







本文首发于“Shopee技术团队”
摘要
针对客户端开发的“终生之敌”——卡顿和 ANR 问题,本文将深入剖析系统消息队列机制和常见的卡顿与 ANR 成因,并介绍监控工具 LooperMonitor 如何借助多维分析平台 MDAP 的智能聚合和可视化看板,为业务方提供更精准、易用的分析能力。
这是 MDAP 系列的第三篇文章,前文回顾:
前言
卡顿和 ANR,这是一个所有客户端开发同学都十分关注的话题,也是一个无法绕过的话题。
卡顿的表现是 App 出现丢帧、滑动不流畅、用户的触摸事件响应慢;当发生非常严重的卡顿时,App 甚至可能会弹出 Application not responding 的弹窗,提示用户当前 App 无响应。
卡顿和 ANR 除了会影响用户的使用体验外,对于电商平台来说,在订单高峰期更是会直接影响成交量,导致实际的收入损失。可以说卡顿与 ANR 是客户端开发同学的终生之敌。
但是卡顿和 ANR 问题的分析与解决又具有一定的难度,尤其是 ANR。主要原因是 ANR 是主线程繁忙导致关键的系统消息不能及时执行而触发的,导致主线程繁忙的原因很多,同时系统对 ANR 的认定阈值又比较久,最低也是 5s 起步,在这段时间内,有可能出现了设备 CPU 资源紧张或主线程执行了一些耗时消息的场景,这些场景都有可能是“导致雪崩发生的那几片雪花”。
