






有网友说想看看三调数据以及二调三调数据的变化,我这边前段时间分享的【数据】全国各省耕地与人均耕地,其中有个pdf版本的各省三调主要数据公开。但是对于数据研究的网友还是想要表格数据,今天小编就再花点时间,整理一调、二调、三调全国一级地类的数据以及变化给大家,文末自行领取。
1、数据整理过程
之前的数据是别人整理的31个省市区的公报数据,是PDF版本。我将其转成了word版本,其中word数据又不是很规则。

小编对于这种数据也是很头痛,结构化数据好整理,不成结构的数据需要先做处理。于是先将不规则的word版本三调公报数据经过我的整理,形成了64个段落,即一个省(31个加一个全国)后面接三调公开数据的段落。

分析word还有点问题,python-docx读取段落文本的时候,并不能读取段落序号。
需写两个vba将段落序号选择之后再将其转化为段落正文。选择vb代码、将序号转段落文字vb代码:
Sub SelectAllNumberings()
Dim shp As InlineShape
For Each shp In ActiveDocument.InlineShapes
shp.LockAspectRatio = msoFalse
shp.Width = CentimetersToPoints(1)
shp.Height = CentimetersToPoints(0.5)
Next shp
End SubSub xuhaototext()
Dim kgslist As List
For Each kgslist In ActiveDocument.Lists
kgslist.ConvertNumbersToText
Next
End Sub接下来就是提取数据,代码如下。
'''
提取word中的三调数据各类用地。
'''
from docx import Document
import re
import pandas as pd
word_file='全国31个省市段落格式.docx'
doc=Document(word_file)
duanluos=doc.paragraphs
# yy=duanluos[1].text
#段落处理成字典
def text_dict(x):
dict={}
pattern1 = r"一)(.*?)。"
matches1 = re.findall(pattern1, x)
if matches1:
dict['一']=matches1[0]
else:
dict['一']=''
pattern2 = r"二)(.*?)。"
matches2 = re.findall(pattern2, x)
if matches2:
dict['二']=matches2[0]
else:
dict['二']=''
pattern3 = r"三)(.*?)。"
matches3 = re.findall(pattern3, x)
if matches3:
dict['三']=matches3[0]
else:
dict['三']=''
pattern4 = r"四)(.*?)。"
matches4 = re.findall(pattern4, x)
if matches4:
dict['四']=matches4[0]
else:
dict['四']=''
pattern5 = r"五)(.*?)。"
matches5 = re.findall(pattern5, x)
if matches5:
dict['五']=matches5[0]
else:
dict['五']=''
pattern6 = r"六)(.*?)。"
matches6 = re.findall(pattern6, x)
if matches6:
dict['六']=matches6[0]
else:
dict['六']=''
pattern7 = r"七)(.*?)。"
matches7 = re.findall(pattern7, x)
if matches7:
dict['七']=matches7[0]
else:
dict['七']=''
pattern8= r"八)(.*?)。"
matches8 = re.findall(pattern8, x)
if matches8:
dict['八'] = matches8[0]
else:
dict['八'] = ''
return dict
def text_dict1(x):
dict={}
pattern1 = r"一(.*?)。"
matches1 = re.findall(pattern1, x)
if matches1:
dict['一']=matches1[0]
else:
dict['一']=''
pattern2 = r"二(.*?)。"
matches2 = re.findall(pattern2, x)
if matches2:
dict['二']=matches2[0]
else:
dict['二']=''
pattern3 = r"三(.*?)。"
matches3 = re.findall(pattern3, x)
if matches3:
dict['三']=matches3[0]
else:
dict['三']=''
pattern4 = r"四(.*?)。"
matches4 = re.findall(pattern4, x)
if matches4:
dict['四']=matches4[0]
else:
dict['四']=''
pattern5 = r"五(.*?)。"
matches5 = re.findall(pattern5, x)
if matches5:
dict['五']=matches5[0]
else:
dict['五']=''
pattern6 = r"六(.*?)。"
matches6 = re.findall(pattern6, x)
if matches6:
dict['六']=matches6[0]
else:
dict['六']=''
pattern7 = r"七(.*?)。"
matches7 = re.findall(pattern7, x)
if matches7:
dict['七']=matches7[0]
else:
dict['七']=''
pattern8= r"八(.*?)。"
matches8 = re.findall(pattern8, x)
if matches8:
dict['八'] = matches8[0]
else:
dict['八'] = ''
return dict
landtypes=['地区','耕地','园地','林地','草地','湿地','城镇村及工矿用地','交通运输用地','水域及水利设施用地']
data=[]
for i in range(len(duanluos)//2):
j=i*2
k=i*2+1
if k in [1,7,11,23,25,27,45,49,51,53]:
qy=duanluos[j].text
ba=text_dict(duanluos[k].text)
data.append([qy,ba['一'],ba['二'],ba['三'],ba['四'],ba['五'],ba['六'],ba['七'],ba['八']])
else:
qy = duanluos[j].text
ba = text_dict1(duanluos[k].text)
data.append([qy, ba['一'], ba['二'], ba['三'], ba['四'], ba['五'], ba['六'], ba['七'], ba['八']])
df=pd.DataFrame(data,columns=landtypes)
df.to_excel('三调.xlsx', index=False)用代码生成如下excel表格:

