







引言:CNN在计算机视觉问题上表现出色,原因在于它能够进行卷积运算,从局部输入图块中提取特征,并能将表示模块化,同时可以高效地利用数据,同样也让它对序列处理特别有效,时间可以被看做一个空间维度,就像二维图像的高或宽。对于某些序列处理问题,这种一维卷积的效果甚至可以媲美RNN,而且计算代价通常要小很多。近年,一维卷积网络通常与空洞卷积核一起使用,在音频生成和机器翻译领域取得了巨大的成功。
一:理解序列数据的一维卷积
使用一维卷积,从序列中提取局部一维序列段,这种一维卷积可以识别序列中的局部模式。对每个序列段执行相同的输入变换,所以在句子中某个位置学到的模式稍后可以在其他位置被识别,这使得一维卷积神经网络具有平移不变性。如图: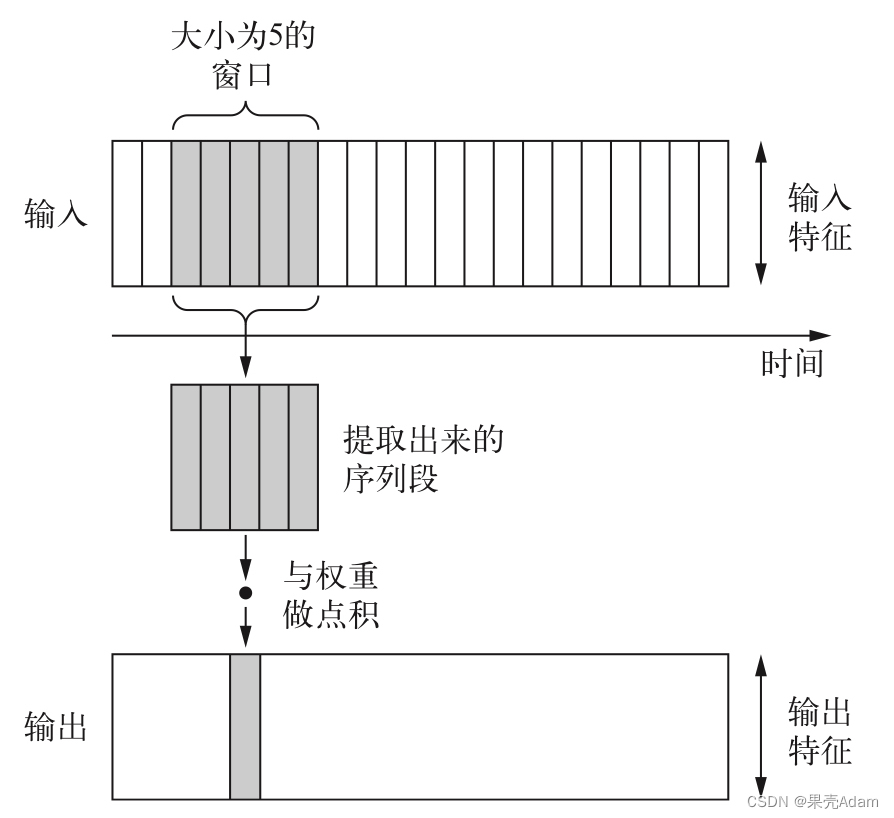
二:序列数据的一维池化
一维也可以做池化运算:从输入中提取一维序列段,然后输出其最大值或平均值。用于降低一维输入的长度。
三:一维卷积代码
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.utils import pad_sequences
import numpy as np
np.set_printoptions(threshold=np.inf)
max_features=10000
max_len=500
print('loading data...')
