






先读取一个表格作为DataFrame格式文件:
data = pd.read_excel('dataset-cm.xlsx',sheet_name = None)
#sheet_name = None, 读取所有的sheet;
#sheet_name = 1,读取索引为1的sheet,也就是第二个sheet
data = pd.read_excel('dataset-cm.xlsx', sheet_name = 1)
print(data)
data.head()
#注意,这两种输出方式的结果不同,后者输出的是表格可实现功能:
获取行列数据:
1. 显示前五行:.head()
2. 返回行数和列数:.shape()
行数在前列数在后
3. 返回统计变量:.describe()
count:数量统计,此列共有多少有效值 ;unipue:不同的值有多少个;
std:标准差;min:最小值;max:最大值;mean:均值;
25%:四分之一分位数;50%:二分之一分位数;75%:四分之三分位数。
4. 获取一列:
data['customer_number'] #[]内是想要获取的那列的名字5. 获取多列:
data[['customer_number','cost']]
-----------------
data.loc[: , ['region', 'date_of_sale']]6. 获取某一列的全部数据
data.loc[: , 'region'] #冒号前后数字什么也不写就是获取所有行,region列7. 获取一行:
data.loc[5] #获取第6行,索引为5的行8. 获取多行:
data[:5] #第0行到第4行,左闭右开
data[5:10] #第5行到第9行,左闭右开
------------------------
data.loc[[3, 5, 7]] #索引为3,索引为5,索引为7的行
data.loc[1:10] #左闭右闭,仅此一例
#可以挑着选行, 也可以选区间9. 获取某行某列单个值:
data['customer_number'][5] #customer_number列的第6行(索引为5)
#第0行不算标题那行,从数字行起算
----------------------------
data.loc[5]['region'] #与上面的写法相反;索引为5的行10. 获取多行多列:
data[['customer_number','region']][5:10]#这两列的索引5到索引9行,第6行到第10行
-----------------------------------
data.loc[11:20][['region','date_of_sale']] #索引11行到索引20行,左闭右闭筛选样本:
直接大于、小于号筛选:
data['cost'] > 10 #这样是判断cost列每一行的数据是否>10,返回bool值
'''输出结果是这样的
0 False
1 False
2 True
3 False
4 False
...
49834 False
49835 True
49836 False
49837 False
49838 False
Name: cost, Length: 49839, dtype: bool
'''筛选出来满足大于小于条件的数据:
data[data['cost'] > 10]
#多个条件一起筛选:
data[(data['cost'] > 10) & (data['list_price'] > 20)]
#既要cost>10也要list price>20的数据所在行的其他数据
#单一条件直接是用[],多个条件最外面是[],里面表示两个条件并列用的是(),再里面也是[]
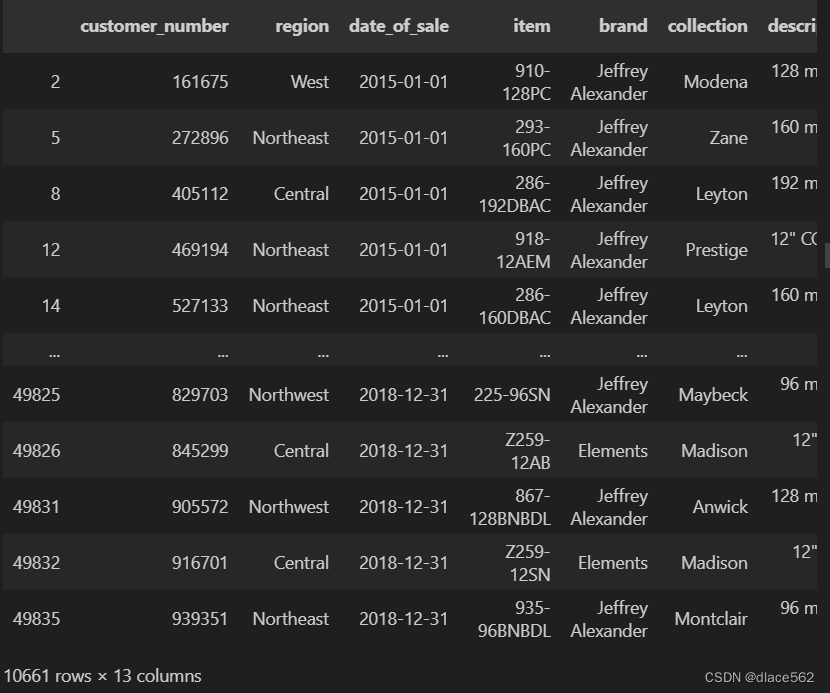
既要满足大于小于条件、又要特定列特定行:
data[(data['cost'] > 10) & (data['list_price'] > 20)]['brand'][10:100]
#既要cost>10也要list price>20的数据所在行的数据,但只要brand列下、且索引为10到索引为99的行(第11行到第100行)
'''
64 Jeffrey Alexander
70 Jeffrey Alexander
74 Jeffrey Alexander
89 Jeffrey Alexander
98 Jeffrey Alexander
...
