







前言:本例使用的是一个天气时间序列数据集,由德国耶拿的马克思普朗克生物地球化学研究所的气象站记录,这个例子作为初学者必看的例子之一,在这个数据集中,每十分钟记录14个不同的量(比如风向、湿度等),其中包含多年的记录。最原始的数据可以追溯到2003年,我们利用此数据构建模型,输入最近的一些数据,比如几天的,可以预测出24h之后的气温。
数据集的样子如下:
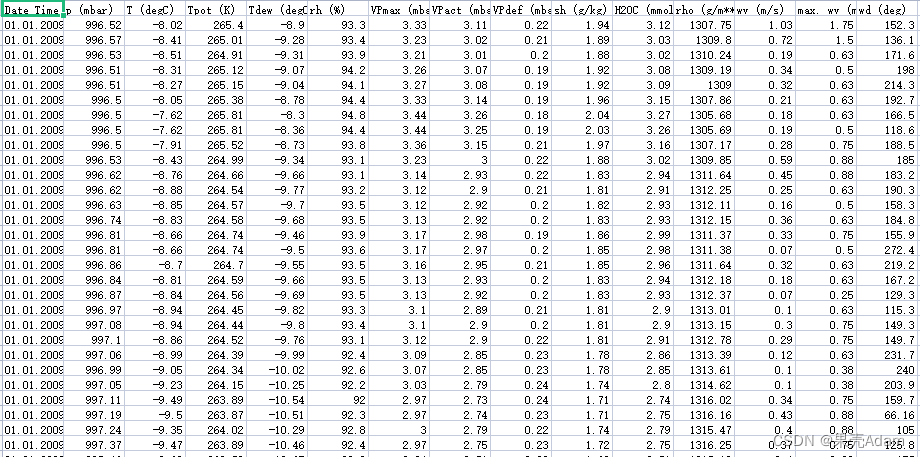
话不多说,直接上代码
一、代码
import os
data_dir='jena_climate_2009_2016'
fname=os.path.join('jena_climate_2009_2016.csv')
f=open(fname)
data=f.read()
f.close()
lines=data.split('\n')#按照指定的分割符进行分割
header=lines[0].split(',')
lines=lines[1:]
print(len(header)) #15
print(len(lines)) #420451可以先进行一个简单的解析过程:
import numpy as np
float_data=np.zeros((len(lines),len(header)-1))
#print(float_data.shape) #(420451,14)
for i ,line in enumerate(lines):
values=[float(x) for x in line.split(',')[1:]]
float_data[i,:]=values
#print(float_data.shape) #(420451,14)
from matplotlib import pyplot as plt
temp=float_data[:,1]#温度,单位摄氏度
plt.plot(range(1440),temp[:1440])
plt.show()可以得到前十天温度的数据图像,因为每十分钟记录一个数据,所以每天都有144个数据点。接着可以绘制前十天的温度时间序列:
plt.plot(range(1440),temp[:1440])
plt.show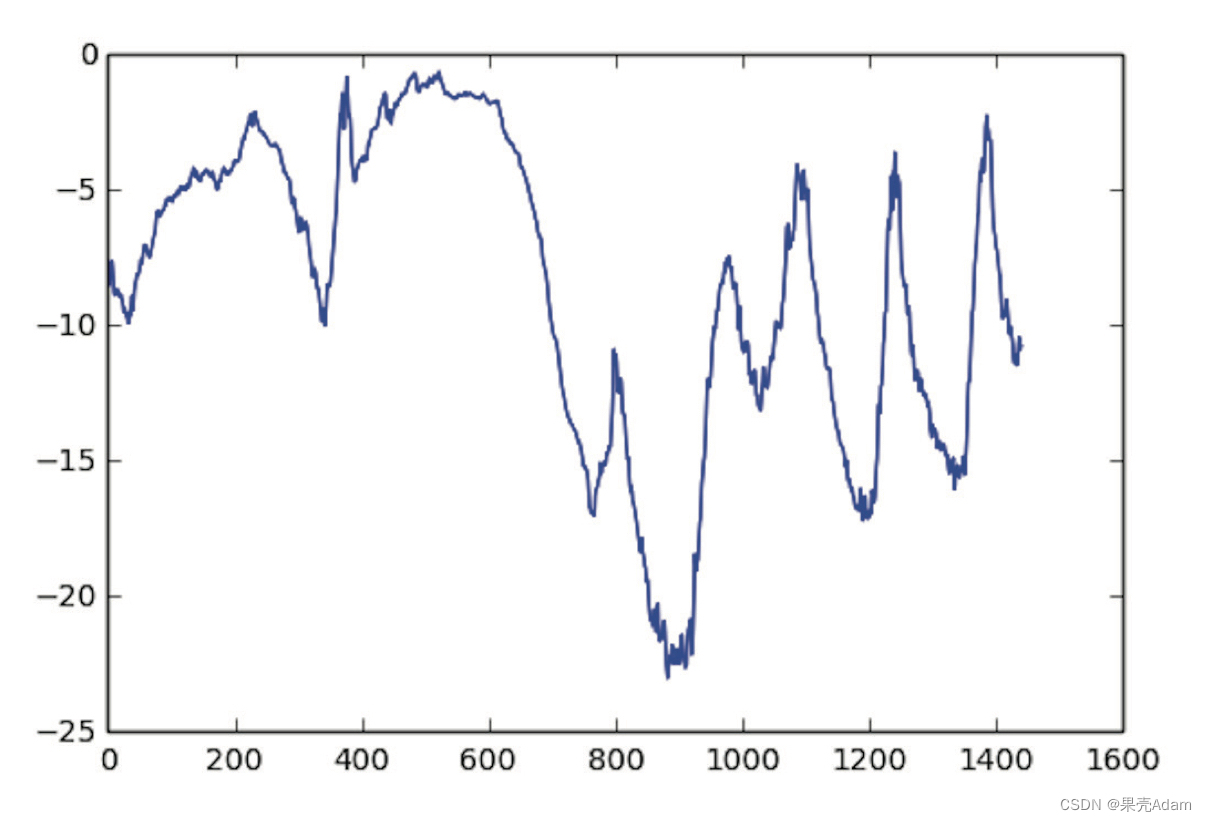
这张图可以告诉我们一个信息,就是每天的周期性变化,尤其是最后四天特别明显,另外这十天一定是来自冬季。
接下来准备数据,一个时间步是十分钟,每steps个时间步采样一次数据,给定过去lookback个时间步之内的数据,能否预测delay个时间步之后的温度?将数据预处理为可以处理的格式,对每个时间序列分别做标准化。之后编写一个Python生成器,以当前的浮点数数组作为输入,并从最近的数据中生成数据批量,同时生成未来的目标温度。
lookback=720#输入数据应该包括过去多少个时间步
steps=6#数据采样的周期
dealy=144#目标应该在未来多少个时间步之后
#数据标准化
mean=float_data[:200000].mean(axis=0)
float_data-=mean
std=float_data[:200000].std(axis=0)
float_data/=std
#生成时间序列样本及其目标的生成器
def generator(data,lookback,delay,min_index,max_index,shuffle=False,batch_size=128,step=6):#迭代器,用于生成样本和目标数据
if max_index is None:
max_index=len(data)-delay-1#如果没有指定最大索引,则将其设置为数据长度减去延迟1天
i=min_index+lookback
while 1:
if shuffle:
rows=np.random.randint(min_index+lookback,max_index,size=batch_size)
else:
if i+batch_size>=max_index:
i=min_index+lookback
rows=np.arange(i,min(i+batch_size,max_index))
i+=len(rows)
samples=np.zeros((len(rows),lookback//step,data.shape[-1]))
targets=np.zeros((len(rows),))
for j,row in enumerate(rows):
indices=range(row[j]-lookback,rows[j],step)
samples[j]=data[indices]
targets[j]=data[row[j]+delay][1]
yield samples,targets #无限生成样本和目标数据
准备训练生成器、验证生成器和测试生成器:
#准备训练生成器、验证生成器、测试生成器
lookback=1440#输入数据应该包括过去多少个时间步
step=6#数据采样的周期
