







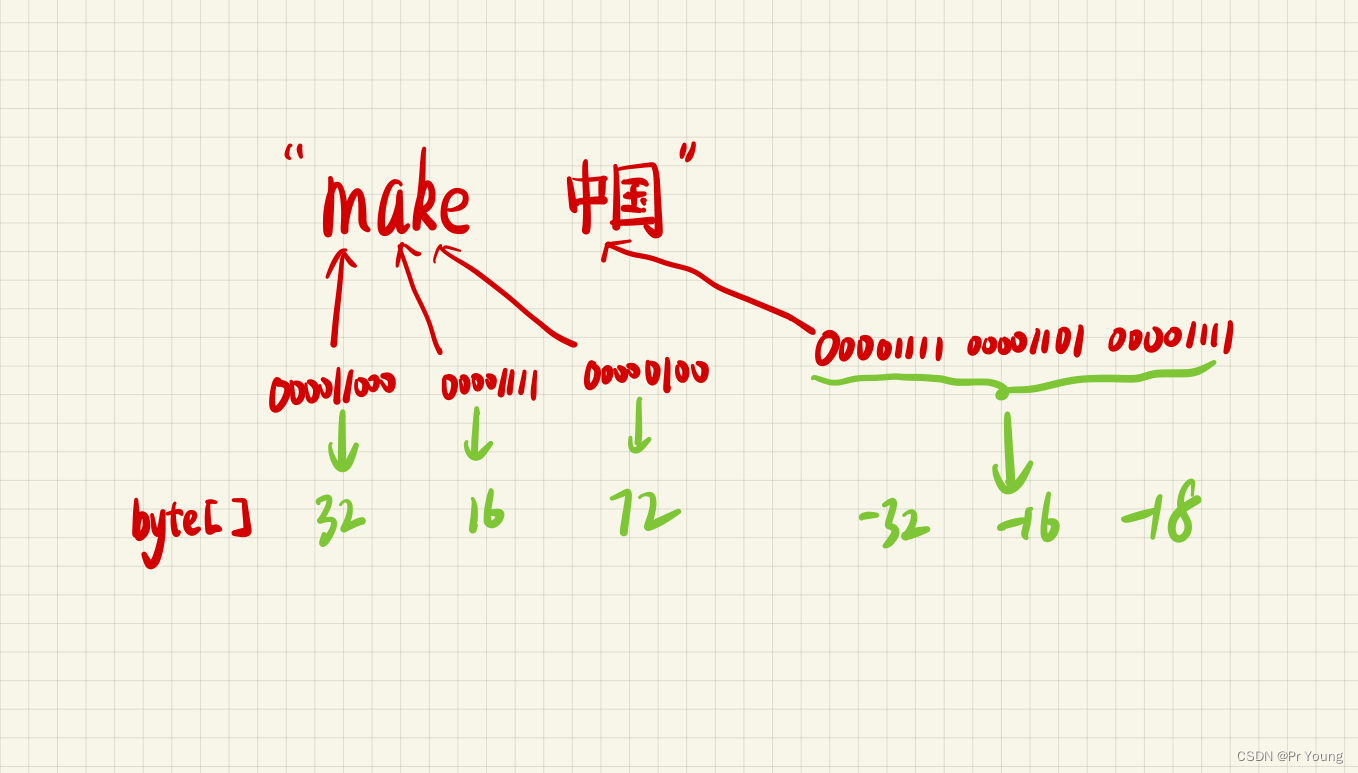
字符串中的字符变成一位一位的01比特流
一个英文字符占8比特,也就是一个字节
一个中文字符占24比特,也就是3个字节(其实不同编码方式,占几个字节不一样,我们这里采取的UTF-8编码方式,具体可以看下图:)