607 Jeffrey Alexander
622 Jeffrey Alexander
627 Jeffrey Alexander
636 Jeffrey Alexander
638 Jeffrey Alexander
Name: brand, Length: 90, dtype: object
'''既要某一标签一致、又要大于等于、还要特定列特定行:
data[(data['brand'] == 'Jeffrey Alexander') & (data['quantity_sold'] > 500)]['customer_number'][5:100]
'''
16 550847
19 620461
20 743401
24 5530
28 83058
...
385 111641
395 267302
404 419912
408 485534
418 15691
Name: customer_number, Length: 95, dtype: int64
'''构建变量:
#直接加减乘除生成新的列:
data['sales revenue'] = data['list_price'] * data['quantity_sold']
pd.options.display.float_format = '{:,.2f}'.format
#通过pd.option设置输出格式,这里设置成浮点数并保留两位小数,这一行可以直接复制粘贴检查与修改异常值:
返回去重之后的不同值:.unique()
data['region'].unique() #返回去重之后的不同值
#输出结果为:array(['Midwest', 'Northwest', 'West', 'Northeast', 'East coast', 'Central', 'South', 'International', 'Centrall', 'Soouth'], dtype=object)
修改异常值:
data.loc[data['region'] == 'Soouth']['region'] = 'South'
data.loc[data['region'] == 'Centrall']['region'] = 'Central'
data['region'].unique()
#输出结果为:array(['Midwest', 'Northwest', 'West', 'Northeast', 'East coast', 'Central', 'South', 'International'], dtype=object)
错误做法:
if data['region'] == 'Soouth':
data['region'] = 'South'分类聚合.groupby():
按多项标准分类并输出:
#几个条件都是按元组输出
list(data.groupby(['year', 'quarter', 'region']))
#输出的是元组(2015, 1, 'Central')的结果,然后是(2015, 1, 'Midwest')的结果,统共一大篇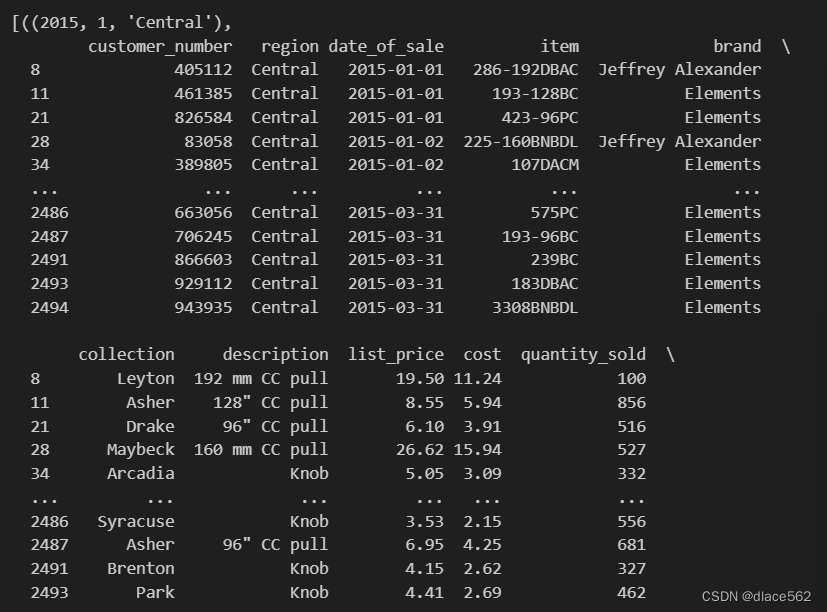
按某一列分类并输出:
grouped1 = data.groupby('region')
