










Hive查询分析计算案例:股票分析
案例需求:
本案例是对单支股票一年中每日交易的数据处理,形成K线分析,重点在于前期数据规整处理与导入导出,从数据仓库方案的设计,涉及Hive优化操作,关系型数据库的导入,使用数据可视化方式的直观展示,并对数据进行进一步的分析。

解决思路:
(1)数据采集与清洗
通过爬虫或者金融终端获取股票数据,得到一张excel或者txt的数据,对数据进行初步的清洗整理,最后将数据传输到linux上。
(2)数据分析
通过语句建立外部表,通过HiveQL语句将数据导入,通过逻辑处理,建立分区,针对分区表,理解分区表在Hadoop文件系统中的存在方式,对数据进行分类存放,提高查询效率和准确性,在建立分区表时注意Hive数据倾斜和Hive执行性能的优化,从而实现Hive语句调用MapReduce的运行,将处理后的数据导入MySQL,再次进行逻辑处理。
(3)数据可视化
通过Tableau Desktop可视化工具对得到的数据进行可视化。
一、数据采集与清洗
这里的话建议大家用python进行数据的采集,因为本人着急想拿些数据进行操作,所以选择了一些金融工具!
1、下载Choice金融终端

2、通过Choice金融终端的excel插件获取一年的股票数据


3、分析数据,判断以哪一字段进行分区统计
选定以代码作为分区

4、对需要操作的字段进行去除特殊符号的操作
由于分区字段不能有特殊符号,所以将“.”给替换成空

5、将数据到txt文件中,并将分隔符改为“,”

6、上传txt数据到虚拟机中

二、数据分析
1、设置mysql免密登录与编码格式
原因:由于我后面是通过shell脚本对数据进行操作的,所以免密模式会比较方便!
设置mysql免密模式
# mysql设置免密登录
vim ~/.my.cnf
# 内容如下
[mysql]
host=192.168.254.124
user=root
password=John123456

设置mysql编码格式
# mysql设置编码格式
vim /etc/my.cnf
# 内容如下:
[client]
default-character-set = utf8
[mysqld]
default-storage-engine = INNODB
character-set-server = utf8
collation-server = utf8_general_ci

查看mysql编码格式
# 重启mysql
systemctl start mysqld
# 登录mysql免密模式
mysql
# mysql客户端检查编码
show variables like '%char%';

2、启动mysql与hive
Slave2
# 由于设置了免密模式 所以不需要输入账号密码都可以登录
mysql
Slave1
# slave1服务器
cd /usr/hive/apache-hive-2.1.1-bin/
bin/hive --service metastore
Master
# master客户端
cd /usr/hive/apache-hive-2.1.1-bin/
bin/hive
3、hive创建数据库
create database hive_mysql;
4、创建外部表 并加载数据
# 建表
create external table if not exists stock_test(
sdate DATE,
num String,
name String,
opening_price DOUBLE,
max_price DOUBLE,
min_price DOUBLE,
closing_price DOUBLE
)
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")
;
# 加载数据
load data local inpath '/opt/software/stock_data.txt' into table stock_test;
5、创建分区表
create table if not exists stock(
sdate DATE,
name String,
opening_price DOUBLE,
max_price DOUBLE,
min_price DOUBLE,
closing_price DOUBLE
)
partitioned by (num String)
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")
;
6、从外部表分区插入数据
# 设置参数
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
# 从外部表插入数据
insert overwrite table stock
partition(num)
select sdate,name,opening_price,max_price,min_price,closing_price,num from stock_test;
7、运行自定义脚本 /mysqldata.sh 实现mysql按分区建表
创建mysqlcreate.sh脚本
# 创建/mysqlcreate.sh脚本
vim /mysqlcreate.sh
mysqlcreate.sh脚本内容如下:
#!/bin/bash
echo "-----------加载数据-----------"
hdfs dfs -ls /user/hive_remote/warehouse/hive_mysql.db/stock > /name.txt
sed -i '1d' /name.txt
echo "-----------正在建表-----------"
#创建数据库
HOME=/root mysql -e "create database IF NOT EXISTS hive_mysql default character set utf8 collate utf8_general_ci"
# 通过分区循环创建表
while read line
do
pname=${line#*=} #数据库中表的名称
echo "---创建$pname的mysql表---"
DBNAME="hive_mysql" #数据库名称
# 创建表
HOME=/root mysql hive_mysql -e "create table IF NOT EXISTS ${pname} ( sdate DATE, name VARCHAR(20), opening_price FLOAT(5,2), max_price FLOAT(5,2), min_price FLOAT(5,2), closing_price FLOAT(5,2) )character set utf8 collate utf8_general_ci"
echo "-----$pname表创建完毕-----"
done < /name.txt
给mysqlcreate.sh脚本设置权限并运行
# 设置权限
chmod +x /mysqlcreate.sh
# 运行脚本
/mysqlcreate.sh

