







本文首发于“Shopee技术团队”。
1. 背景
随着项目不断深入迭代,业务逻辑以及用户场景日渐复杂,补充和维护单元测试维护的成本也变得越来越高。测试覆盖质量通过测试用例评审或者人工 Code Review 的方式费时费力,单凭多方沟通和经验累积的方法,往往不够准确,也难以避免开发人员存在在代码上线前“夹带私货”的场景,并且没有量化的、直观的客观数据来支撑。
为了在有限的时间及人力成本内保证项目质量,实现对项目质量的精细化管理,我们研发了 Finder —— 全栈代码测试覆盖率及用例发现系统(下文简称 Finder),通过精确化的数据量化代码质量,从而实现精准化测试。本文将介绍 Finder 的总体架构,以及它作为质量保障体系中的重要一环,如何在项目中实现精确化测试。
2. Finder 项目介绍
Finder 主要分为两个模块,一个是测试过程中对代码测试覆盖率进行收集与统计,一个是分析代码和用例的映射关系,精准确定回归测试范围。
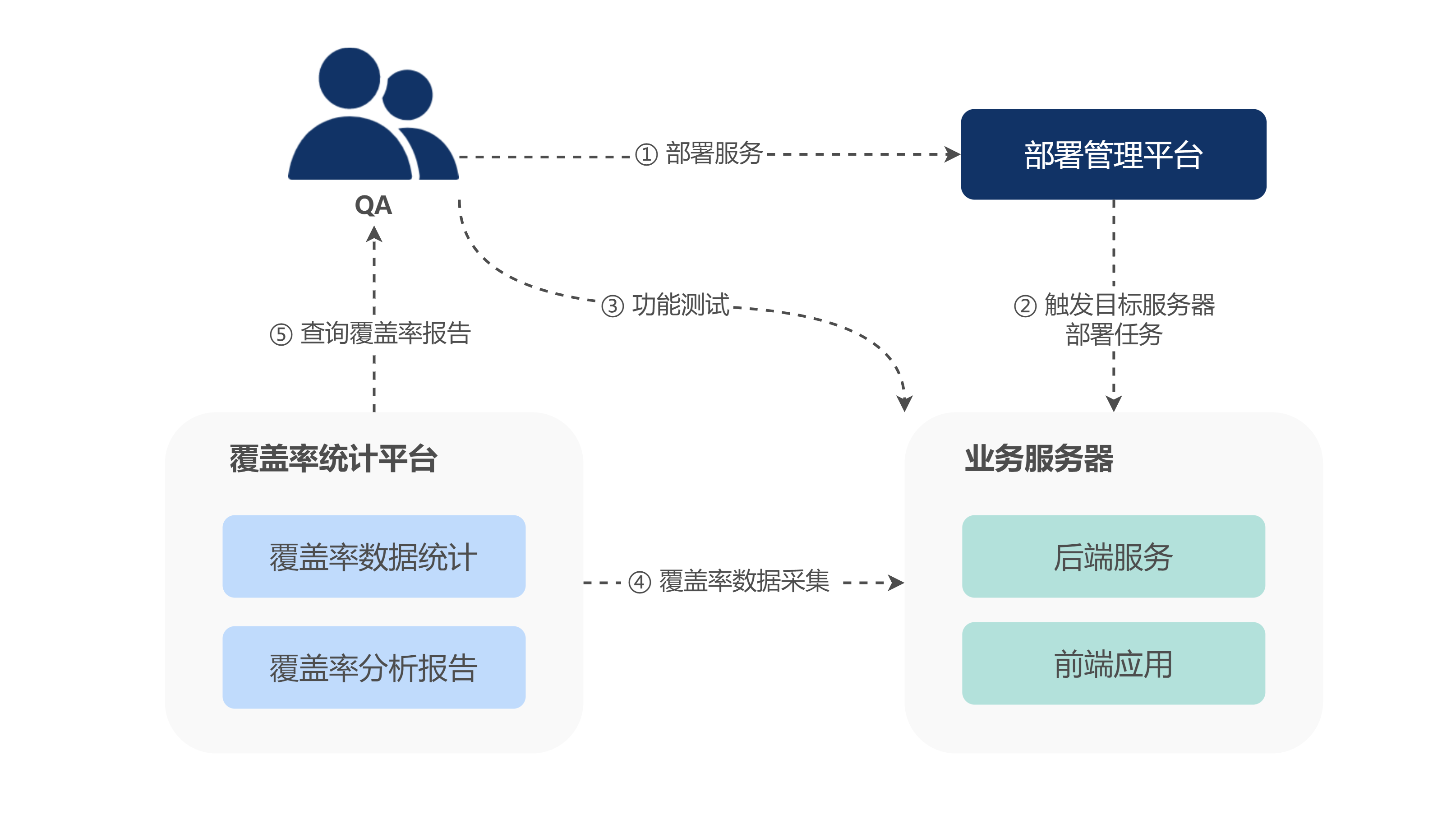
代码测试覆盖率统计模块,能够满足多环境、多需求、多服务的复杂测试场景,实时收集测试过程中的覆盖率信息,并生成覆盖率统计报告;其支持多端语言接入(Web、React Native、Golang),实现前后端项目全覆盖,打通整体研发流程。
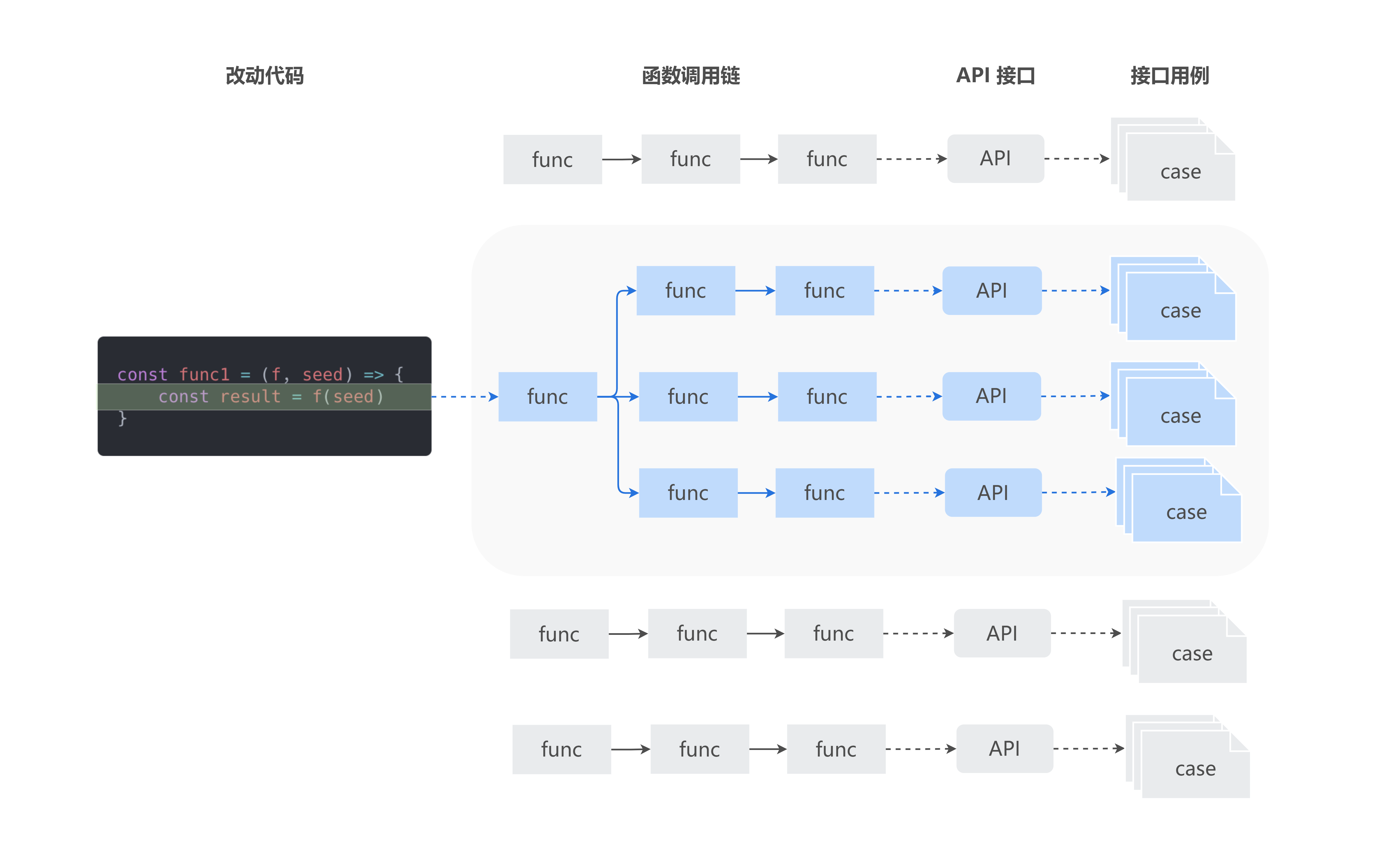