for name, group in grouped1:
print(name)
print(group)
#同上,先是Central的结果,然后是Midwest的,等等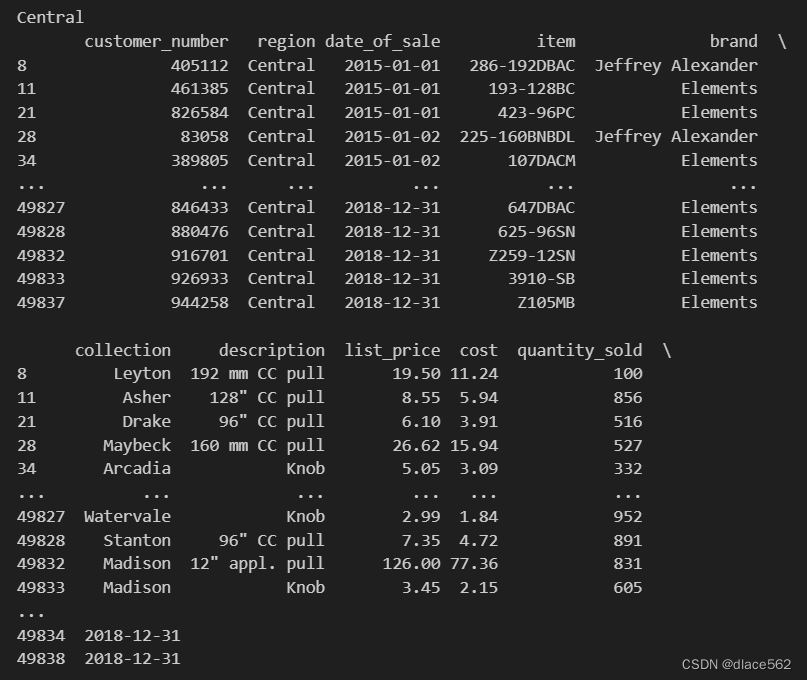
求和.sum()
data.groupby(['year','quarter','region'])[['sales revenue','contribution margin']].sum()
#按'year','quarter','region'分组,然后求'sales revenue','contribution margin'这两列的和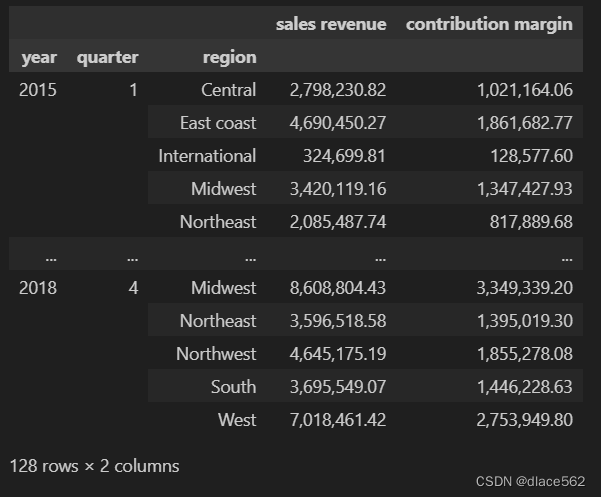
不能分组后直接求和,会报错:
data.groupby(['year', 'quarter', 'region']).sum()
-----------------------------------
TypeError Traceback (most recent call last)
c:\Users\16613\Desktop\SUFE\Python\Pandas1-contribution margin case.ipynb Cell 122 line 1
----> 1 data.groupby(['year', 'quarter', 'region']).sum()
File d:\miniconda\lib\site-packages\pandas\core\groupby\groupby.py:2263, in GroupBy.sum(self, numeric_only, min_count, engine, engine_kwargs)
2258 else:
2259 # If we are grouping on categoricals we want unobserved categories to
2260 # return zero, rather than the default of NaN which the reindexing in
2261 # _agg_general() returns. GH #31422
2262 with com.temp_setattr(self, "observed", True):
-> 2263 result = self._agg_general(
2264 numeric_only=numeric_only,
2265 min_count=min_count,
2266 alias="sum",
2267 npfunc=np.sum,
2268 )
2270 return self._reindex_output(result, fill_value=0)
File d:\miniconda\lib\site-packages\pandas\core\groupby\groupby.py:1422, in GroupBy._agg_general(self, numeric_only, min_count, alias, npfunc)
1413 @final
1414 def _agg_general(
1415 self,
(...)