目前业内主流的监控 SDK,其基本思路都是监听 ANR 信号,并在 ANR 发生现场抓取线程堆栈和系统 ANR 日志,此时的堆栈抓取是一种事后策略,除了一些非常明显的比如线程死锁或者当前正好存在异常耗时的业务逻辑外,对更隐晦和复杂的原因就无能为力了,这种“事后策略”往往导致上报的 ANR 数据里充斥着大量的“无效堆栈”。比如经典的 MessageQueue.nativePollOnce:

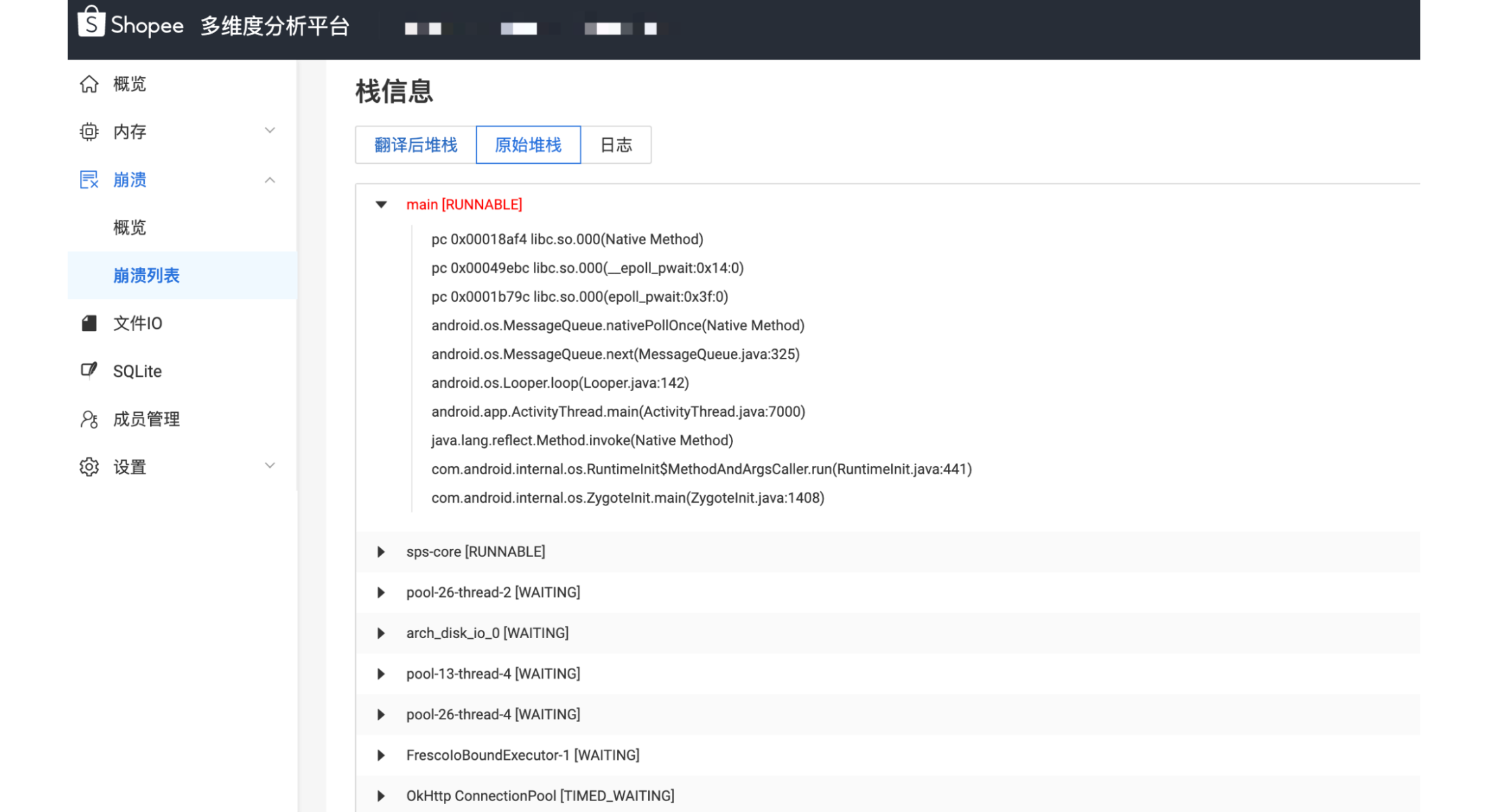
大量堆栈都聚合到 MessageQueue.nativePollOnce 这里了,难道是因为主线程调用 nativePollOnce 在 jni 层一直阻塞没有被唤醒吗?如果只借助这么一份堆栈数据的话,我们无法找到分析思路,这些 ANR 问题是很难被解决的。
为了解决这些痛点,ShopeeFood 团队和 Shopee Engineering Infrastructure 团队通过深入研究系统消息队列机制和常见的卡顿与 ANR 成因,实现了一套新的监控工具 LooperMonitor,作为 APM-SDK 基础能力的一部分,与卡顿和 ANR 上报结合,借助多维分析平台 MDAP(Multi-dimension-analysis-platform)的智能聚合和可视化看板,旨在为业务方提供更精准和易用的分析能力。
1. 卡顿与 ANR 的产生原理
