







一、实验目的
递归下降语法分析
二、实验题目

三、分析与设计

四、源代码
#include <iostream>
#include <fstream>
#include <cstring>
#include <string>
#include <conio.h>
#define digit 1 // 1数字
#define op 2 // +-*/()#
#define Hh 3 // 3Hh
#define AF 4 // 4A-F
#define letter 5 // 5其它字母
using namespace std;
char sym; // 保存当前读入字符
string line; // 保存读入的一行表达式
int cur; // 表达式字符串中的当前下标
int error; // 错误标志。0:正确; -1:错误
char q; // 指向输入符号串中当前的字符
char word[20]; // 存储当前识别的单词
int state; // 表示所处的状态
int i; // 单词的下标
int E(), E1(), T(), T1(), F(); // 函数声明
char read(string line, int k);
string change_i(string words); // 将含有十进制或十六进制数的表达式转换为用i代替的表达式
int isDigitOrChar(char ch);
int main() {
ifstream fin("test.txt");
if (!fin.is_open()) {
cout << "open file error." << endl;
_getch();
return -1;
}
while (getline(fin, line)) {
puts("------------------------------------");
cur = 0;
error = 0;
string temp = line;
line = change_i(line);
if (line == "-1") {
cout << temp << " is not a valid express." << endl;
continue;
}
cout << "Output string is: " << line << endl;
sym = read(line, cur); // 读取第一个字符
E();
if (error == -1)
cout << temp << " is not valid." << endl;
else if (error == 0) {
if (cur + 1 < line.size()) { // 未成功匹配提前退出认定为无效
cout << temp << " is not valid." << endl;
}
else {
cout << temp << " is valid." << endl;
}
}
}
fin.close();
_getch();
return 0;
}
// 递归分析函数实现
int E() { // E->TE'
T();
E1();
return 0;
}
int E1() { // E'->+TE'|-TE'|ε
if (sym == '+' || sym == '-') {
cur++;
sym = read(line, cur);
T();
E1();
}
else if (sym == '#' || sym == ')')
return 0;
else
error = -1;
return 0;
}
int T() { // T->FT'
F();
T1();
return 0;
}
int T1() { // T'->*FT'|/FT'|ε
if (sym == '*' || sym == '/') {
cur++;
sym = read(line, cur);
F();
T1();
}
else {
if (sym == '#' || sym == ')' || sym == '+' || sym == '-')
return 0;
else
error = -1;
}
return 0;
}
int F() { // F->(E)|i
if (sym == 'i') {
cur++;
sym = read(line, cur);
}
else if (sym == '(') {
cur++;
sym = read(line, cur);
E();
if (sym == ')') {
cur++;
sym = read(line, cur);
}
else
error = -1;
}
else
error = -1;
return 0;
}
char read(string line, int k) {
return line[k];
}
int isDigitOrChar(char ch) {
if (ch >= 48 && ch <= 57) // 数字
return digit;
else if (ch == 72 || ch == 104) // H or h
return Hh;
else if ((ch >= 65 && ch <= 70) || (ch >= 97 && ch <= 102)) // 字母A,B,C,D,E,F
return AF;
else if ((ch >= 65 && ch <= 90) || (ch >= 97 && ch <= 122)) // 除A~F外的其它字母
return letter;
else if (ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == '(' || ch == ')' || ch == '#')
return op;
}
// 将含有十进制或十六进制数的表达式转换为用i代替的表达式
string change_i(string words) {
memset(word, 0, sizeof word);
state = 0;
i = 0;
cout << "Input string is: " << words << endl;
string result = "";
int cnt = 0;
q = words[cnt++];