1420 npfunc: Callable,
...
258 elif is_period_dtype(dtype):
259 # Adding/multiplying Periods is not valid
260 if how in ["sum", "prod", "cumsum", "cumprod"]:
TypeError: datetime64 type does not support sum operations对分组后的数据进行计算.agg():
data.groupby(['year', 'quarter', 'region']).agg({'sales revenue':['sum', 'mean']})
#前面把数据分成三组,然后用agg求这三组里'sales revenue'列的和与均值
#agg后面中间是个花括号,不是方括号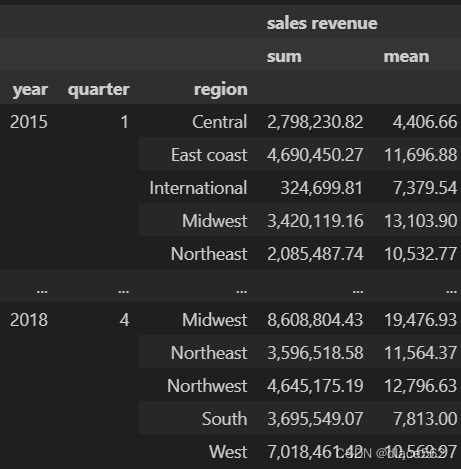
a = data.agg({'sales revenue': 'sum'})
b = data.agg({'sales revenue': 'mean'})
print(a)
print(b)
#这样输出的就不再是表格里的数据,而是一个数字
'''
sales revenue 485,076,624.17
dtype: float64
sales revenue 9,732.87
dtype: float64
'''#a = data.sum()
b = data['sales revenue'].sum()
#print(a)
#datetime类型的数据不能sum,所以print(a)会报错
print('--------------------')
print(b)
#print('sum = %.2f'(b))
'''
485076624.17078227
'''索引重置.reset_index():
data.groupby(['year', 'quarter', 'region']).agg({'sales revenue':['sum']}).reset_index()排序.sort_values():
long_table = data.groupby(['year','quarter','region'])['sales revenue'].sum().reset_index()
long_table = long_table.sort_values(['year','quarter','region'])
#sort_values将表格按照这三个字段进行排序
long_table.head(100)
#显示前100行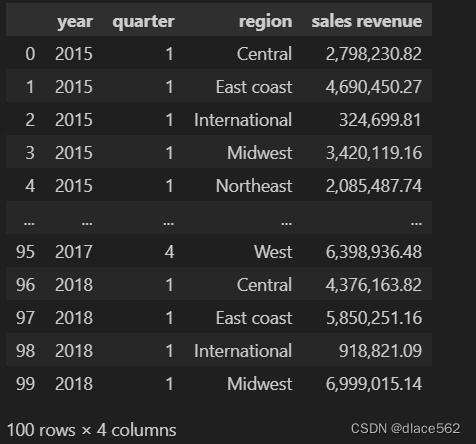