在正式介绍 LooperMonitor 方案之前,我们有必要搞清楚为什么传统方案抓取的 ANR 现场堆栈会不准?要解答这个问题,需要先弄清楚卡顿和 ANR 是如何产生的。
我们知道,Android 的应用层是基于 Looper+MessageQueue 的事件循环模型运作起来的。
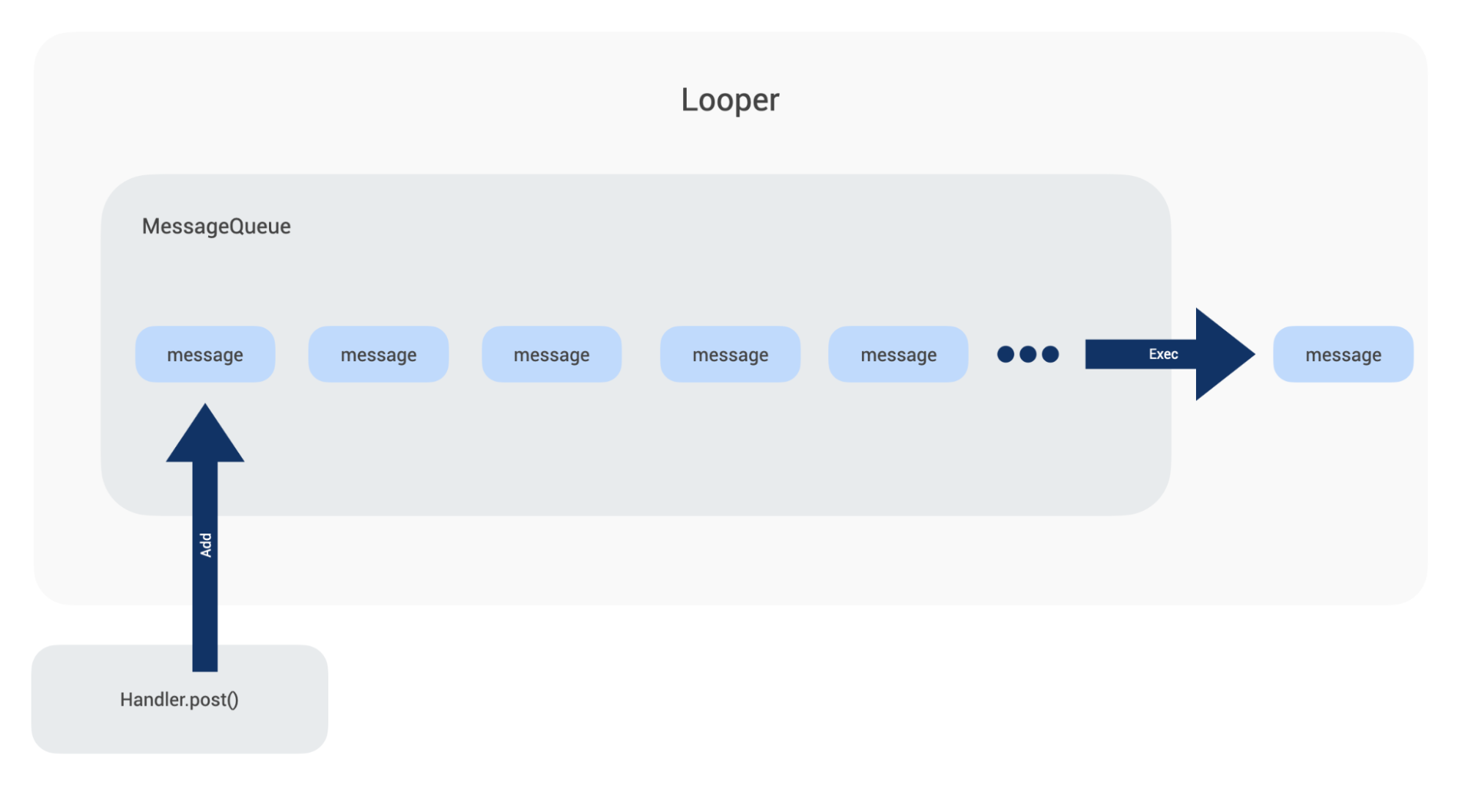
Looper 是一个消息轮询器,它不停地在 MessageQueue 中取出消息并执行。
这里的消息,包括 UI 绘制消息、系统四大组件的调度消息、业务自己通过 Handler 构建的消息等。
里面负责 UI 绘制的是 doFrame 的消息。它是由 Choreographer 通过申请和监听硬件层的 vsync 垂直同步信号后,将 UI 绘制任务包装成一个 doFrame 的消息,在合适的帧绘制时间点将消息抛到主线程消息队列去执行的。
一个 doFrame 消息内部有五个 callback 队列,比较重要的是 input_queue、animation_queue 和 traversal_queue。它们分别处理触摸事件、动画事件、UI 绘制事件。

当一个 doFrame 消息被执行时,上述三个队列的事件会被执行,我们认为 App 响应了一次用户的触摸,同时 UI 更新了一帧,完成了一次交互。
