







并发数,线程数,吞吐量,每秒事务数(TPS)都是性能测试领域非常关键的数据和指标。
那么他们之间究竟是怎样的一个对应关系和内在联系?
测试时,我们经常容易将线程数等同于表述为并发数,这一表述正确吗?
本文就将对性能领域的这些关键概念做一次探讨。
文章可能会比较长,希望您保持耐心看完。
1. 走进开封菜,了解性能
①老王开了家餐厅
我们的主角老王

,在M市投资新开业了一家,前来用餐的顾客络绎不绝:
餐厅里有4种不同身份的人员:

用户一次完整的用餐流程如下:
顾客到店小二处付款点餐 => 小二将订单转发给后厨 => 后厨与备菜工配合,取材完成烹饪后交给小二 => 小二上菜,顾客用餐。
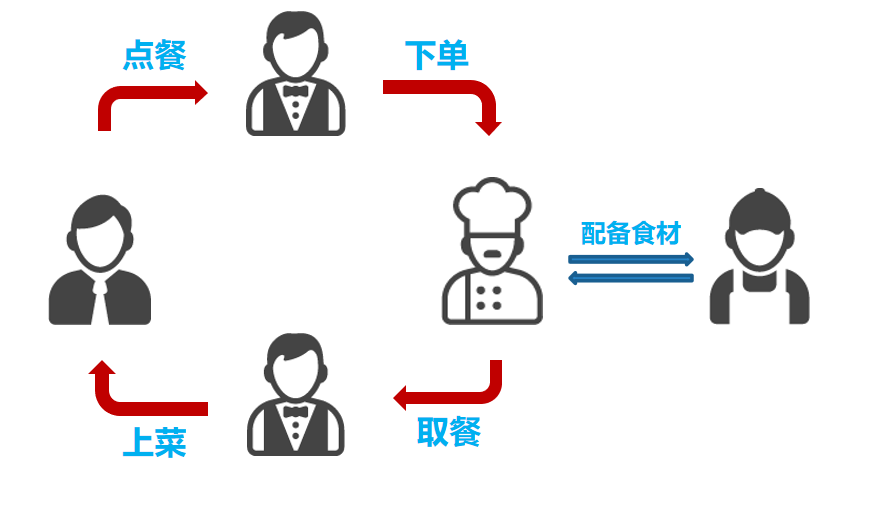
假设所有顾客都不堂食而是打包带走,也就是不考虑用户用餐时间。餐厅完成一次订单的时间是多久?
订单时间 = 顾客点单时间 + 前台接收转发时间 + 后厨取材烹饪时间 + 后厨交给服务员,服务员上菜时间。
说白了就是每个流程的耗时相加。
假设以上时间分别为1,1,5,1(分钟),那么一次订单的完成时间就是8分钟。
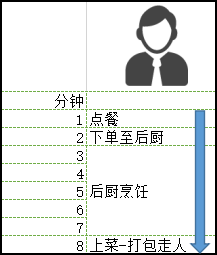
②问题来了
餐厅当然不可能只有一个人就餐,否则老王不要带着小姨子跑路。
所以我们接下来看多人就餐的情况。
假设同一时间点上有两人

