






反向传播算法学习笔记与记录
在看完B站刘二大人反向传播的视频课后,对梯度下降算法和深度学习的理解又增强了,在此再记录一下自己的理解
首先在学习反向传播时,有几个概念需要知道
-
反向传播算法只是能得到误差,而迭代求权重的最优值只能通过梯度下降算法
-
反向传播算法分为两个步骤,即“正向传播求损失”和“反向传播传回误差”。—即整个学习步骤是 1.计算损失值 2.进行反向传播 3.使用梯度下降算法更新权重
-
tensor类型是PyTorch的一种数据类型,其包含data和grad两种结构,且这两种结构也是tensor类型,有点像结构体里面的指针一样,需要引用。
-
“数值之间不仅仅只是计算,更重要的是生成了计算图”,只有理解了计算图才能知道整个反向传播是怎么实现的
通过线性函数来模拟反向传播的过程

假设每学习1小时成绩能提高2分,2小时能提高4分,通过求线性模型来求在学习4小时的时候能提高多少分
1.预测模型为y = w*x的线性模
def forword(x):
return x * w
2.求损失值loss
'''计算MSE(平均平方误差)'''
def loss(x,y):
y_pred = forword(x)
return (y - y_pred)*(y - y_pred)
3.将w设定初始权重为1,且由于需要计算w的梯度所以需要开启w变量的梯度
w = torch.tensor([1.0]) #设定权重w的初值为1,
w.requires_grad = True
4.画出计算图

5.核心代码部分
for epoch in range(100): #循环100次
for x,y in zip(x_data,y_data):
l = loss(x,y) #生成计算图,且l是一个张量,求loss的正向计算
l.backward() #进行反向计算,在调用l.backward()之后,w.grad由之前的none变成tensor
print('\tgrad:', x,y,w.grad.item())
w.data = w.data - 0.01*w.grad.data #由于w.grad是tensor类型,所以在进行递减时,需要对w里面的数据进行计算,而不是grad
w.grad.data.zero_()#在每次更新之后返回的w误差都需要归零,以免在进行下一次返回时返回的是误差的和
print('progress', epoch,l.item())
总代码
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
'''由于要进行反向传播来计算梯度从而进行梯度下降算法求最小权重,所以需要设定数据为tensor
类型来生成计算图,而tensor类型是pytorch的一种数据类型,是由data 和 grad 两种结构组成
且data 和 grad 两种结构的类型任然是tensor类型
'''
w = torch.tensor([1.0]) #设定权重w的初值为1,
w.requires_grad = True #给w变量开启梯度,由于w是需要计算梯度的,所以需要设定tensor中的grad型
def forward(x):
return x*w; #w是tensor型,x*w也是tensor型
def loss(x,y):
y_val = forward(x)
loss = (y_val -y)**2
return loss
print('before, w= ', forward(4).item()) #w未收敛之前是1
for epoch in range(100): #循环100次
for x,y in zip(x_data,y_data):
l = loss(x,y) #生成计算图,且l是一个张量
l.backward() #进行反向计算,在调用l.backward()之后,w.grad由之前的none变成tensor
print('\tgrad:', x,y,w.grad.item())
w.data = w.data - 0.01*w.grad.data #由于w.grad是tensor类型,所以在进行递减时,需要对w里面的数据进行计算,而不是grad
w.grad.data.zero_()#在每次更新之后返回的w误差都需要归零,以免在进行下一次返回时返回的是误差的和
print('progress', epoch,l.item())
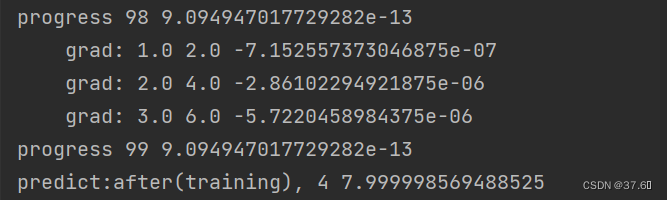
print('after, w= ', forward(4).item()) #通过反向传播算法和梯度下降算法的迭代更新之后,w的值变为2
测试结果
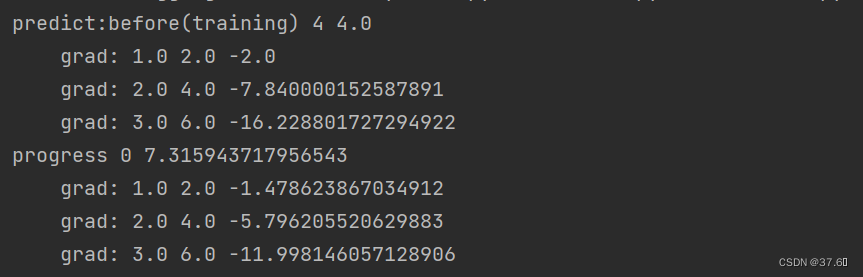
训练之前
训练之前,输入学习时长4之后可以看到分数为4,即线性模型中的w(权重)为初始值1。
训练之后
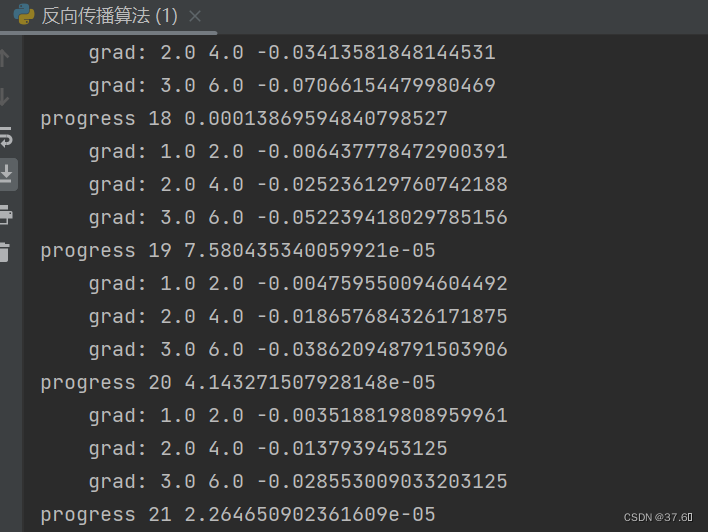
可以看到在20轮左右权重w就已经接近最优值















 1696
1696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