当一个 doFrame 消息执行完成后,会通知 Choreographer 申请下一次的 vsync 信号。此时 UI 绘制任务便被串起来了,如下图:
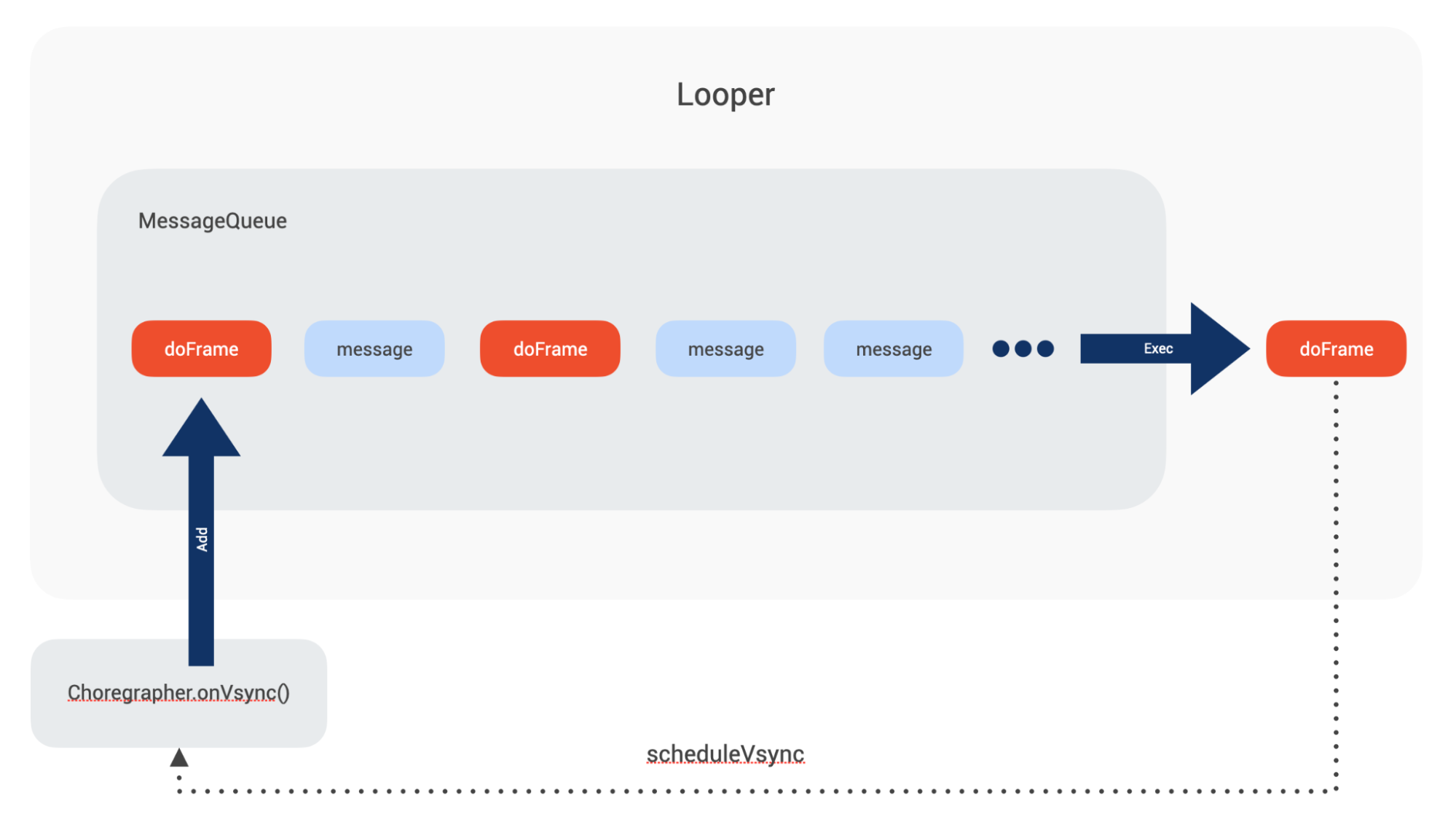
如果在每一个 vsync 间隔都能执行完一个新的 doFrame 消息的话,此时设备是满帧运行的。

但是有种情况会导致下一个 doFrame 消息不能在一个 vsync 间隔内被执行,比如当前的 doFrame 消息正好超出了 vsync 间隔,导致下一个 vsync 不能及时申请;或者 doFrame 消息前,主线程 Looper 被其他耗时任务占据了。

一旦 doFrame 不能及时被执行,表现在体验上,就是设备绘制丢了一帧。当这个间隔越大,丢帧表现就越明显,App 就越卡顿。
对于 ANR 来说,其原理是类似的。我们拿系统创建 Service 举例,在目标 Service 创建过程中会调用到 realStartServiceLocked(),在 realStartServiceLocked() 内部最终会调用到 ActiveServices 的 scheduleServiceTimeoutLocked 方法,系统会在此时埋下“炸弹”,同时依据服务是前台还是后台的不同,炸弹会按照不同的时间引爆,这里前台服务是 20s。
ActiveServices.java
