







什么是数据湖
在开始整活之前,先介绍一下什么是数据湖,来一段亚马逊云上的介绍:
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。

将任意结构的数据(Mysql、文本、视频)存储在任意规模的的存储系统中,可以按照原样存储数据(不需要强制绑定schema,也就是不用确定表结构),并进行不同的分析,比如离线实时ETL、机器学习、报表分析
那么,数据湖和数据仓库又有什么区别呢[1]?
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |

那沧湖一体又是什么?
什么是仓湖一体
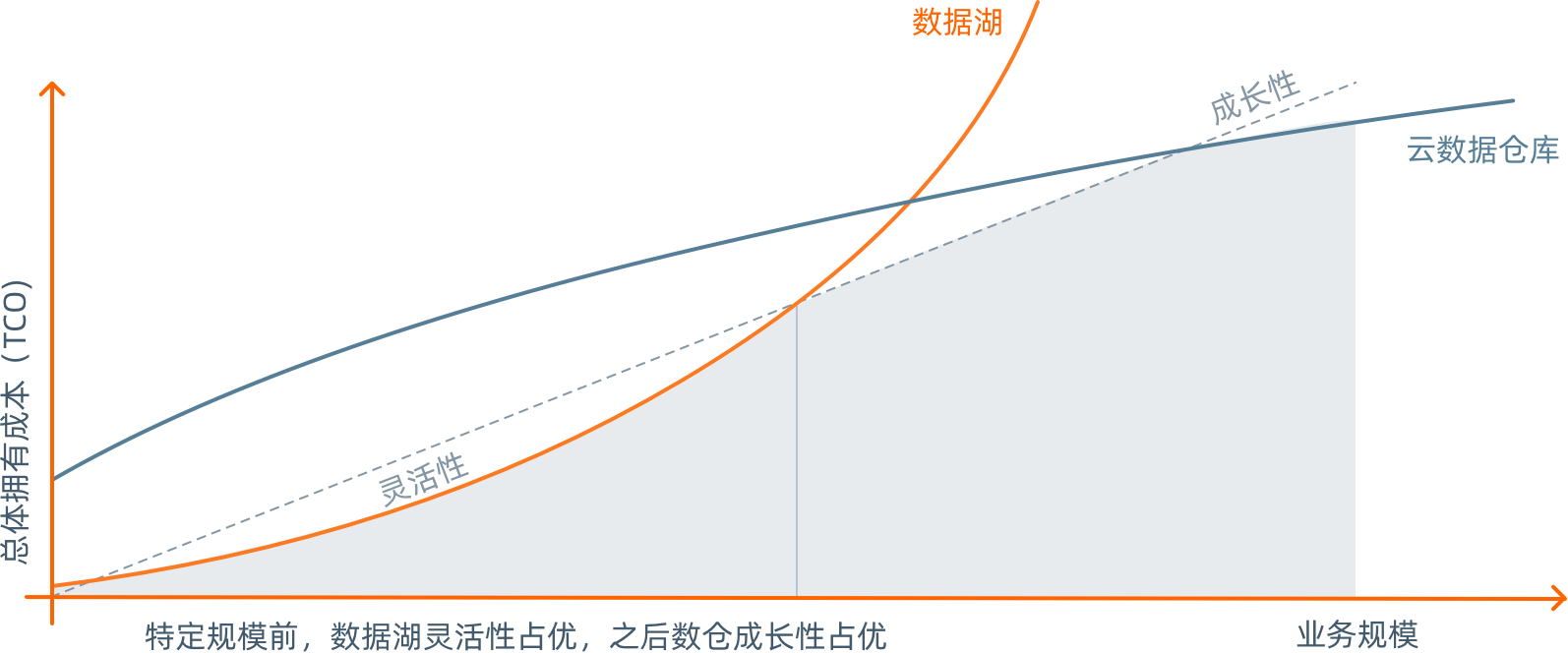
一句话概括
兼具数据湖的灵活性与数据仓库的成长性,通过统一的数据平台进行数据开发、数据管理和数据治理,降低存储、计算成本,告别数据沼泽
那和我们的主题Apache Iceberg又有什么关系?换句话说,Iceberg在仓湖一体的数据架构中,起到什么样的作用
什么是Apache Iceberg
Apache Iceberg is a new table format for storing large, slow-moving tabular data. It is designed to improve on the de-facto standard table layout built into Hive, Trino, and Spark.
Apache Iceberg是一个全新的Table Format,用于存储缓慢移动的表格数据。它被设计用于提升内置在Hive,Trino和Spark中的事实上的标准表布局
说白了,就是一个table format,可以在Hive、Trino(Presto)、Spark中使用,利用Iceberg的特性来丰富我们的场景,解决了我们的痛点
这里可能和大家认知的不太一样,包括Iceberg在内的主流Data Lake House 框架,都只是一个Table Format,而不是一个像Hdfs一样的存储引擎,反而更像Parquet、ORC这些Table Format;与这些常见的Table Format不一样的是,Iceberg会将数据文件存储成Parquet、ORC等格式,并且会生产一些特殊的元数据文件,利用这些元数据文件,来实现它独有的特性
- Schema Evolution
- 很轻易的改变表结构而不需要重跑数据
- 因为Schema更新是元数据更改,因此不需要重写任何数据文件即可执行更新
- Iceberg保证Schema的更新是独立且无副作用的,并且无需重写文件
- Partition Evolution
- Iceberg实施了隐藏分区,Iceberg还可以提供分区更新的功能
- 这意味着我们可以在不需要重跑的前提下,改变分区粒度和分区列
- 并且,旧数据可以和新数据可以共存在表中,Iceberg自动帮你进行数据merge
- Time travel
- Iceberg是通过实施快照来进行表的增删改查,所以Iceberg支持读取之前的快照数据和进行表回滚
-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded). SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ; - Query Engine Support
- 支持多种查询引擎:Spark、Flink、Trino(Presto)
- 并且支持使用这些引擎进行DDL操作
- 支持流式读取和流式插入
再回过头看看探讨什么是仓湖一体的时候,我们总结的那句话兼具数据湖的灵活性与数据仓库的成长……
有没有发现,Iceberg能够帮我们去实现我们的愿景呢?
写在最后
- 和之前的Flink和Zeppelin系列一样,这也会是一个系列文章,并且争取每周一篇的不断更新下去,希望能坚持住
- 本系列从下次分享开始,将会和Flink、Zeppelin整合起来,通过使用Zeppelin来执行Flink Sql,深入浅出的进行Iceberg的探究
- 在文章的后期,我们也将会进行源码的分析,并尝试实现Iceberg与华为云OBS与Flink的整合(为啥用OBS呢,因为我们公司用的华为云)
- 最后!希望自己能坚持下去
引用
[1] 什么是数据湖
[2] 湖仓一体
[3] Apache Iceberg简介















 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