(x_train,y_train),(x_test,y_test)=imdb.load_data(num_words=max_features
)
print(len(x_train))
print(len(x_test))
print('pad sequences (samples x time)')
x_train=pad_sequences(x_train,maxlen=max_len)
x_test=pad_sequences(x_test,maxlen=max_len)
print('x_train',x_train.shape)
print('x_test',x_test.shape)
#一维卷积的构架与二维相同,它是Conv1D层和MaxPoolong1D层的堆叠,最后是一个全局池化层或Flatten层,将三维输出转换为二维输出,可以向模型中添加一个或多个Dense层
from keras.models import Sequential#用于构建线性堆叠神经网络模型
from keras import layers
from keras.optimizers import RMSprop #优化器,负责根据损失函数的梯度调整网络参数,以最小化损失
model=Sequential()
model.add(layers.Embedding(max_features,128,input_length=max_len))
model.add(layers.Conv1D(32,7,activation='relu'))
model.add(layers.MaxPool1D(5))
model.add(layers.Conv1D(32,7,activation='relu'))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(lr=1e-4),loss='binary_crossentropy',metrics=['acc'])
history=model.fit(x_train,y_train,epochs=4,batch_size=128,validation_split=0.2)
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label='T acc')
plt.plot(epochs,val_acc,'b',label='V acc')
plt.title('T and V acc')
plt.legend()
plt.show()
时间原因,epochs只取了4。可以将以上结果与循环网络进行比较,发现验证精度相似,更让我们确信,在单词级的情感分类任务上,一维卷积可以代替RNN,而且速度快,计算代价低。
四、结合CNN和RNN来处理长序列
一维卷积神经网络分别处理每个输入序列段,所以它对时间步的顺序不敏感,与RNN不同。为了识别长期的模式,可以将许多卷积层和池化层堆叠在一起,这样上面的层能够观察到原始输入中更长的序列段,但这仍不是一种引入顺序敏感性的好方法。可以选择结合卷积神经网络的速度和轻量与RNN的顺序敏感性,可以在RNN前使用一维卷积作为预处理步骤。对于那些非常长,以至于RNN无法处理的序列,这个方法嘎嘎好用!卷积网络可以将长的输入序列转换为高级特征组成的更短序列(下采样)。然后提取的特征组成的这些序列成为网络中RNN的输入。我们将这个方法运用到温度预测数据集,该数据集在作者上一篇博客介绍过了,这里就不进行介绍。这种方法允许操作更长的序列,所以我们可以查看更早的数据(通过增大数据生成器的lookback参数)或查看分辨率更高的时间序列(通过减小生成器的step参数)。这里将step减半,得到时间序列的长度变为之前的两倍,温度数据的采样频率变为每30min一个数据点。
import os
import numpy as np
data_dir='jena_climate_2009_2016'
fname=os.path.join('jena_climate_2009_2016.csv')
f=open(fname)
data=f.read()
f.close()
lines=data.split('\n')#按照指定的分割符进行分割
header=lines[0].split(',')
lines=lines[1:]
print(len(header)) #15
print(len(lines)) #420451
import numpy as np
float_data=np.zeros((len(lines),len(header)-1))
#print(float_data.shape) #(420451,14)
for i ,line in enumerate(lines):
values=[float(x) for x in line.split(',')[1:]]
float_data[i,:]=values
#print(float_data.shape) #(420451,14)
from matplotlib import pyplot as plt
temp=float_data[:,1]#温度,单位摄氏度
plt.plot(range(1440),temp[:1440])
plt.show()
#data=0 浮点数数据组成的原始数组
lookback=720#输入数据应该包括过去多少个时间步
steps=6#数据采样的周期
dealy=144#目标应该在未来多少个时间步之后
#数据标准化
mean=float_data[:200000].mean(axis=0)
float_data-=mean
std=float_data[:200000].std(axis=0)
float_data/=std
#生成时间序列样本及其目标的生成器
def generator(data,lookback,delay,min_index,max_index,shuffle=False,batch_size=128,step=6):#迭代器,用于生成样本和目标数据
if max_index is None:
max_index=len(data)-delay-1#如果没有指定最大索引,则将其设置为数据长度减去延迟1天
i=min_index+lookback
while 1:
if shuffle:
rows=np.random.randint(min_index+lookback,max_index,size=batch_size)
else:
if i+batch_size>=max_index:
i=min_index+lookback
rows=np.arange(i,min(i+batch_size,max_index))
i+=len(rows)
samples=np.zeros((len(rows),lookback//step,data.shape[-1]))
targets=np.zeros((len(rows),))
for j,row in enumerate(rows):
indices=range(row[j]-lookback,rows[j],step)
samples[j]=data[indices]
targets[j]=data[row[j]+delay][1]
yield samples,targets #无限生成样本和目标数据
step=3
lookback=720
delay=144
train_gen=generator(float_data,lookback=lookback,delay=delay,min_index=0,max_index=200000,shuffle=True,step=step)
val_gen=generator(float_data,lookback=lookback,delay=delay,min_index=200001,max_index=300000,step=step)
test_gen=generator(float_data,lookback=lookback,delay=delay,min_index=300001,max_index=None,step=step)
val_steps=(300000-200001-lookback)//128
test_steps=(len(float_data)-300001-lookback)//128
#下面是模型,开始是两个Conv1D,然后是一个GRU
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model=Sequential()
model.add(layers.Conv1D(32,5,activation='relu',input_shape=(None,float_data.shape[-1])))
model.add(layers.MaxPool1D(3))
model.add(layers.Conv1D(32,5,activation='relu'))
model.add(layers.GRU(32,dropout=0.1,recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(),loss='mae')
history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=4,validation_data=val_gen,validation_steps=val_steps)
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label='T acc')
plt.plot(epochs,val_acc,'b',label='V acc')
plt.title('T and V acc')
plt.legend()
plt.show()从验证随时来看,这种架构的效果不如只用正则化GRU,但速度快。他查看了两倍的数据量,在本例可能用处并不能完全发挥出来,但对其他某些数据可能效果非常好!
欢迎读者批评指正,有任何问题可以评论发私信等!感谢读者,恳求点赞+关注,谢谢啦!
以下是我的github主页,欢迎光临!















 2610
2610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