void scheduleServiceTimeoutLocked(ProcessRecord proc) {
……
Message msg = mAm.mHandler.obtainMessage(
ActivityManagerService.SERVICE_TIMEOUT_MSG);
msg.obj = proc;
mAm.mHandler.sendMessageDelayed(msg,
proc.execServicesFg ? SERVICE_TIMEOUT : SERVICE_BACKGROUND_TIMEOUT);
}
用图表示如下:
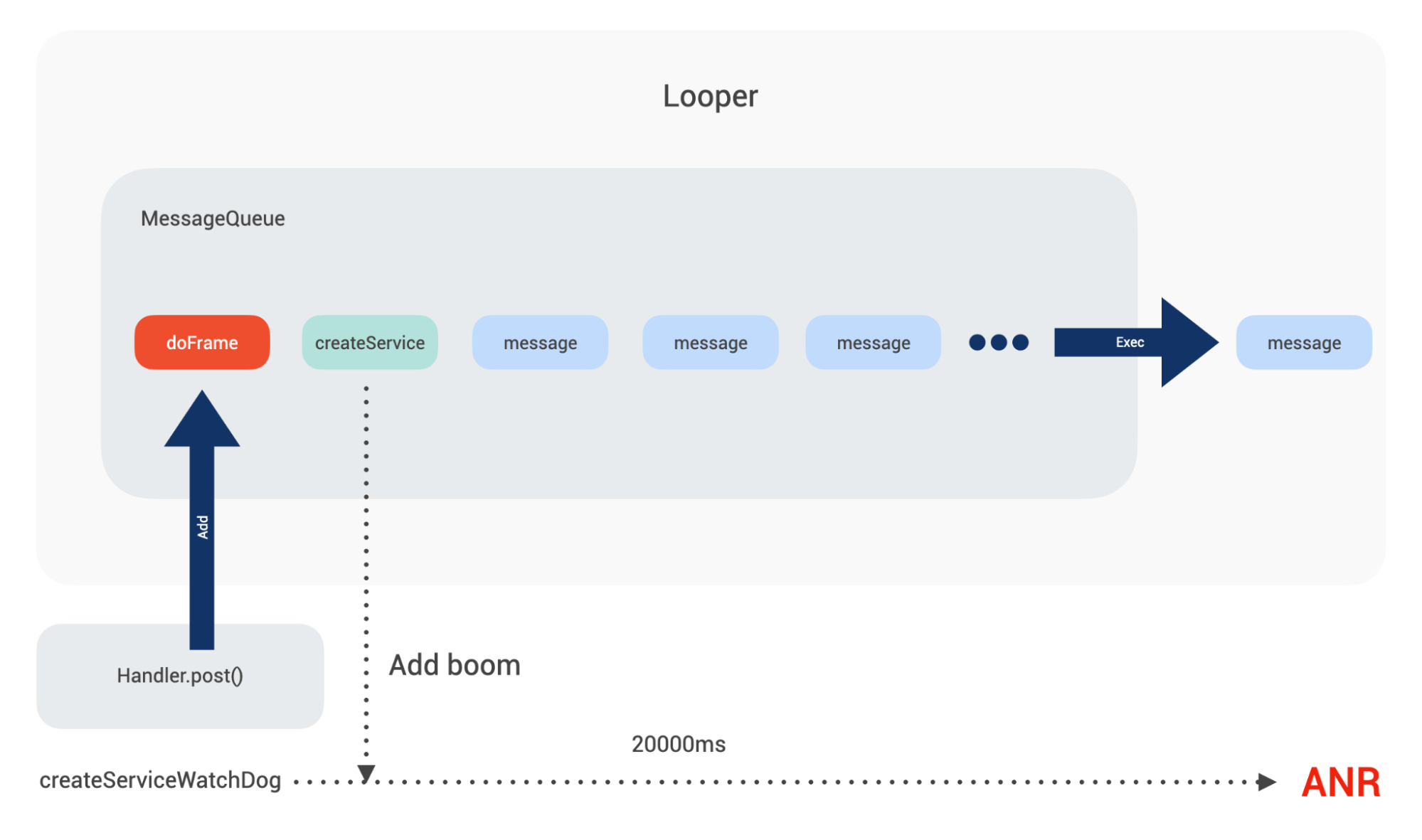
通过一系列的系统调用,最终 ActivityThread 的内部类 ActivityThread$H 中会接收到一条 CREATE_SERVICE 消息。当 CREATE_SERVICE 被执行时,service 实例会被创建,并且会回调其 onCreate() 方法,在 onCreate() 被调用前,会通知 ActiveServices 取消掉这条超时引爆的信息。
ActiveServices.java
private void serviceDoneExecutingLocked(ServiceRecord r, boolean inDestroying,