而byte[ ] byte数组里面存的就是每个字节(8位)表示的数字
所以一个英文字符(8比特)只需要1个byte数组的元素就能存下来
而一个中文字符(24比特)需要3个byte数组的元素才能存下来
看下面这个例子:
public class test2
{
public static void main(String[] args)
{
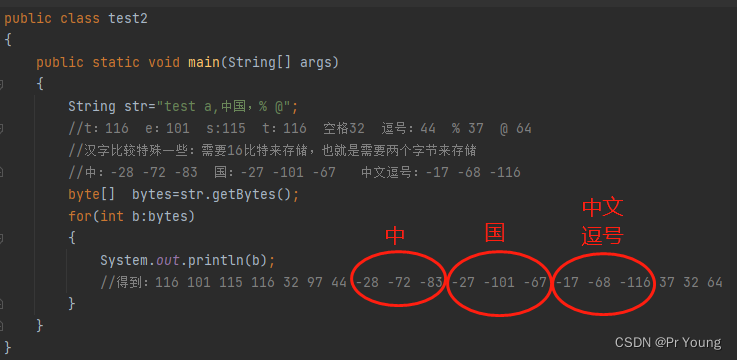
String str="test a,中国,% @";
//t:116 e:101 s:115 t:116 空格32 逗号:44 % 37 @ 64
//汉字比较特殊一些:需要16比特来存储,也就是需要两个字节来存储
//中:-28 -72 -83 国:-27 -101 -67 中文逗号:-17 -68 -116
byte[] bytes=str.getBytes();
for(int b:bytes)
{
System.out.println(b);
//得到:116 101 115 116 32 97 44 -28 -72 -83 -27 -101 -67 -17 -68 -116 37 32 64
}
}
}}
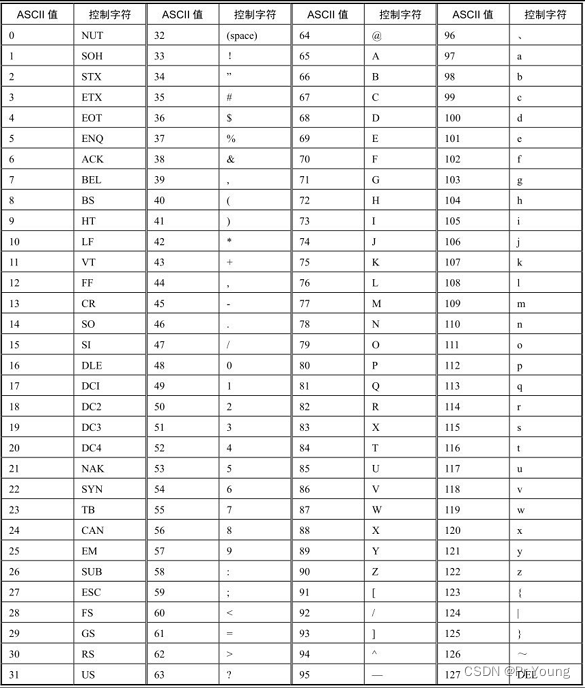
附上ASCII表
//输入一串字符(包括汉字,数字,空格,英文字母.....)分别统计出各类的个数
public class test
{
public static void main(String[] args) throws IOException
{
String string=new String("");
int hanzi=0;//统计汉字的个数
int zimu=0;//统计字母的个数
int kongge=0;//统计空格的个数
int shuzi=0;//统计数字的个数
int qita=0;
System.out.println("请输入一行字符:");
//下面两行代码的意思是:第一行:先将字符串放到缓冲区里面
// 第二行:然后将缓冲区的字符串赋给string,这样string就等于我们刚才输入的字符串
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
string=br.readLine();
byte[] bytes=string.getBytes();
for(int i=0;i<bytes.length;i++)
{
//System.out.println(bytes[i]);
if((bytes[i]>=65&&bytes[i]<=90)||(bytes[i]>=97&&bytes[i]<=122)) zimu++;
else if(bytes[i]==32) kongge++;
else if(bytes[i]>=48&&bytes[i]<=57) shuzi++;
else if(bytes[i]<0) hanzi++;
else qita++;
}
System.out.println(zimu);
System.out.println(hanzi/3);
System.out.println(kongge);
System.out.println(shuzi);
System.out.println(qita);
// 最终的输入输出如下:
// java真是太棒了!! wotaixihuanle 123456
// 17
// 5
// 4
// 6
// 2
}
}














 5582
5582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









