







介绍
什么是Kafka?
官网是这么介绍的:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines,streaming analytics, data integration, and mission-critical applications.
(Apache Kafka是一个开源分布式事件流平台,已被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。)
说的更加具体一点:
Kafka 是由Apache软件基金会开发的分布式流处理平台,旨在处理和存储实时数据流。它最初是由LinkedIn开发的,后来成为Apache项目,得益于其卓越的性能、可伸缩性和容错性,Kafka在大数据领域得到了广泛的应用。
关键特性:
-
分布式架构: Kafka采用分布式架构,允许数据在多个节点上进行分布式处理和存储。
-
高吞吐量: Kafka具有出色的吞吐量,能够处理大规模数据流而不降低性能。
-
持久性: 数据在Kafka中被持久化存储,即使在消费之后仍然保留,使其成为可靠的数据存储和传输工具。
-
水平可伸缩: Kafka的水平可伸缩性使其能够轻松扩展以适应数据量的增长,通过增加节点来提高性能。
-
多订阅者模型: Kafka采用发布/订阅模型,允许多个消费者同时订阅并消费相同的数据流。
-
容错性: 通过数据分区和副本的方式,Kafka确保在节点故障时不会丢失数据。
应用场景:
-
日志聚合: 用于收集和聚合分布式系统生成的日志。
-
流处理: 支持实时数据流处理,通过Kafka Streams等工具进行复杂的数据处理。
-
事件溯源: 记录系统中发生的所有事件,可用于溯源、监控和调试。
为什么选择Kafka?
高吞吐量:
Kafka以其卓越的吞吐量而闻名。它能够轻松地处理数以千计的事件每秒,使其成为处理大规模数据流的理想平台。高吞吐量意味着能够更迅速地处理和传递数据,从而实现更实时的数据处理。
可伸缩性:
Kafka的可伸缩性使其能够适应数据量的增长。通过简单地添加新的节点或分区,你可以水平扩展Kafka集群,而不需要停机或影响现有的生产和消费过程。
持久性和容错性:
Kafka设计用于持久性存储,确保即使在节点故障时也不会丢失数据。数据以分区和副本的形式存储在多个节点上,使得Kafka在面对硬件故障或其他问题时仍然可靠。
多订阅者模型:
Kafka采用发布/订阅模型,支持多个消费者同时订阅相同的数据流。这种模型使得构建具有高度灵活性和可扩展性的系统变得更加容易。
水平可伸缩的消费者模型:
Kafka允许用户水平扩展消费者,以处理更大的数据流。这是通过增加分区和副本,使得多个消费者能够并行地处理消息,从而提高整体的处理能力。
社区支持和成熟性:
Kafka是一个开源项目,拥有庞大的社区支持。它经历了多个版本的迭代和改进,成为一个稳定、可靠的分布式系统。
生态系统丰富:
Kafka不仅仅是一个消息代理,还有许多与其配套的工具和框架,如Kafka Streams用于流处理,Confluent Schema Registry用于数据模式的管理,以及Kafka Connect用于与外部系统的集成。
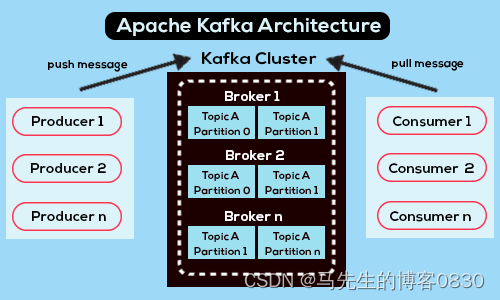
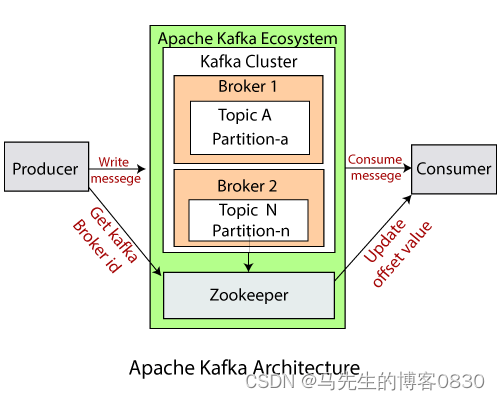
Kafka组件详解
Zookeeper
Zookeeper 是一个开源的分布式协调服务,被广泛应用于分布式系统中,包括Kafka。在Kafka中,Zookeeper扮演着关键的角色,用于管理和维护Kafka集群的状态信息、配置和领导者选举等。
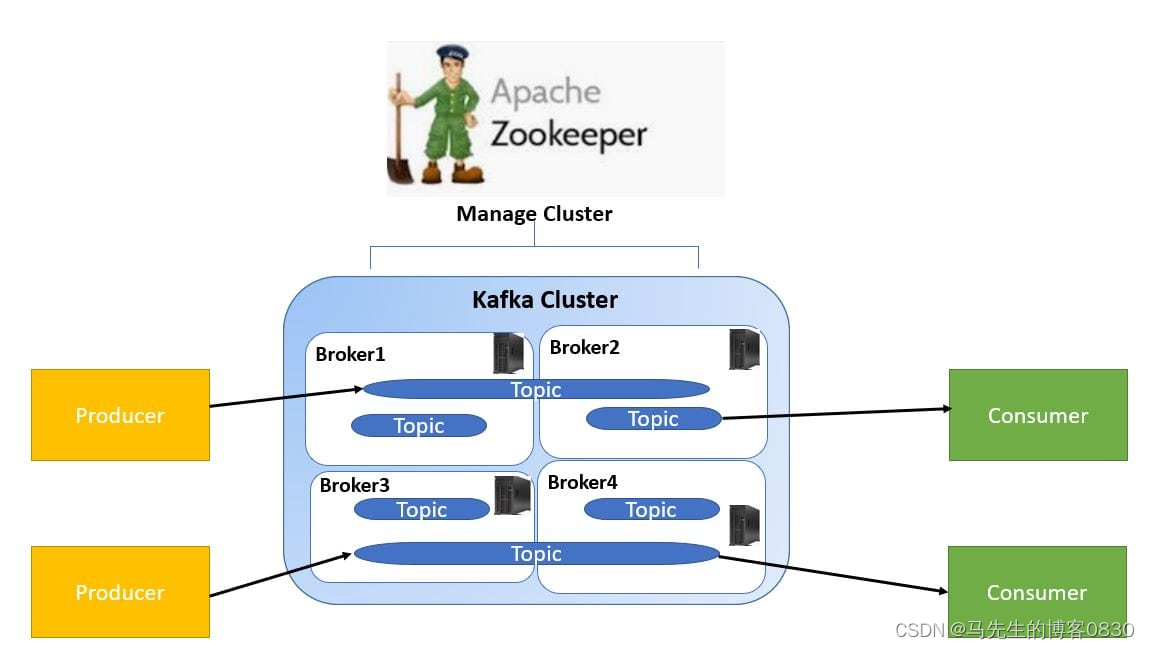
关键作用:
-
集群协调: Zookeeper协助Kafka集群中的各个节点进行协调工作,确保各个节点的状态和配置信息一致。
-
领导者选举: 在Kafka集群中,每个分区都有一个领导者(Leader),负责管理分区的读写操作。Zookeeper协助进行领导者的选举,确保系统的高可用性。
