









excel文件操作
首先为什么要讲excel文件操作呢,因为一般用到的自动化框架中大部分都是用excel存放测试用例数据,是数据驱动的来源。
一、安装
本次分享的是通过openpyxl 这个模块来操作excel文件,所以首先需要安装该模块,通过下面命令安装。
pip install openpyxl
二、表结构
首先excel表格里有sheet表、单元格,在python里可以把整张excel表 sheet表 单元格都当做是个对象
我们这里先准备一份练手的excel文件并简单写一些数据进去。
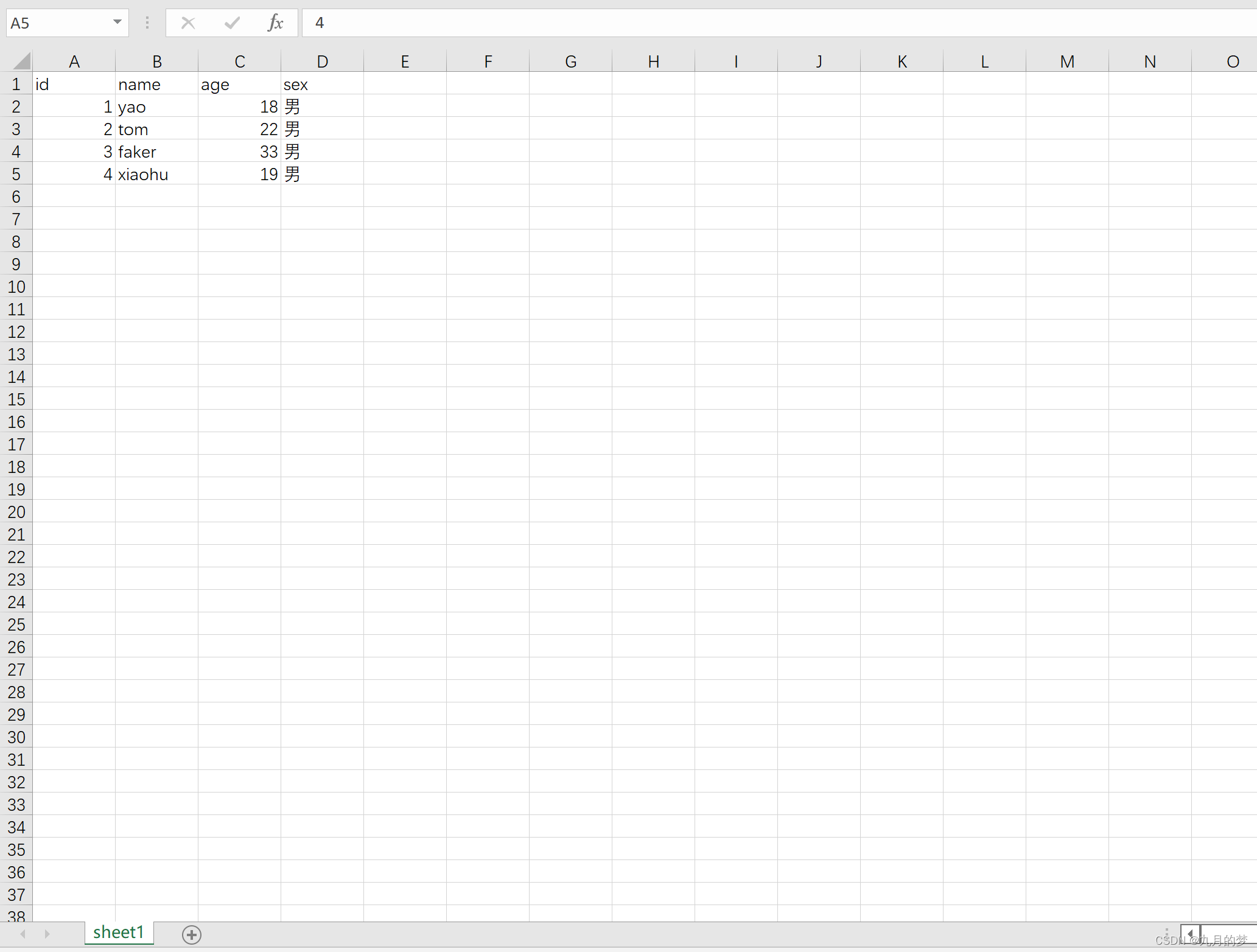
三、操作步骤
1、单独读取单元格值
from openpyxl import load_workbook
# 从openpyxl中导入 load_workbook
#load_workbook参数:
#filename:文件名称,
#read_only:只读模式
#data_only:读取数据的时候如果遇到计算公式是否要计算后再读取数据,False:读取未计算的结果(公式读出来) True:读取计算后的记过
#一般读取用例只需要用到filename这个参数就行,如果测试用例文件在当前目录下只需传文件名,
#如果在其他目录下需要传文件的绝对路径不然会提示找不到文件
# 获取表格对象
wb = load_workbook(filename="test.xlsx")
# 获取sheet对象
sheet = wb["sheet1"]
# 获取单元格对象
cell = sheet["B2"]
# 获取值
print(cell.value)
# 关闭数据流,注意:每次操作完文件后都需要关闭操作流,不然下次操作会报错。
wb.close()
运行结果如下:

可以看到这时候已经把test文件中sheet1表里的B2单元格已经读出来了。
2、行操作
# 获取行数据用的是iter_rows()这个方法这个方法有五个参数(min_row,max_row,min_col,max_col,values_only)
# min_row=None: 行的起始索引值,默认是1,必须是int类型
# max_row=None: 行的结束索引值,默认是1,必须是int类型
# min_col=None: 列的起始索引值,默认是1,必须是int类型
# max_col=None:列的结束索引值,默认是1,必须是int类型
# values_only=False:返回是对象 ,True:返回对应的值 默认是False 我们用到的时候需要设置成True
result = sheet.iter_rows(values_only=True) # 不填写min_row,max_row,min_col,max_col 则返回所有行列数据
print(result)
# 这里如果想用数据得转换成list 因为读取出来的数据默认是返回的内存地址需要转成list
print(list(result))
# 可遍历输出数据
# for i in list(result):
# print(i)
运行结果如下:

3、列操作(一般用不着,竖着读数据)
# 这里的操作参数和行操作一致
# 获取列数据用的是iter_cols()这个方法这个方法一样有五个参数用法与行操作一致(min_row=1,max_row=2,min_col=1,max_col=4,values_only=True)
result = sheet.iter_cols(min_row=1,max_row=2,min_col=1,max_col=4,values_only=True)
print(result)
print(list(result))
运行结果如下:

在做自动化测试的时候用到的都是行读取,列读取我们稍作了解就行。
但是我们现在通过行读取出来的数据并不能直接用作数据驱动使用,所以我们得进一步把数据处理成下面这种格式。
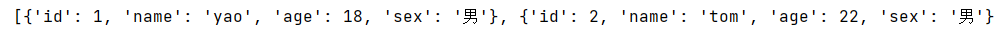
代码如下:
# 要把数据处理成上图的效果,一个字典对应一条用例 我们需要先把标题行 和用例数据先拆出来,并用zip函数进行压缩 再转成字典形式
result = list(sheet.iter_rows(values_only=True))
title = result [0] # 通过之前返回数据可以看出第一行是标题 我们直接索引获取第一行
datas = result [1:] # 剩下除了第一行就是用例数据了 直接截取
# print(title)
# print(data_list)
case_list=[] # 定义一个空列表保存用例
for case in datas:
res = dict(zip(title,case))
print(res)
case_list.append(res) # 将处理好的字典用例保存到列表中
print(case_list)# 打印结果
运行结果如下:

这时候已经可以拿到用例并处理成自己想要的格式了,但是这种代码比较low是写死的,这时候我们就可以封装一下,封装成类和方法
代码如下:
from openpyxl import load_workbook
import os
class GetExcel():
def __init__(self,filename,sheet_name):
# 获取用例文件绝对路径 casedata存放用例的目录 test是当前文件运行的目录 demo.py是封装的文件替换一下就是用例文件的绝对路径了
# 如果你用例文件和封装文件在同一个目录下 只需要传文件名即可
# filepath = os.path.abspath(__file__).replace("casedata","test").replace("demo.py",filename)
# print(filepath)
# 获取表
# self.wb = load_workbook(filename=filepath)
self.wb = load_workbook(filename=filename)
# 获取表对象
self.sheet = self.wb[sheet_name]
def __close_excel(self):
self.wb.close()
def __get_title_and_data(self):
"""
获取表头和用例并返回
:return:
"""
data_list = list(self.sheet.iter_rows(values_only=True))
title = data_list[0]
datas = data_list[1:]
return title,datas
def get_data(self):
"""
获取所有用例并保存到列表中
:return:
"""
title,data = self.__get_title_and_data()
case_list = []
for i in data:
res = dict(zip(title, i))
case_list.append(res)
self.__close_excel()
return case_list
if __name__ == '__main__':
cl = GetExcel('test.xlsx','sheet1')
res = cl.get_data()
print(res)
运行结果如下:

通过封装成类和方法,我们可以反复使用读取不同的excel表里用例数据。
下次分享如何用读取出来的数据通过数据驱动的方式去执行。














 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