就餐,会发生什么情况?
第一位用户与第一个场景一样,仍然是点单-下单-烹饪-上菜,8分钟后第一位顾客拿着打包的食物离开。
第二位用户则有所不同了。假设小二,厨师,备菜都只有一人,而且他们每个人同时只能处理一件事情。
那么第二位用户首先需要在点餐时等待小二1分钟,而后厨师烹饪第一位用户的菜时,没有任何人在为他服务。
我们来梳理一下这个过程中,每一分钟都发生了什么事情:
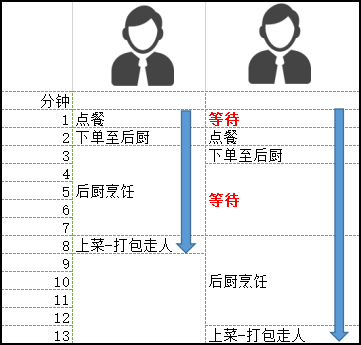
可以看到,两个顾客完成订单的总时长是13分钟。
继续推算我们发现,每增加一人总时长增加5分钟。
在当前的人员配置下,顾客越多,后来的顾客等待时间就越长。
③这还不是高峰期
如果餐厅在高峰时段只有两人用餐,那估计老王还得带着小姨子跑路。
实际一个运营得当的开封菜餐厅,在用餐高峰时段的顾客数可能高达百人。
那么问题来了,在某个普通工作日,12:00午饭时间,带着各种工牌的IT男女顾客蜂拥而至,餐厅瞬间挤进来一百人。
这个时候会发生什么?
现在餐厅已经完全服务不过来了,后续的顾客等的时间越来越长,最后一位可怜的顾客要等到差不多晚上8点才能吃到饭。
这显然是不可能的,实际上等了不到半个小时吃不上饭的顾客就都要走光了。
老王开始考虑如何应对营业高峰期的情况。
经过上面的分析,老王发现,增加各岗位人手无疑是最直观的解决办法!
我们可以计算一下人手增加的情况。假设把所有人员增加为2人配置:

那么很简单,2人就餐的情况下,由于所有人员并行服务,就餐的两名顾客可以同一时间点餐,等待烹饪,上菜后打包走人。

而后来的客人可以看作两条并行的线,那么100顾客的用餐时间就很自然的减半了。
看到这里,终于出现“并行”的概念了。
④继续调优
通过double人员配置,老王成功的使得用餐高峰期的服务能力提高了一倍,但这还不够。这种情况下,服务100顾客仍需差不多4个小时。
老王再次思考整个服务团队的配置和各环节处理能力,他发现,其瓶颈就在于“后厨”。顾客的等待时间,大部分都是在等待烹饪。
那么增加后厨能力就是重中之重,老王继续做了一系列措施:
- 再次double大厨人数,现在厨师们四个人同时并行做菜。
- 让备菜员提前将热门食材准备好。
- 聘请更有经验的大厨,每个餐品烹饪时间更快,加上提前备菜,整个配餐时间缩短到2分钟。
- 将点餐的过程改为使用手机小程序下单,让小二专注于上菜。
整个团队配置变为:

如此配置之下,这家开封菜终于可以在1小时之内就完成对100人顾客的就餐服务了!
2. 这并不是一篇餐饮管理文章
再继续讨论餐厅的服务能力调优,这可能就要变成一片餐饮博文了。
不过相信敏锐的你能看出来,第一部分我们的讨论里,包含了大量与服务器性能相似的概念。
恰好,老王

除了开了一家开封菜餐厅,还运营着一家网站=_=!。
这家网站的一次典型事务请求链路是这样的:

你别说,还真挺像用餐流程的吧。
而且就像多人用餐的场景一样,这个网站同样也有多用户请求的情况:

当一条请求从客户端发起时,它遵循着以上的线路传递,线性完成。
老王发现,这家网站的性能关键,在于应用服务器上。就像餐厅的服务能力,主要取决于后厨团队一样。
当多个客户端同时发起请求时,服务器必须具备一定的“并行”能力,否则后续进来请求会排队而且可能超时。
说到这呢,虽然上图我们画的是一个

,但一般都服务器的都有多处理器,辅以超线程技术。
而主流编程语言都有“多线程编程”的概念,其目的就在于合理的调度任务,将CPU的所有处理器充分的利用起来。
也就是说我们可以认为,这套应用服务本身就有不止一个“大厨”在烹饪。
取决于处理器数和多线程技术,数个事务可以以线程