-
元数据存储: Kafka使用Zookeeper存储集群的元数据信息,包括主题(Topics)、分区(Partitions)以及分区的领导者等。
-
动态集群管理: Zookeeper能够动态地监测集群中节点的加入和退出,并通知集群中的其他节点做出相应的调整。
Zookeeper工作原理:
Zookeeper采用分布式一致性算法,确保在集群中的各个节点之间达成共识。其工作原理包括:
-
领导者选举: Zookeeper集群中的节点会通过投票产生一个领导者。领导者负责处理写操作,而其他节点则负责读操作。
-
分布式锁: Zookeeper提供了分布式锁的机制,确保在分布式环境中的资源同一时刻只能被一个节点访问。
-
顺序一致性: Zookeeper保证所有的节点对数据的读写操作都是顺序一致的,即节点在读取到的数据是最新的。
在Kafka中的应用:
在Kafka集群中,Zookeeper的连接信息通常在Kafka配置文件中进行配置。Kafka Broker在启动时会与Zookeeper建立连接,注册自己的信息,参与领导者选举等活动。
配置示例(Kafka server.properties):
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
Zookeeper和Kafka之间的协作使得Kafka集群能够动态地适应变化、保持一致性,并确保高可用性的运行。
在实际搭建Kafka环境时,首先需要搭建和配置Zookeeper集群,然后再启动Kafka Broker节点。这样,Zookeeper和Kafka共同协作,构建起一个稳定可靠的分布式实时数据处理平台。
Broker
Broker 是Kafka集群中的一个节点,是实际处理数据的服务器。在Kafka中,多个Broker组成一个集群,协同工作以提供高性能的数据处理和存储服务。
关键作用:
-
消息存储和处理: Broker负责存储和处理Kafka中的消息。每个Broker都管理着一个或多个分区,这些分区中存储着消息的副本。
-
消息发布和订阅: 生产者将消息发布到Broker的主题(Topic),而消费者则从这些主题订阅并消费消息。
-
分区和副本管理: Broker负责管理分区,以提高并行性和可伸缩性。每个分区的数据会在多个Broker节点上进行复制,以确保数据的持久性和容错性。
-
领导者选举: 对于每个分区,会有一个Broker被选举为领导者,负责处理分区的读写操作。其他副本则作为备份。
Broker工作原理:
-
分布式存储: 每个Broker节点都存储着部分或全部的主题分区,以实现数据的分布式存储。
-
消息路由: 当生产者发送消息时,Broker根据消息的主题和分区信息将消息路由到相应的分区。
-
副本同步: 分区的数据会在多个Broker节点上进行同步,以确保数据的冗余备份。这保证了在节点故障时不会丢失数据。
-
领导者选举: 每个分区会有一个Broker被选举为领导者,处理读写操作。其他节点则作为副本,负责备份数据。
在Kafka中的应用:
在Kafka集群中,每个Broker都有一个唯一的标识(Broker ID)。生产者和消费者通过连接到任何一个Broker就能够与整个集群进行通信,因为Broker之间会相互转发消息。
配置示例(Kafka server.properties):
broker.id=1
listeners=PLAINTEXT://your_broker_host:9092
在配置文件中,broker.id用于标识每个Broker的唯一性。listeners指定了Broker监听的连接地址和端口。
在构建Kafka集群时,你可以在不同的机器上启动多个Broker,它们将协同工作以提供高性能、可伸缩和容错的实时数据处理服务。每个Broker都是整个Kafka架构中不可或缺的组成部分。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7921
7921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