long_table = long_table.sort_values('year')
#仅按着year进行排序
long_table.head(100)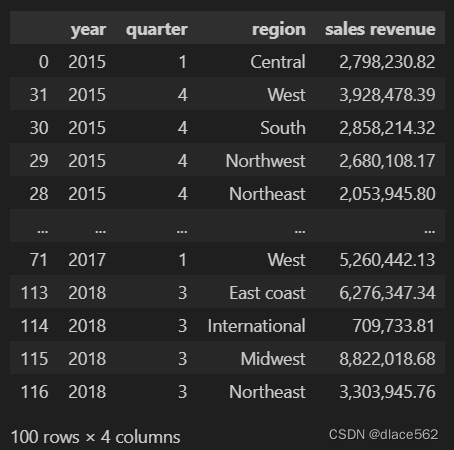
数据透视.pivot_table():
data.pivot_table( index = ['year','quarter'], values='sales revenue', columns='region')
#索引为year和quarter,双索引;显示的结果为sales revenue;按region列里的数据再度分类
#index后有[],别的可以没有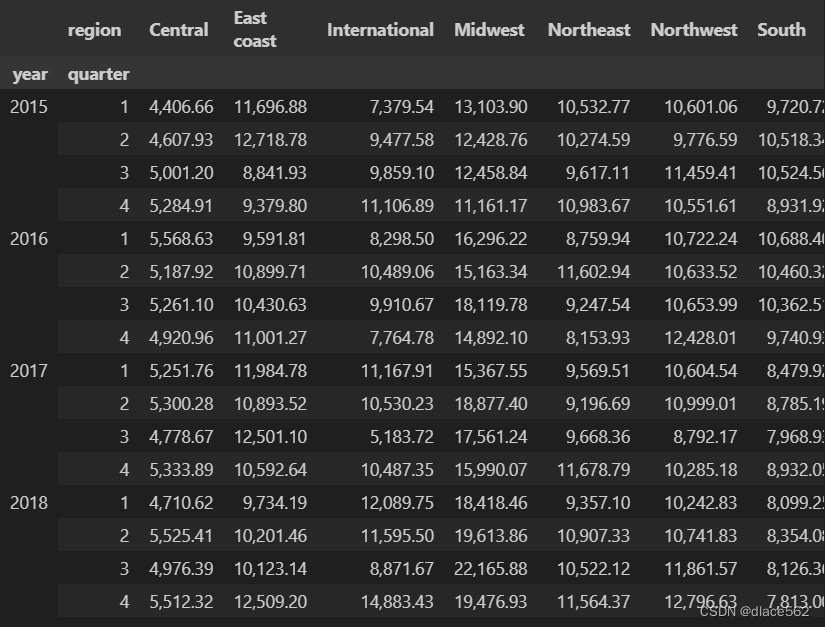
data.pivot_table(index = ['year', 'quarter'], values = 'sales revenue', columns = 'region', aggfunc = sum)
#上面分完列后求和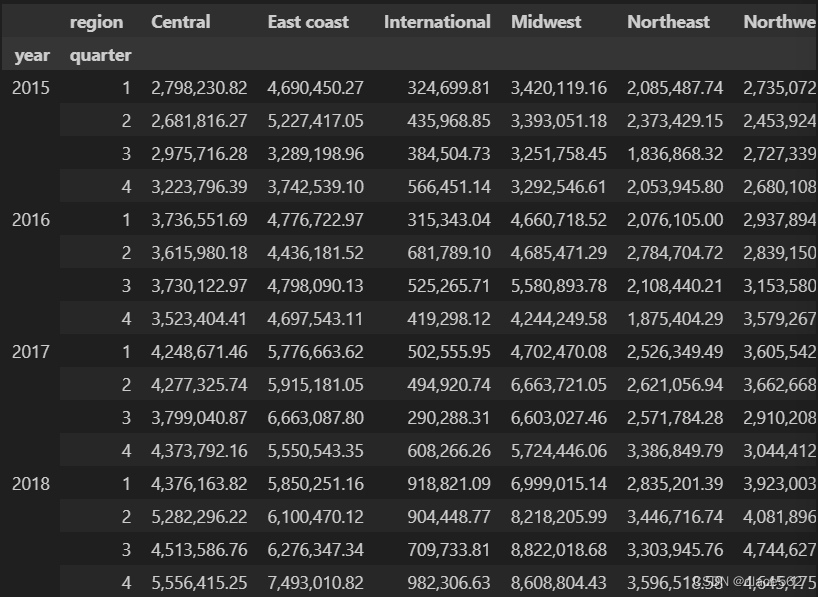
检验表中数据是否正确:
data.loc[(data['year'] == 2015) & data['quarter'] == 1 & (data['region'] == 'Central')]['sales revenue'].sum()
----------------------------------------
data[(data['year'] == 2015) & data['quarter'] == 1 & (data['region'] == 'Central')]['sales revenue'].sum()一些实例:
每个品牌(brand)-系列(collection)-区域(region)平均可变成本(variable cost)的透视表
wide_table1 = data.pivot_table(index = ['brand', 'collection'], values = 'variable cost', columns = 'region', aggfunc = 'mean')
#aggfunc后的sum或mean要用单引号引起来
# 值是可变成本,用aggfunc来显示平均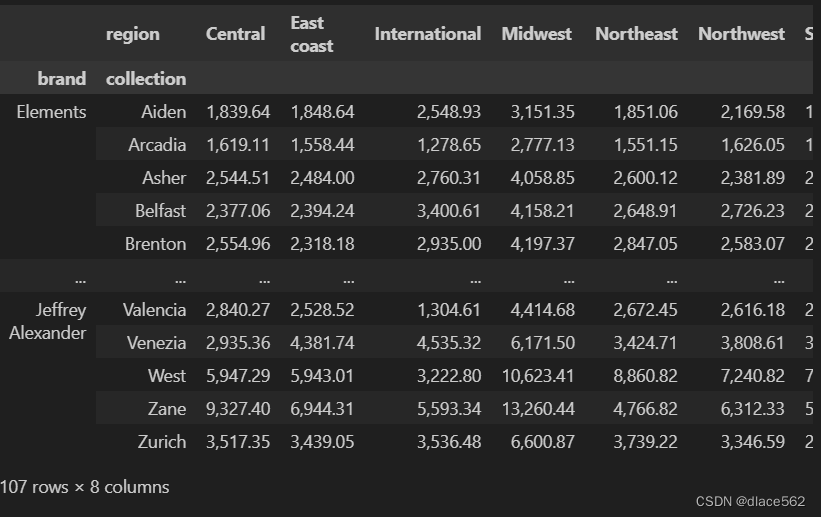
选择最赚钱的品牌并排序:
cm1 = data.groupby(['year', 'brand']).agg({'contribution margin' : 'sum'})
cm1.sort_values('contribution margin')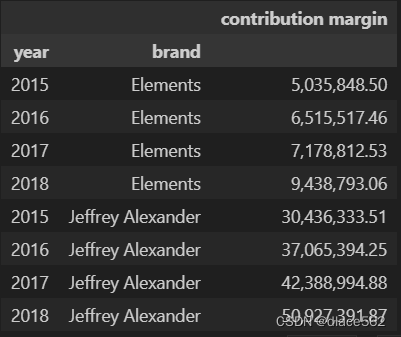