的方式并行处理。
不过老王对于当前服务器的性能并不满意,就像对于餐厅一样,老王也针对这个应用服务思考了更多调优方案:
- 大厨的数量真的够吗?是不是要继续增加人数(CPU核数,服务器节点数-硬件调优)?
- 大厨的经验和技术到位吗?是不是要改聘更资深的大厨(改换具有更高频CPU的服务器-硬件调优;调整业务逻辑效率-逻辑调优)?
- 改良热门餐品的备菜策略?(利用数据库索引、缓存等技术-逻辑调优)
除了我们强调的调优重点,应用服务/后厨团队,其他部分也是有可能成为瓶颈,需要调优解决的,比如:
- 餐厅容量会不会无法容纳排队的客户?(服务器容量,线程池大小,最大连接数,内存空间)
- 小二的下单和上菜速度有没有成为掣肘?(网络带宽,路由效率等。对于数据密集型服务而言,网络带宽很可能成为瓶颈。)
- 等等
3. 下面是性能测试环节
接下来我们要讨论如何测试一套服务的性能。
线程数:
要实现性能测试的一个必要条件,那就是我们必须要能模拟高峰期的访问量。这一点通过正常的应用客户端是很难办到的(比如web应用的客户端就是浏览器,你很难用浏览器并发向服务器发送大量请求)。
这里就需要性能测试工具来帮忙了,主流的性能测试工具比如

,等都能以线程式并发的方式,帮我们达成“短时间内向服务器发送大量请求”这一任务。
多线程式并发测试工具,顾名思义,会启动复数个线程,让每个线程独立向服务器端发出请求。
有时候我们在描述性能测试过程时,会将这个客户端的独立线程数表述为“并发数”。
但是注意,这里的“并发”指的是客户端并发,很简单,客户端能发出很多请求,服务器却未必能处理得了是不是?
并行数:
那么服务器一次性能同时处理多少事务请求呢?
根据我们之前的讨论,同一时间节点上同时处理的事务数最大就是:CPU处理器数*服务器超线程倍率。
比如对于一个8核未超线程CPU,某时间节点上的同时处理的事务不会超过8个。类比于8个厨师,同一时间点上只能处理8份餐品。
而超线程技术就像是给厨师们来了一场“左右互搏”培训,让每个人都能一心二用,一次处理2份餐品。
这里我们描述的“同时8个”事务,就是“并行/平行”的含义。
并发数:
注意上面我们讨论的“并行数”,不是"并发数"。否则我们直接看CPU核数就能确定并发数了。
并发数指的是一个时间段内
的事务完成数。这个切片“时间段”常取1秒钟或1分钟这样的整数来做换算。
假设一个厨师平均2分钟做完一道菜,那么8个厨师2分钟完成8道菜,换算一下就是4道/分钟。
如果以分钟为单位进行统计,那么这个数字就是最终结果。
每秒事务数(TPS):
一般应用服务器的处理速度跟厨师做菜是不在一个数量级的,常见的事务请求在应用服务器端的处理时间以毫秒为单位计算。
所以测试性能时,我们更常用“1秒钟”来作为切片时间段。
一秒钟完成多少个事务请求,这个数据就是我们耳熟能详的“每秒事务数”。
这个指标翻译成英文就是TPS - Transaction Per Seconds。(也有用QPS - Query Per Seconds来统计的,其差异暂时不做讨论了)
每秒事务数,就是衡量服务器性能的最重要也是最直观指标。
每秒能完成的事务数越多,那么每分钟能完成的事务就越多,每天完成的事务数就越多 --

简单的小学数学。
那么他直接能影响到一个应用服务每天平均能承受的访问量/请求量,以及业务高峰期能承受的压力。
平均响应时间:
那么有哪些因素会影响到TPS数值?
有两个主要的维度:
- 单个事务响应速度
- 同一时间能并行执行的事务
第二点我们说了,它主要跟服务器资源配置,线程池容量,线程调度等相关。
第一点换一个说法就是:事务平均响应时间。单个事务平均下来完成的速度越快,那么单位时间内能完成的事务数就越多,TPS就越高 --