boolean finishing) {
……
mAm.mHandler.removeMessages(ActivityManagerService.SERVICE_TIMEOUT_MSG, r.app);
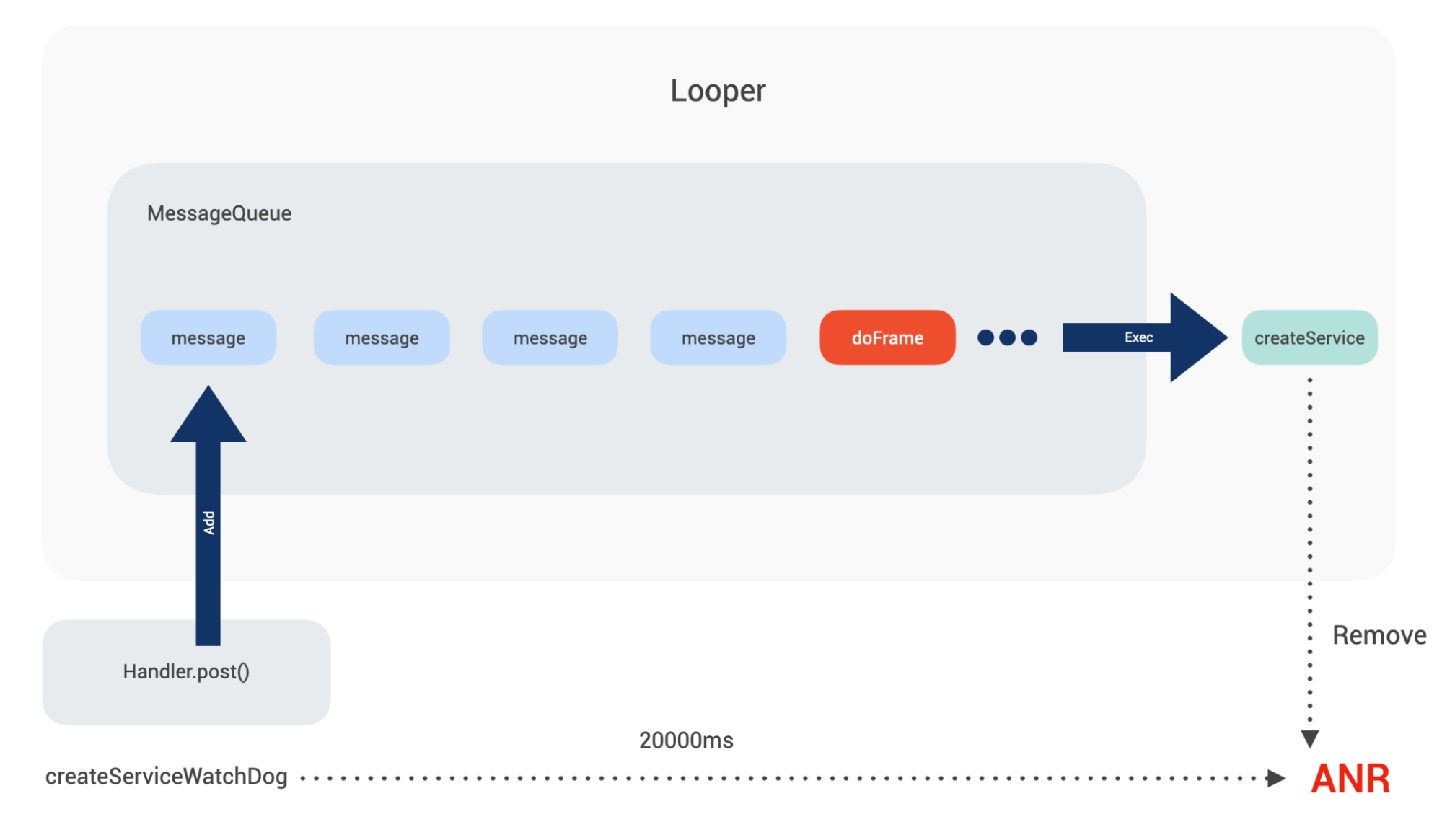
如果因为种种原因导致本次 CREATE_SERVICE 不能在 20s 内得到执行,SERVICE_TIMEOUT_MSG 消息便会被执行,此时便会产生 ANR。
系统对不同的事件,其“容忍度” 和 ANR 信息引爆后的表现也有所不同,具体定义见表:
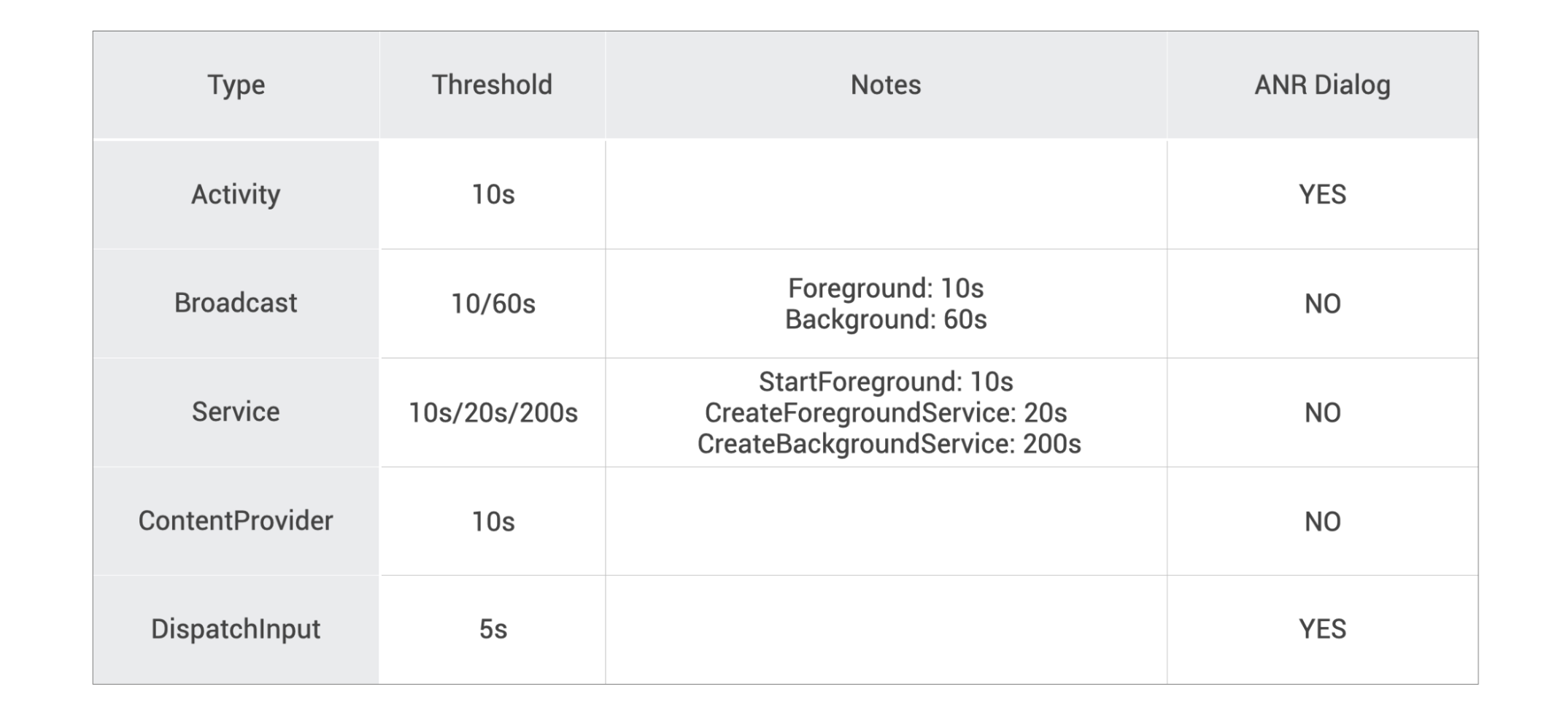
总结一下:
卡顿产生的原因是 doFrame 的消息无法在 vsync 的时间间隔内完成执行,而 ANR 是因为关键的系统消息,或者 Input 事件无法在系统定义的超时阈值内完成执行。
从本质上来说,它们是同一个问题的两种表现,只是严重程度不同而已。当设备发生了 ANR 时,往往也发生了非常严重的卡顿。
2. 为什么堆栈不准?
从前文分析可知,卡顿和 ANR 的产生原因都是特定类型消息在指定阈值内没有得到及时执行。这个阈值的时间有长有短。
对于卡顿监控,我们的阈值间隔不会很长,按业务场景和产品复杂度可能会有所不同,但一般可能在几百毫秒左右。ANR 的监控阈值更长,发生用户可感知的 ANR, 最短也有 5s,最长 10s。