相关用例发现模块,针对变动的代码分析函数调用关系,追溯完整的调用关系链路,标记出所影响的 API 接口及相关用例,确定测试回归范围。
3. 架构设计
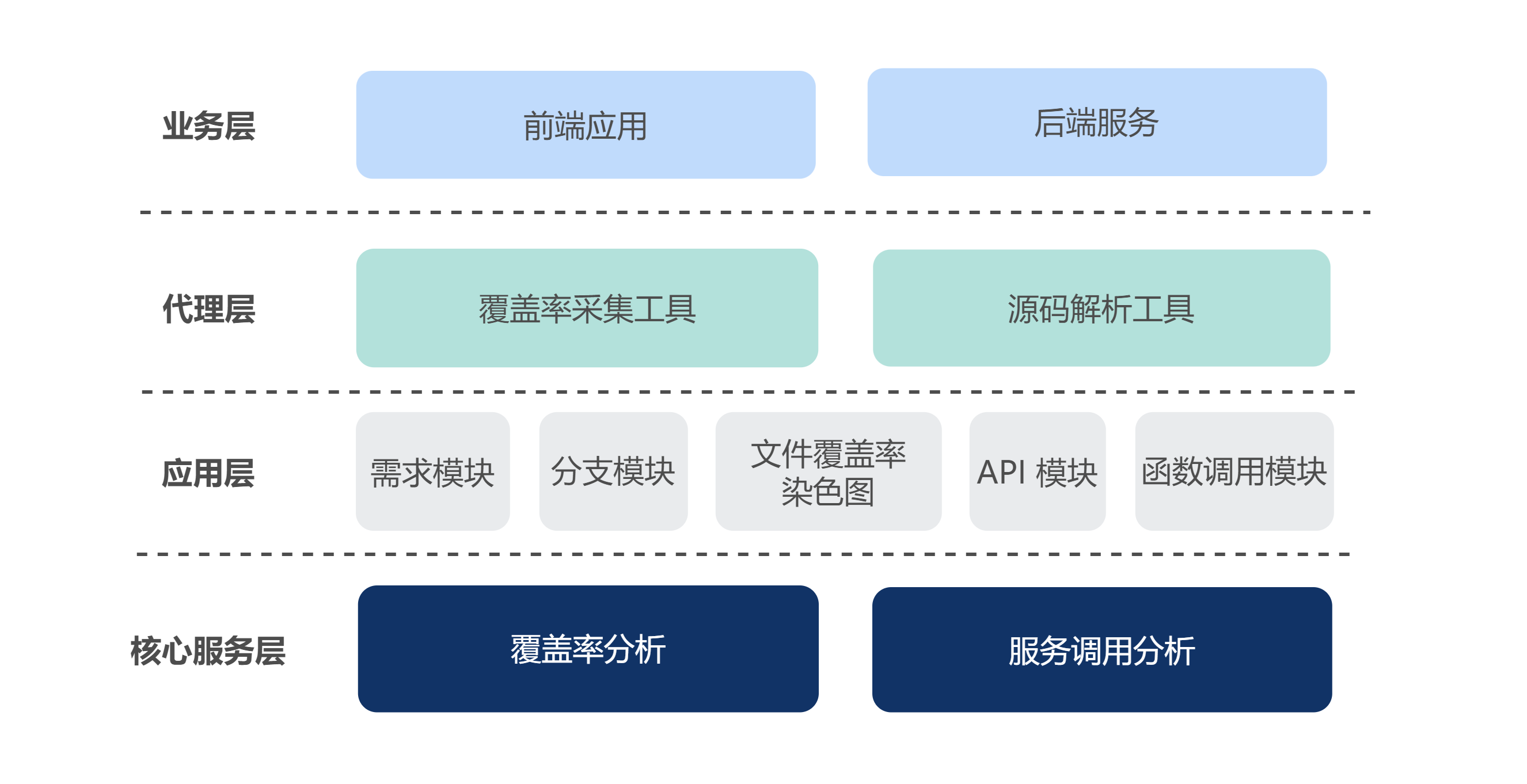
Finder 分为代理层、应用层、核心服务层三个模块:
- 代理层 Finder Agent,负责前期数据采集的工作,包括编译阶段的代码插桩、覆盖率数据的采集、解析源码函数调用关系信息等;
- 应用层 Finder Platform,包含需求信息管理、分支信息管理、单文件覆盖率染色图展示、API 信息展示、测试用例关联、函数调用链展示等页面模块;
- 核心服务层 Finder Server,其中,覆盖率分析和服务调用分析是最主要的两个模块:
- 覆盖率分析,对收集到的覆盖率数据进行数据聚合、差异增量分析、数据修正等操作;
- 服务调用分析,将源码解析工具传输来的数据进行数据结构转换后,完成调用拓扑图生成、API 信息关联、测试用例发现等操作。
在前期完成数据采集的接入工作后,测试人员无需额外操作,正常进行业务测试,测试完成后可以在可视化平台中查看覆盖率数据、相关测试用例等信息。
4. 实现方案
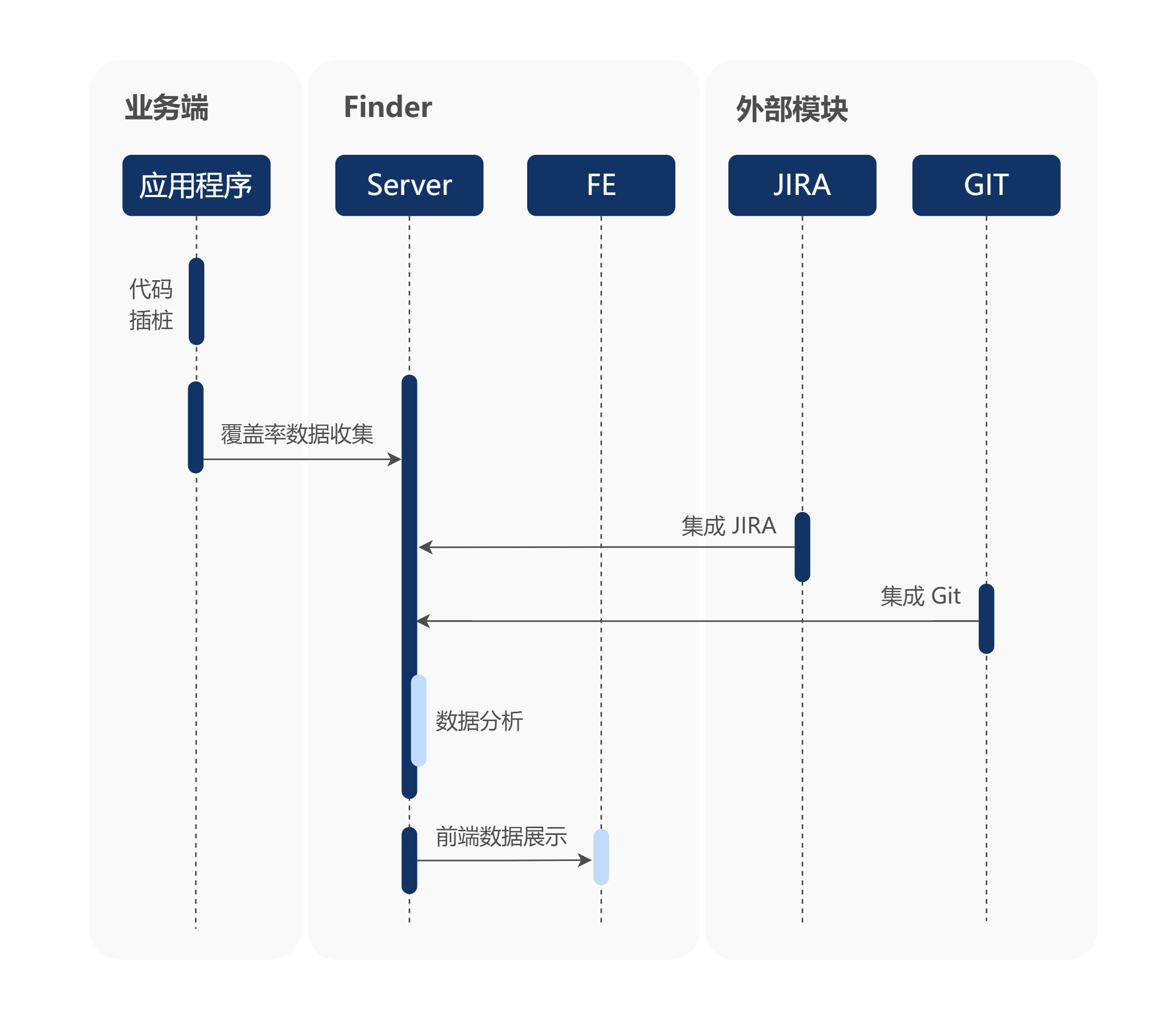
4.1 代码测试覆盖率模块
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