delay=144#目标应该在未来多少个时间步之后
batch_size=128
train_gen=generator(float_data,lookback=lookback,delay=delay,min_index=0,max_index=200000,shuffle=True,step=step,batch_size=batch_size)
val_gen=generator(float_data,lookback=lookback,delay=delay,min_index=200001,max_index=300000,shuffle=True,step=step,batch_size=batch_size)
test_gen=generator(float_data,lookback=lookback,delay=delay,min_index=300001,max_index=None,shuffle=True,step=step,batch_size=batch_size)
val_steps=(300000-200001-lookback)//batch_size #为了查看整个验证集,需要从val_gen中抽取多少次
test_steps=(len(float_data)-300001-lookback)//batch_size#为了查看整个测试集,需要从test_gen中抽取多少次训练并评估一个基于GRU的模型(GRU全称gated recurrent unit,工作原理与LSTM相同,但做了一些简化,计算代价更低):
#训练并评估一个基于GRU的模型
# from keras.models import Sequential
# from keras import layers
# from keras.optimizers import RMSprop
#
# model=Sequential()
# model.add(layers.GRU(32,input_shape=(None,float_data.shape[-1])))
# model.add(layers.Dense(1))
#
# model.compile(optimizer=RMSprop(),loss='mae')
# history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=20,validation_data=val_gen,validation_steps=val_steps)可以查看模型的结果,效果还是不错的,接下来训练并评估一个使用dropout正则化的基于GRU的模型:
#训练并评估一个使用dropout正则化的基于GRU的模型
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model=Sequential()
model.add(layers.GRU(32, dropout=0.2,recurrent_dropout=0.2,input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=40,validation_data=val_gen,validation_steps=val_steps)也可以尝试循环层的堆叠:
model=Sequential()
model.add(layers.GRU(32, dropout=0.1,recurrent_dropout=0.5,return_sequences=True,input_shape=(None, float_data.shape[-1])))
model.add(layers.GRU(64,activation='relu', dropout=0.1,recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=40,validation_data=val_gen,validation_steps=val_steps)在Keras中将一个双向RNN实例化,需要使用Bidirectional()层:
model=Sequential()
model.add(layers.Bidirectional(layers.GRU(32),input_shape=(None,float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=40,validation_data=val_gen,validation_steps=val_steps)当然,以上并没有介绍过多的原理,如果读者感兴趣可以自己搜索一下原理,本案例只介绍项目对应的代码部分。
为了提高性能,还可以在堆叠循环层中调节每层的单元个数,调节RMSprop的学习率,使用LSTM代替GRU等等
有任何问题欢迎留言,感谢大家,恳求点赞哦!!!!如果需要数据或者其他,可以私信评论!!
以下是我的github主页,欢迎光临!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