简单的小学数学。
所以在进行性能调优时,除了服务器容量资源,单个事务响应速度是另一个关注的重点。
要关注事务响应速度/时间,可以考虑在事务内部逻辑节点添加“耗时探针”的方式,来探测每个步骤分别花费的时间,从而找出可优化的部分。
吞吐量
吞吐量

是在性能探测过程中经常冒出来的名词,怎么理解他呢?
简单的结论就是,吞吐量是站在“量”的角度去度量,是一个参考指标。
但是光有“量”的数据有时候并无太大价值,一家餐厅1个小时卖出100份餐品和一个月才卖出100份餐品,单从“量”的维度衡量肯定不行,时间维度很重要!
所以,性能测试领域的吞吐量通常会结合上时间维度进行统计。
如果吞吐量的“量”以“事务”为统计单位的话,结合时间维度,转化以后可以很容换算成TPS。
4. 最后,关于性能测试的一些碎碎念
测试类型
由于测试目标的不同,性能测试可能存在很多种形式。
比如明确了解日访问量和巅峰访问量,测试服务器是否能够承受响应压力的测试。
比如用于探测系统负载极限和性能拐点的测试。
比如衡量系统在高负载情况下,长时间运行是否稳定的测试。
这许多种形式我们暂且不做讨论,不过所有以上测试的基础都是它 -- “并发测试”。
制造并发,是性能测试的基本实现办法。
进一步细化理解客户端线程数和并发量的关系
设服务器并发能力为每秒完成1个事务,即TPS=1/s。且服务器使用单核处理器,现用Jmeter启动5个线程循环进行并发测试,那么每个切片时间(每秒)都发生了什么?
我们可以用如下图表来分析:
其中,

为线程可执行(等待执行),为线程正在执行,表示线程执行完毕。
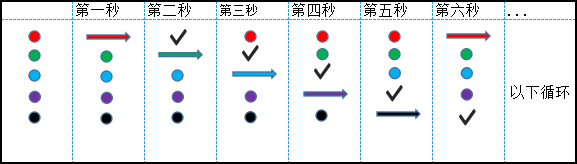
假设其他条件不变,增加服务器并行处理数为2(增加CPU核数为2,以及合理的线程调度机制)那么变为:

这里真实的并发数(服务器单位时间完成的事务数)就是图中每一秒钟完成的事务数。
而客户端启动的其他未处理的线程则在“排队等待”。
线程并发数量
那么制造多少并发,换言之,我应该用多少并发线程数去进行测试?
实际上客户端发起的线程数与服务器可达到的并发数并无直接关系,但你应该使用足够的线程数,让服务器达到事务饱和。
如何判断服务器是否达到饱和?这时我们可以采取阶梯增压
的方式,不断加大客户端线程数量,直到服务器处理不过来,事务频繁超时,这时就得到了服务器处理能力极限。
根据不同的测试类型,取这个极限数量的一定百分比作为客户端线程数。
比如说,负载测试中,通常取达到这个极限数值的70%。
客户端损耗
我们在讨论餐厅订单流程和服务器事务流程时,流程图里包括了顾客/客户端。
顾客点餐要不要花时间?当然要,如果他患上选择困难症,甚至有可能在下单的时候花去大量时间。
同理,客户端从启动线程到构造请求并发出,这一过程也有一定的时间损耗。
通常在测试服务器性能的时候,客户端性能是应该被剥离出去的,所以测试时应该尽量降低客户端时间损耗。
- 适当增加客户端线程循环次数 - 稀释这些线程启动的占用时间
- 当客户端线程数需要较大数量时(对jmeter而言,超过1000左右),客户机/测试机的资源占用会增大,整个客户端的请求构造时间会拉长。应该考虑分布式测试。
- 尽量减少客户端请求构造时间,比如beanshell请求加密,如果过程过于复杂也会耗去可观时间。极限测试情况下应考虑简化。
那么本文到这里告一段落。
希望能帮助理解性能测试领域的这些关键概念和原理。

最后:下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取 【保证100%免费】














 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