2、三调数据整理
由于一调、二调的数据都是平方千米为单位,还得手动整理下三调的表格。最终得到下面的表格。公报数据有以下问题:上海市没有草地,江西的湿地跟水域及水利设施用地是一起统计的,还有土地总面积这块,黑龙江省八大类用地之和比黑龙江省行政区域大1万6千多平方千米。
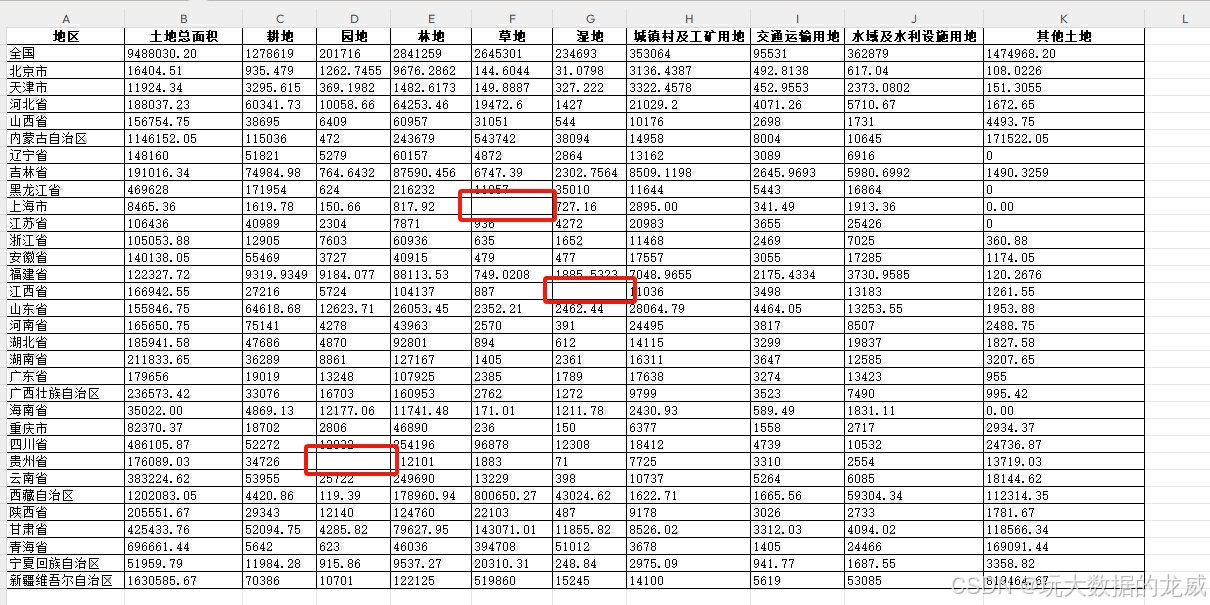
用各省公报的数据汇总与各省行政区域进行比对,如果面积超过行政边界,按照汇总数据作为土地总面积,反之用行政边界面积,其中其他土地用行政边界减去八大类用地之和。
然后与二调数据进行比对生成二调三调大类用地变化表格。
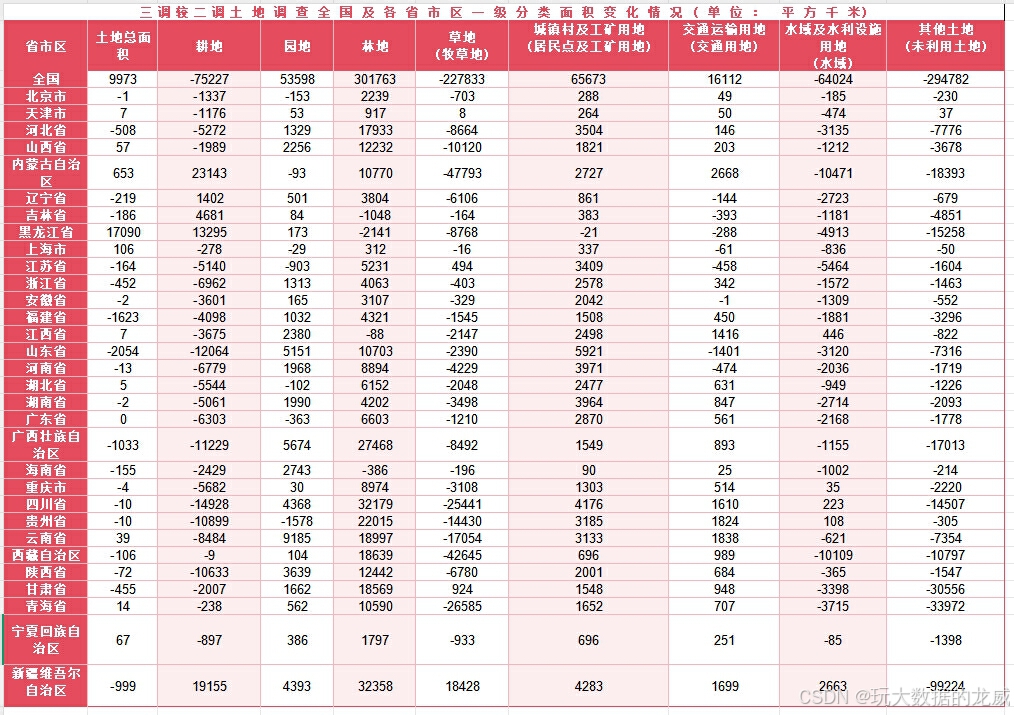
3、数据分享
数据都整理成excel表格,感兴趣的自行下载,整理数据不容易,帮忙点赞分享加关注。


















 169万+
169万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