按品牌求和:
cm2 = data.pivot_table(index = ['year'], values = 'contribution margin', columns = ['brand'], aggfunc = 'sum')
cm2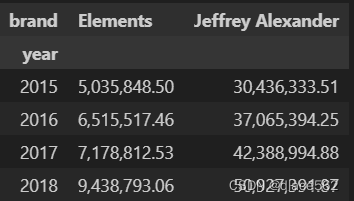
Excel写入:
将修改后的数据存入新excel:
data.to_excel('excel1.xlsx', sheet_name = '1')
#excel1.xlsx是新表格的名字,sheet_name = '1'是让存入第一张sheet将新生成的数据写入新的sheet:
with pd.ExcelWriter('excel1.xlsx', mode = 'a', engine = 'openpyxl') as writer:
cm1.to_excel(writer, sheet_name ='2')
cm2.to_excel(writer, sheet_name ='3')
cm3.to_excel(writer, sheet_name ='4')
#mode = 'a'是追加模式,写入时在文件末尾添加数据;默认的'w'是覆盖模式,写入是将清空文件内容
一些小功能:
查看某列有多少个不同值并计算出现个数:.value_counts()
data['region'].value_counts()
'''
region
Central 12246
West 8162
East coast 7875
South 6307
Midwest 5310
Northwest 4952
Northeast 4091
International 896
Name: count, dtype: int64
'''获取时间信息:
提取年、季、月、小时并储存在新的列:
data['year'] = data['date_of_sale'].dt.year
#在表格最后生成了一个新的列'year',提取的是'date_of_sale'列的年份信息
#dt.year可以直接提取出年份,int型;同样存在dt.quarter, dt.month, dt.day, dt.hour提取2015-01-01格式的日期:
data['date'] = data['date_of_sale'].dt.strftime('%Y-%m-%d')
#%Y是2015,%y是15
#但经dt.strftime()处理后的数据不再是datetime类型,在excel里也不再被识别为日期














 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









