







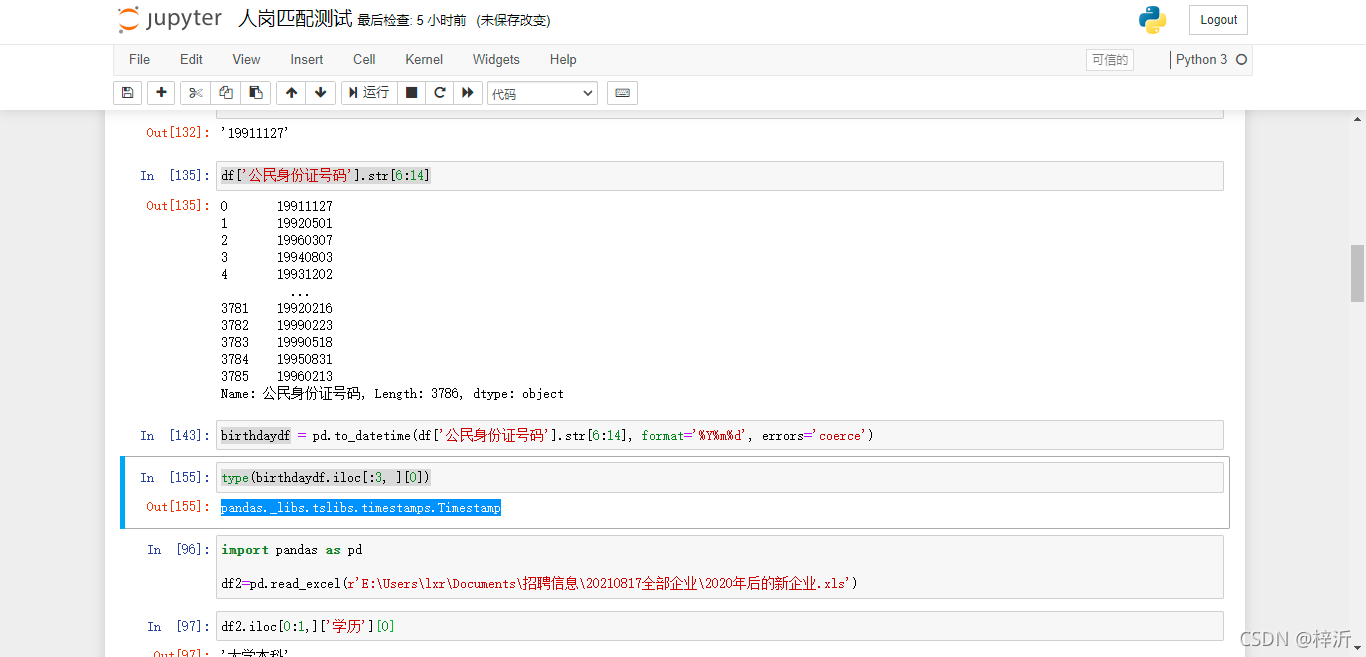
df['份证号码'].str[6:14]
# 取df表中的'公民身份证号码'列的全部数据,转换为字符串str类型,再截取第6+1到14+1(不含)个字符
# 110000 10001231 000x
pd.to_datetime(df['份证号码'].str[6:14], format='%Y%m%d', errors='coerce')
# 将8为日期字符串转为日期格式 类型为pandas._libs.tslibs.timestamps.Timestamp
(20210129已解决)Pandas通过某列值包含特定字符串过滤行_漫步量化-CSDN博客
很简明扼要,很符合python的风格。
pandas把nan替换_Yzy_gold的博客-CSDN博客
数据挖掘:使用python+pandas处理身份证号数据,获得对应省份籍贯、生日和性别 - 知乎
(这里的方法太传统不可取,只有string[6:14]有用)
使用Python将数字转换为日期格式 - 问答 - Python中文网
pandas字符串转日期函数:
df['col'] = pd.to_datetime(df['col'], format='%d%m%Y', errors='coerce')python数据分析之pandas数据选取:df[] df.loc[] df.iloc[] df.ix[] df.at[] df.iat[] - 奥辰 - 博客园
这个非常常用,分类讲解的很细,但是iloc我还是没有搞懂,有些情况下不好用。
交集
pd.merge(df1,df2)从df数据种取nan的行
df2[df2['单位类型'].isna()]dataframe, 查看有nan的行,和不含有nan的行_九代-玄光的博客-CSDN博客
将某列中值为nan的行填充为0
df2[['最低年龄','最高年龄']] = df2[['最低年龄','最高年龄']].fillna(0)
# 这样填充无法筛选某行
df.fillna('',inplace=True)
#df2[['最低年龄','最高年龄']].fillna('',inplace=True) 这样写语法报警告使用fillna()在其他列中满足某些条件时如何在列中插入值 - IT屋-程序员软件开发技术分享社区
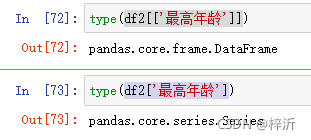
df2.loc[:,['最高年龄']]
df2[['最高年龄']]
# 区别是带[]输出df,不带[]输出series
df2.loc[:,'最高年龄']
df2['最高年龄'] 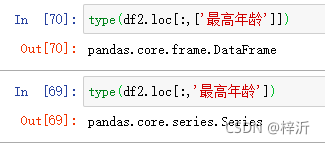
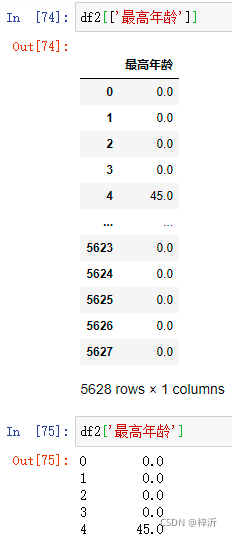
想过滤最高年龄列为0的数据,将0改为60,不熟悉的情况下,想先过滤年龄为0的行,在通过loc查出单列,结果报错。正确写法是,通过loc[,]逗号左边过滤出符合条件的行,逗号右边过滤出指定的列,再为该列统一赋值即可。
df2.loc[df2['最高年龄']==0,'最高年龄']=60
# 错误写法
# df2[df2['最高年龄']==0].loc(['最高年龄'])过滤符合某个年龄段的行
df[(df['年龄']>=df2['最低年龄'][0])&(df['年龄']<=df2['最高年龄'][0])]其中 & 表示“与”,| 表示“或”
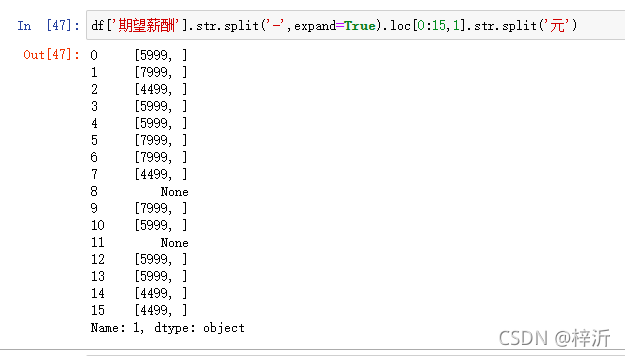
分裂后扩展到新列:
# split(...,expand=True)可以扩展一个新列
dfsplit = df['期望薪酬'].str.split('-',expand=True)
df['底薪']=dfsplit.loc[:,0]
df['顶薪']=dfsplit.loc[:,1].str.split('元',expand=True).loc[:,0]如果参数不加expand=True,分裂后会产生一个数组:

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