while (cnt <= words.size()) {
// 先判断状态,再判断字符
switch (state) {
case 0: // 0状态
switch (isDigitOrChar(q)) {
case digit: // 数字
word[i++] = q;
state = 2; // 转移到2状态
break;
case Hh: // H or h
case AF: // 字母A,B,C,D,E,F or a,b,c,d,e,f
case letter: // 字母
word[i++] = q;
state = 1;
break;
case op: // 操作符
result += q;
state = 0;
break;
default: // 其它(非法字符 )
word[i++] = q;
state = 5;
}
break;
case 1: // 1状态
switch (isDigitOrChar(q)) {
case Hh: // 当前状态遇到字母、数字往下读入
case AF:
case digit:
case letter:
word[i++] = q;
state = 1;
break;
case op: // 读入完毕,识别为标识符
word[i] = '\0';
printf("%s is an identifier.\n", word);
//result += "i";
memset(word, 0, sizeof word);
i = 0;
state = 0;
break;
default:
word[i++] = q;
state = 5;
}
break;
case 2: // 2状态
switch (isDigitOrChar(q)) {
case digit: // 若为数字,不改变状态往下读入
word[i++] = q;
state = 2;
break;
case Hh: // 若为Hh,转移至状态3
word[i++] = q;
state = 3;
break;
case AF: // 若为AF,则有可能是16进制,转移至状态4
word[i++] = q;
state = 4;
break;
case op: // 成功识别为整数
word[i] = '\0';
printf("%s is an Integer.\n", word);
result += "i";
result += q;
//cout << result << endl;
memset(word, 0, sizeof word);
i = 0;
state = 0;
break;
default:
word[i++] = q;
state = 5;
}
break;
case 3: // 3状态
switch (isDigitOrChar(q)) {
case op: // 识别为16进制数
word[i] = '\0';
printf("%s is a Hex digit.\n", word);
result += "i";
result += q;
//cout << result << endl;
memset(word, 0, sizeof word);
i = 0;
state = 0;
break;
default:
word[i++] = q;
state = 5;
}
break;
case 4: // 4状态
switch (isDigitOrChar(q)) {
case digit: // 若为数字或A~F,仍为状态4,往下读入
case AF:
word[i++] = q;
state = 4;
break;
case Hh:
word[i++] = q;
state = 3;
break;
case op: // 如果16进制没有以h或H结尾,转移至错误状态
state = 5;
cnt--;
break;
default:
word[i++] = q;
state = 5;
}
break;
case 5: // 出错状态
if (isDigitOrChar(q) == op) { // 若为空格,则识别为非标识符
word[i] = '\0';
printf("%s is not an identifier.\n", word);
memset(word, 0, sizeof word);
i = 0;
state = 0;
result = "-1";
return result;
}
else { // 出错序列还未读取完毕,往下读入
word[i++] = q;
q = words[cnt++];
continue;
}
break;
}
q = words[cnt++]; // 指针下移(指向输入符号串中的下一个字符)
}
return result;
}
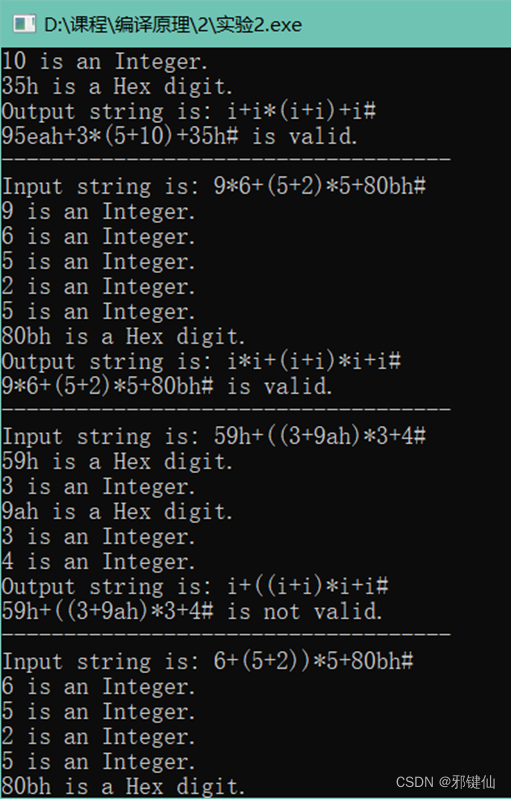
五、实验结果(运行截屏)
六、实验总结
(1)重点与难点
如何将字符转为i
1c(中如何避免(的输入
(2)存在的不足
本来是将字符的替换与判断单独封装为了一个函数justice,但是在主函数调用的时候,运行不出结果,找了一个多小时的原因,没找出来,所以只好让他成为主函数,递归分析直接加到了字符判断函数的后面,显得十分冗长
实验要求没理解透,将实验分成了两个编写,并且在转换为i表达式时,()的更改发生了错误,后续经同学提示发现错误并改正
(3)未来改进方案
继续查找资料,解决上述提到的运行失败的问题
(4)结论(开发体验、收获、感想等)
通过本次实验,我学会了先改写文法,再判断是否符合文法要求的方法编写一个简单的自顶向下语法分析器。本次实验我还学会了如何通过c语言语法,识别一个txt文件,并进行逐行语句的输入。此外,我通过与实验1的联合实验,巩固复习了词法分析器的分析与编写。最后,通过本次实验的实践,我初步学会了strcat语句的使用法则。
七、测试用例
7+9*2#
80+5eH+(6+1)*2+4h#
95eah+3*(5+10)+35h#
9*6+(5+2)*5+80bh#
59h+((3+9ah)*3+4#
6+(5+2))*5+80bh#















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









