。并且有少部分执行命令和常用的Linux命令不太一样,需要注意和学习基本操作。但不得不说飞桨框架下的包还是很完善的,比如PaddleOCR和PaddleDetection。只需要修改小量参数便可改变网络结构,对于新手来说是非常友好的。
所以想给选手学习飞桨的建议:如果是初学者接触飞桨框架,建议去官网学习相对应的框架简单的执行命令。官方网站:https://www.paddlepaddle.org.cn/tutorials/projectdetail/695184
如果是想用PaddleOCR库的可以去这里进行相关的学习:https://www.paddlepaddle.org.cn/tutorials/projectdetail/695184
如果是想用PaddleDetection库的可以去这里进行相关的学习:https://www.paddlepaddle.org.cn/tutorials/projectdetail/1499121
想了解更多的库可以去官方网站进行更多的学习:https://www.paddlepaddle.org.cn/tutorials/projectdetail/695184
参考资料
PaddleOCR官方资料库
官网链接: https://www.paddlepaddle.org.cn/tutorials/projectdetail/695184
GitHub: https://github.com/PaddlePaddle/PaddleOCR
优秀项目: https://aistudio.baidu.com/aistudio/projectdetail/681670















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









