







import pandas as pd
import datetime
def pro_in(id):
# pro_dict = {11:"北京",12:"天津"}
pro_dict = {
'11': "北京",
'12': "天津",
'13': "河北",
'14': "山西",
'15': "内蒙古",
'21': "辽宁",
'22': "吉林",
'23': "黑龙江",
'31': "上海",
'32': "江苏",
'33': "浙江",
'34': "安徽",
'35': "福建",
'36': "江西",
'37': "山东",
'41': "河南",
'42': "湖北",
'43': "湖南",
'44': "广东",
'45': "广西",
'46': "海南",
'50': "重庆",
'51': "四川",
'52': "贵州",
'53': "云南",
'54': "西藏",
'61': "陕西",
'62': "甘肃",
63: "青海",
64: "宁夏",
65: "新疆",
71: "台湾",
81: "香港",
82: "澳门",
91
: "国外"
}
if pro_dict.get(id) is not None:
return pro_dict[id]
else:
return "无"
if __name__ =="__main__":
df = pd.read_csv(r'D:\test\re_an.txt',names = ['idnumber'])
print(df.dtypes)
df1 = df['idnumber']
df['pro_vince'] = df1.str[0:2]
# df['pro_vince'] = pd.to_numeric(df['pro_vince'])
df['year'] = df1.str[6:10]
print(df['year'].dtype)
df['year'] = pd.to_numeric(df['year'])
df['month'] = df1.str[10:12]
df['month'] = df['month'].astype(int)
df['sex'] = df1.str[16:17]
# 改变数据类型
df['sex'] = pd.to_numeric(df['sex'])
df['省份'] = df['pro_vince'].apply(pro_in)
# print(df['省份'])
df['性别'] = df['sex'].apply(lambda x:0 if x%2==0 else 1)
# print(df['性别'])
now = datetime.datetime.now()
now_year = now.year
now_month = now.month
print(type(now_year))
df['year1'] = now_year-df['year']-1
df['month1'] =df['month'].apply(lambda x:1 if x < now_month else 0)
df['年龄'] = df['year1']+df['month1']
df2 = df[['省份','年龄','性别']]
df2.to_csv(r'D:\test\re__an_te1.txt')
print('finished')不用for循环,这是用另外一种方法提取年龄,性别,省份数据
知识点一:
这段直接用if pro_dict[id] is not None 报错keyerror'43',查了一下,发现如果不确定key在字典里,要用dict.get(),上一个代码没有报错是因为所有的key 都在字典里;
if pro_dict.get(id) is not None:
return pro_dict[id]知识点二: 新建了太多列,但是仅要保留某些列的数据
使用场景一:如果有一堆工作簿,每个工作簿仅想要部分列的数据
先遍历文件夹,然后读取文件的时候指定列数即可
试了一下用txt不支持这个功能?目前试了Excel和csv可以

使用场景二:跟我这次情况一样,新建了太多辅助列,返回的文件不要这些列:
保留想要的列
方法1:
df=df.loc[:,[‘name1’,‘name2’,‘name3’]]
方法2:
df2=df[[‘name1’,‘name2’,‘name3’]]
删除指定列
方法1:指定列名删除
df.drop([‘name1’,‘name2’],axis=1,inplace=True)
方法2:指定列数删除
df.drop(df.columns[0:n], axis=1, inplace=True)
————————————————
版权声明:本文为CSDN博主「葵青」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_50723672/article/details/115203198
知识点三:数据类型错误
注意数据类型不一致导致的错误,str类型无法加减,会报错;int32和int64似乎是可以加减的?
最好开始处理数据前就先查看一下各个列的数据类型,这样更清楚;查看整个表的数据类型:df.dtypes,或者用df.info() 也行;查看某一列,则是,df['year'].dtype
pandas里的数据类型转换
3.1、整个转换数据类型
试了一下,如果整个文本转换,比较方便,但有局限,比如有文本和数字,要都转为int会报错;
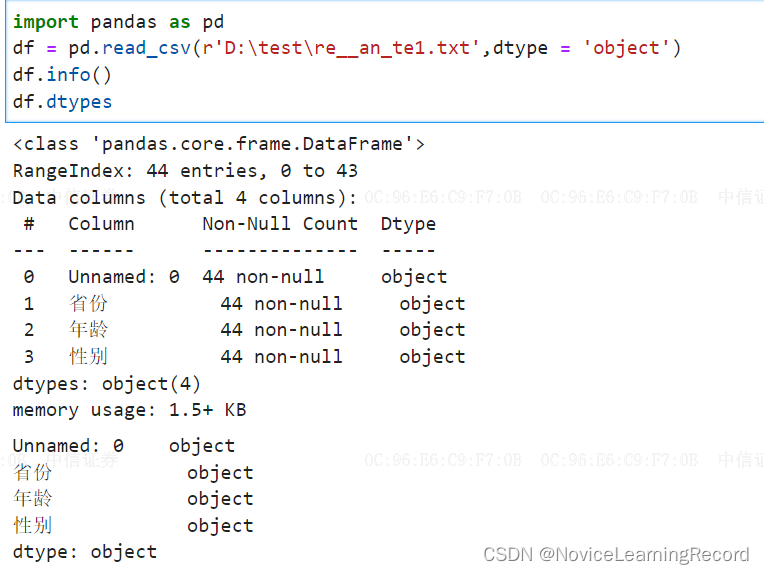
3.2、单列或者多列转换为指定的数据类型
3.2.1、单列:str转换成数字类型:pd.to_numeric(data),返回的数据为float64或者int64
把某列转成:df['year'] = pd.to_numeric(df['year'])
如果有部分数据无法转为int类型,可以用参数error来设定为nan,或者直接忽略
df['年龄2'] = pd.to_numeric(df['年龄'],errors = 'coerce')
df['年龄1'] = pd.to_numeric(df['年龄'],errors = 'ignore')
df['年龄2']的类型是float64,但是df['年龄1']的数据类型变成了object


3.2.2、 多列转换用apply函数来转换,用ignore
df1 = df[['年龄','性别']].apply(pd.to_numeric,errors = 'ignore')
转换整个表
df = df.apply(pd.to_numeric,errors = 'ignore')
astype也可以转换数据类型:
astype的参数如果是int,float 同理,用不用引号都可,但是如果用具体的int32,int64则要,不然会报错
df['month'] = df['month'].astype(int32)
df1 = df[['年龄','性别']].astype(int32)
多列,还可以指定转换
df1 = df.astype({'年龄':'int32','性别':'int64'},errors = 'ignore')














 1790
1790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