8、运行自定义脚本hivedata.sh 实现通过sqoop将hive的数据传输给mysql
创建/hivedata.sh脚本
# 创建/hivedata.sh脚本
vim /hivedata.sh
内容如下:
#!/bin/bash
echo "-----------加载数据-----------"
hdfs dfs -ls /user/hive_remote/warehouse/hive_mysql.db/stock > /name.txt
sed -i '1d' /name.txt
echo "-----------传输数据-----------"
cd /usr/sqoop/sqoop-1.4.6/
# 通过分区来传输数据
while read line
do
pname=${line#*=} #数据库中表的名称
echo "-----------正在传输${pname}-----------"
# 传输数据
bin/sqoop export \
--connect "jdbc:mysql://slave2:3306/hive_mysql?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password John123456 \
--table ${pname} \
--fields-terminated-by ',' \
--export-dir /user/hive_remote/warehouse/hive_mysql.db/stock/num=${pname}
echo "-----------${pname}传输完毕-----------"
done < /name.txt
给hivedata.sh脚本设置权限并运行
# 设置权限
chmod +x /hivedata.sh
# 运行脚本
/hivedata.sh

9、查看mysql数据
通过Navicat Premium 12对mysql数据进行查看

三、数据可视化
1、打开Tableau Desktop,连接提前准备好的数据,新建工作表。

2、创建计算字段(“距离:最低价到最高价”):在数据窗格中,右击空白处,在下拉菜单中选择“创建”→“计算字段”,函数如下:[max_price]-[min_price]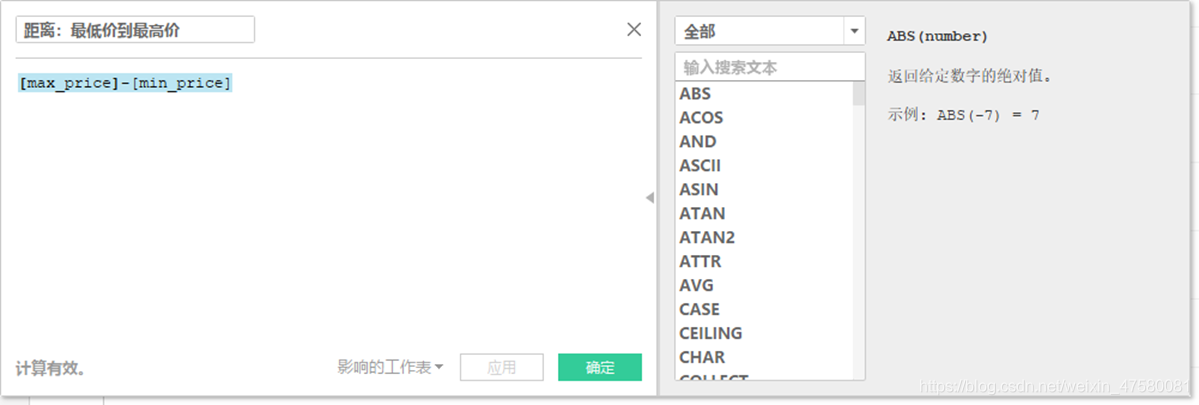
3、将维度“交易日期”拖放至于列,右击列上的“交易日期”胶囊,在下拉菜单中,选择“天”;重复操作一遍,再选择“离散”;
4、先将度量“最低价”拖放至行,右击列上的“最低价”胶囊,在下拉菜单中,选择“度量”-“平均值”;再将刚刚创建的计算字段“距离:最低价到最高价”拖放至“平均值(最低价)”标记卡的“大小”中,同时大小调成最小;
5、再创建3个创建计算字段
计算字段“距离:开盘价到收盘价”,函数如下:ABS([closing_price]-[opening_price])

计算字段“开盘价和收盘价取小”,函数如下:
IF [opening_price]-[closing_price]>0
then [closing_price]
else [opening_price]
END

计算字段“上升或下跌”,函数如下:
IF [closing_price]-[opening_price]>0
THEN “上升”
else “下跌”
END

6、创建一个甘特条形图
先将度量“开盘价和收盘价取小”拖放至行,右击列上的“开盘价和收盘价取小”胶囊,在下拉菜单中,选择“度量”-“平均值”;
再将刚刚创建的计算字段“距离:开盘价到收盘价”拖放至“平均值(最低价)”标记卡的“大小”中,同时大小调整适用;
并将刚刚创建的计算字段“上升或下跌”拖放至“平均值(最低价)”标记卡的“颜色”中,同时将上升调整为“红色”,下降调整为“绿色”。
7、创建一个蜡烛图
此时,图形纵轴上存在两个轴。
右击“平均值 距离:开盘价到收盘价”的纵轴,选择“双轴”,再选择“同步轴”,并取消“显示标题”。
最后,再花费一些时间,增加“最高价”、“最低价”等详细信息,检查一下字体、颜色等格式就大功告成。
8、图表展示:

四、心得体会
本案例从一开始的数据采集、数据清洗,再到数据分析,最后进行数据可视化。这也大概是数据分析的一个基本的流程,如果大家想做一行可以对这个案例进行一个入门的训练,后期再对这个案例进行完善优化,相信大家在数据分析的路上越走越远!hhh
由于本人对股票不是特别了解,自然没有股票爱好者更加清楚通过哪一指数判断其股票是否入手以及预测该股票未来的涨跌趋势。如果有对股票感兴趣的朋友们,可以花点时间,通过python提取更多的股票数据,再对数据进行进一步的分析,从而做下相应的决策



















 2653
2653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