当监控到卡顿和 ANR 时,其实意味着过去的几百毫秒,5s,10s 的主线程消息队列有异常的耗时任务出现,如果此时抓取堆栈,只意味着我们抓取到了卡顿和 ANR 现场的堆栈数据。
对于卡顿来说,几百毫秒的间隔不算很长,本次抓取的堆栈有较高概率可能可以命中异常耗时任务的堆栈,但也只是 “可能”。
对于 ANR 就没有那么容易命中了,毕竟过去了 5s,10s,主线程执行过的任务太多了,在这 5s 和 10s 内,每一个耗时任务,都有可能导致关键性系统消息无法及时被执行。如果在 ANR 信号发生时去抓取堆栈,大概率会将这些场景 miss 掉。
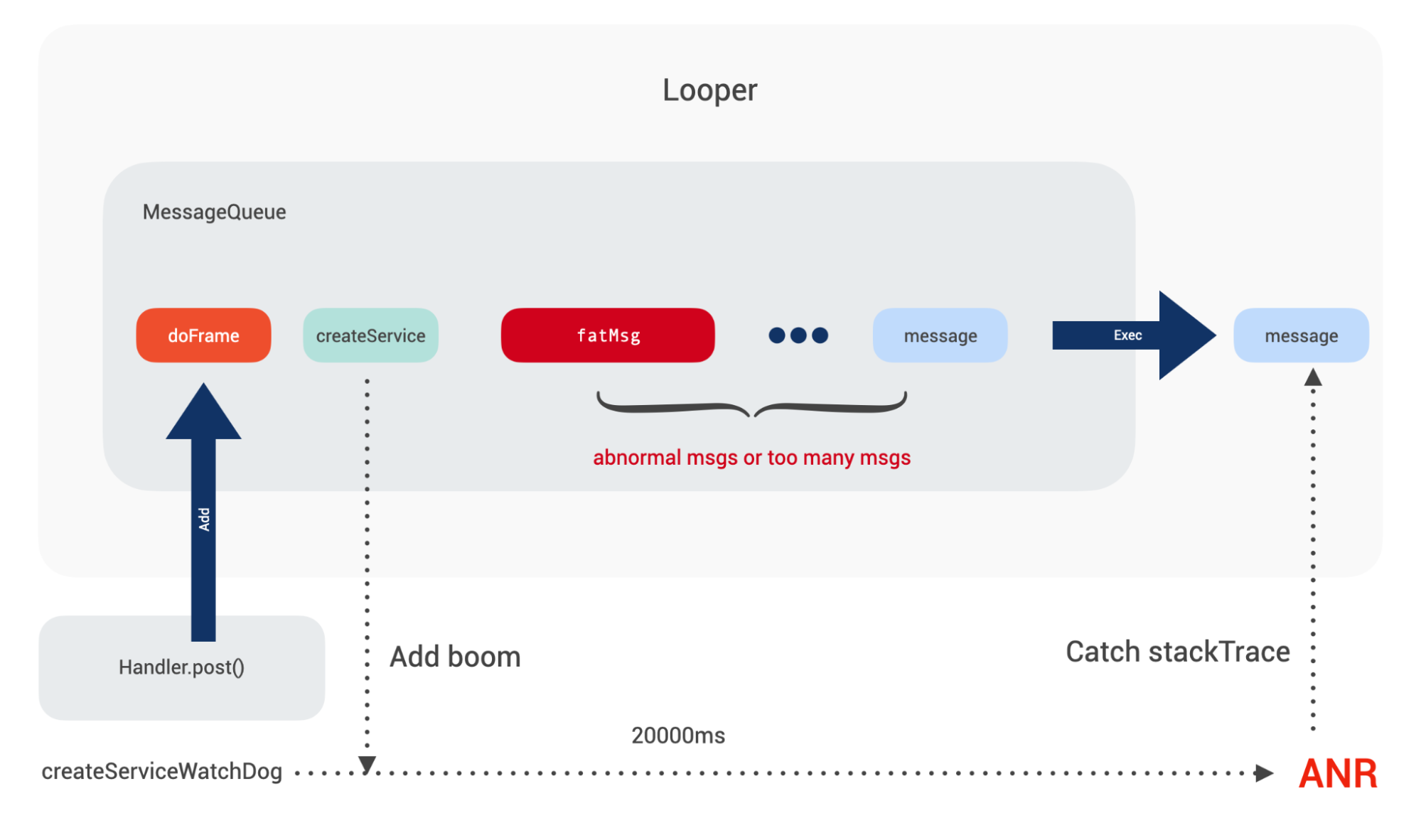
ANR 的信号是异步产生的,在接收到 ANR 信号时采集堆栈,除了有可能采集到当前消息内执行的业务堆栈外,也有可能采集到主线程 MesageQueue 正在取消息的“过程”,这个取下一条消息的方法 MessageQueue.next() 调用得非常频繁,所以命中概率很高,这也是为什么很多 ANR 上报里最终都命中了这个堆栈。
知道了堆栈不准的原因后,解决它也便有了一个很清晰的思路。
3. MDAP-LooperMonitor
其实通过上述分析可以看到,导致 ANR 和卡顿产生的原因是主线程 Looper 中有异常消息。
同时,有提示的可感知 ANR 最长耗时是 10s,如果可以通过一种机制,记录主线程过去 10s 内所有消息的调度历史,保存业务方需要的关键数据,并处理好性能和内存占用,在问题发生时,上报监控阈值内的调度数据:
- 比如在卡顿时,上报过去 500ms(可在配置平台灵活调整)的调度数据;
- 在 ANR 发生时,上报过去 10s 和尚未调度的 Pending 消息。
这样对于开发者来说,就等同于拥有了“看穿过去和未来”的能力,应该就可以解决大部分卡顿和 ANR 问题了。
MDAP 的 LooperMonitor 便是基于此思路的一种监控方案,我们在内部也做了大量技术优化来确保方案落地,比如寻找性能更优的监控入口,使用对象复用技术减少 GC 压力,使用多实例单线程模型减少同步开销,使用小消息聚合和滚动淘汰策略减少内存占用等,详见下文。
3.1 监控入口
找到主线程 Looper 的调度的入口是本次监控方案的核心,如果可以在调度的起止点插入我们想要的代码,便可以获取到当前 msg 的执行耗时。
Looper 的源码只摘取关键信息如下:
for (;;) {
Message msg = queue.next(); // might block
...
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









