







目录
一、定义:
字节序:顾名思义字节的顺序,就是大于一个字节欸行的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了),注意:网络字节序都是大端。
二、分类:
字节序分为大端字节序和小端字节序。大端字节序指一个整数的最高位字节(24-31bit)存储在内存的低地址处,低位字节(0-7bit)存储在内存的高地址处;小端字节序则是指整数的高位字节存储在内存的高地址处,而低位字节则存储在内存的低地址处。
三、举例:
小端字节序(内存低位存放数据的低字节,内存高位存放数据的高字节):
0x 01 02 03 04(顺序由高到低)
内存方向----------->
内存的低位-------------->内存的高位
04 03 02 01
大端字节序(内存低位存放数据的高字节,内存高位存放数据的低字节)
0x 01 02 03 04(顺序由高到低)
内存方向------------>
内存的低位------------------>内存的高位
01 02 03 04
四、如何判断大端还是小端?
通过代码检验当前主机的字节序。
#include <stdio.h>
int main()
{
union{
short val;
char bytes[sizeof(short)];
}test;
test.val=0x0102;
if((best.bytes[0]==1)&&(test.bytes[1]==2))
{
printf("大端字节序\n");
}
else if((best.bytes[0]==2)&&(test.bytes[1]==1))
{
printf("小端字节序\n");
}
else
printf("未知\n");
return 0;
}我的电脑显示的是:![]()
五、字节序转换函数
当格式化的数据在两台使用不同字节序的主机之间直接传递时,接收端必然是错误的。解决问题方法:发送端总是把发送的数据转换成大端字节序数据后再发送,而接收端知道对方传递过来的数据总是采用大端字节序,所以接收端可以根据自身采用的字节序来决定是否对接收到的数据进行转换(小端转换,大端不转换)。
网络字节序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型,操作系统等无关,从而可以保证数据在不同的主机之间传输时能够被正确的解释,网络字节序采用大端排序方法。
h - host:主机,主机字节序;
to - 转换成什么;
n - network 网络字节序
s - short
l - long (unsigned int)
#include <arpa/inet.h>
//转换接口
uint16_t htons(uint16_t hostshort);//主机字节序到网络字节序的转换
uint16_t ntohs(uint16_t netshort);//网络字节序到主机字节序的转换
//转换IP
uint32_t htonl(uint32_t hostlong);//主机字节序到网络字节序的转换
uint32_t ntohl(uint32_t netlong);//网络字节序到主机字节序的转换注意:网络通信时,需要将主机字节序转换成网络字节序(大端),另外一段获取到数据以后根据情况将网络字节序转成主机字节序。
用代码来解释这几个函数的意思。
1 #include <stdio.h>
2 #include <arpa/inet.h>
3 int main()
4 {
5 //htons 转换端口
6 unsigned short a=0x0102;
7 printf("a:%x\n",a);
8 unsigned short b=htons(a);
9 printf("b:%x\n",b);
10
11 printf("******************\n");
12
13 //htonl 转换ip
14 char buf[4]={192,168,1,100};
15 int num=*(int *)buf;
16 int sum=htonl(num);
17 unsigned char *p=(char *)∑
18
19 printf("%d %d %d %d\n",*p,*(p+1),*(p+2),*(p+3));
20 return 0;
21 }
运行结果为: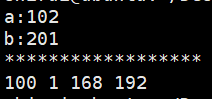
可以看出:a:102,这个是小端字节序,其实还原为a:0x0102(01还是在地址高位,02还是地址低位);b:201,这是大端字节序,其实还原为b:0x0201(此时的01变为低位,02变为高位)。















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









