







一、RDD的创建方式
1.从文件系统加载数据创建RDD
(1)从Linux本地文件系统加载数据创建RDD
在Linux本地文件系统创建一个test.txt文件,内容如下:
hadoop spark
itcast heima
scala spark
spark itcast
itcast hadoop
在Linux本地系统读取test.txt文件并创建RDD
val test=sc.textFile("file:///export/data/test.txt")
(2)从HDFS中加载数据创建RDD
在HDFS上的/data目录下须有test.txt文件,通过加载HDFS中的数据创建RDD
val testRDD=sc.textFile("/data/test.txt")
2.通过并行集合创建RDD
// 创建一个数组
val array=Array(1,2,3,4,5)
val arrRDD=sc.parallelize(array)
二、RDD的处理过程
1.转换算子
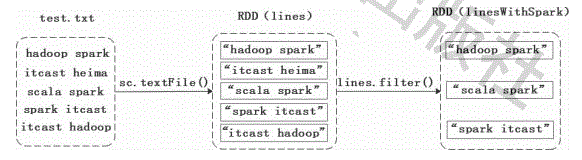
(1)filter(func)
filter(func)操作会筛选满足函数func的元素,并返回一个新的数据集。
// 若存在“spark”单词,则保存下来,否则丢弃该元素
val lines=sc.textFile("file:///export/data/test.txt")
val linesWithSpark=lines.filter(line=>line.contains("spark"))
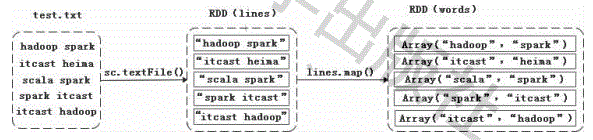
(2)map(func)
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。
val lines=sc.textFile("file:///export/data/test.txt")
val words=lines.map(line=>line.split(" "))
(3)flatMap(func)
flatMap(func)和map(func)相似,但是每个输入的元素都可以映射到0或者多个输出的结果。
val lines=sc.textFile("file:///export/data/test.txt")
val words=lines.flatMap(line=>line.split(" "))

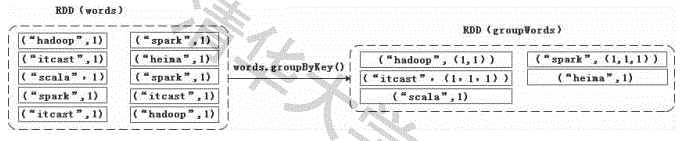
(4)groupByKey()
groupByKey()主要用于(Key,Value)键值对的数据集,将具有相同Key的Value进行分组,会返回一个新的(Key,Iterable)形式的数据集。
val lines=sc.textFile("file:///export/data/test.txt")
val words=lines.flatMap(line=>line.split(" ").map(word=>(word,1)))
val groupWords=words.groupByKey()
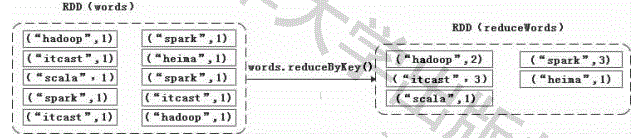
(5)reduceByKey(func)
reduceByKey(func)主要用于(Key,Value)键值对的数据集,返回的是一个新的(Key,Value)形式的数据集,该数据集是每个Key传递给函数func进行聚合运算后得到的结果。
val lines=sc.textFile("file:///export/data/test.txt")
val words=lines.flatMap(line=>line.split(" ").map(word=>(word,1)))
val reduceWords=words.reduceByKey((a,b)=>a+b)
2.行动算子
(1)count()
用于返回数据集中的元素个数。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
// val arr = Array(1,2,3,4,5)
// val arrRDD = sc.pallelize(arr)
arrRDD.count()
(2)first()
返回数组的第一个元素。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
arrRDD.first()
(3)take(n)
用于以数组的形式返回数组集中的前n个元素。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
arrRDD.take(3)
(4)reduce()
用于通过函数func(输入两个参数并返回一个值)聚合数据集中的元素。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
arrRDD.reduce((a,b)=>a+b)
(5)collect()
用于以数组的形式返回数据集中的所有元素。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
arrRDD.collect()
(6)foreach(func)
用于将数据集中的每个元素传递函数func中运行。
val arrRDD = sc.parallelize(Array(1,2,3,4,5))
arrRDD.foreach(x=>println(x))
















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











