






这些表是通过taskManagement 误操作 拉取了大量hive数仓tmp库中无用的表
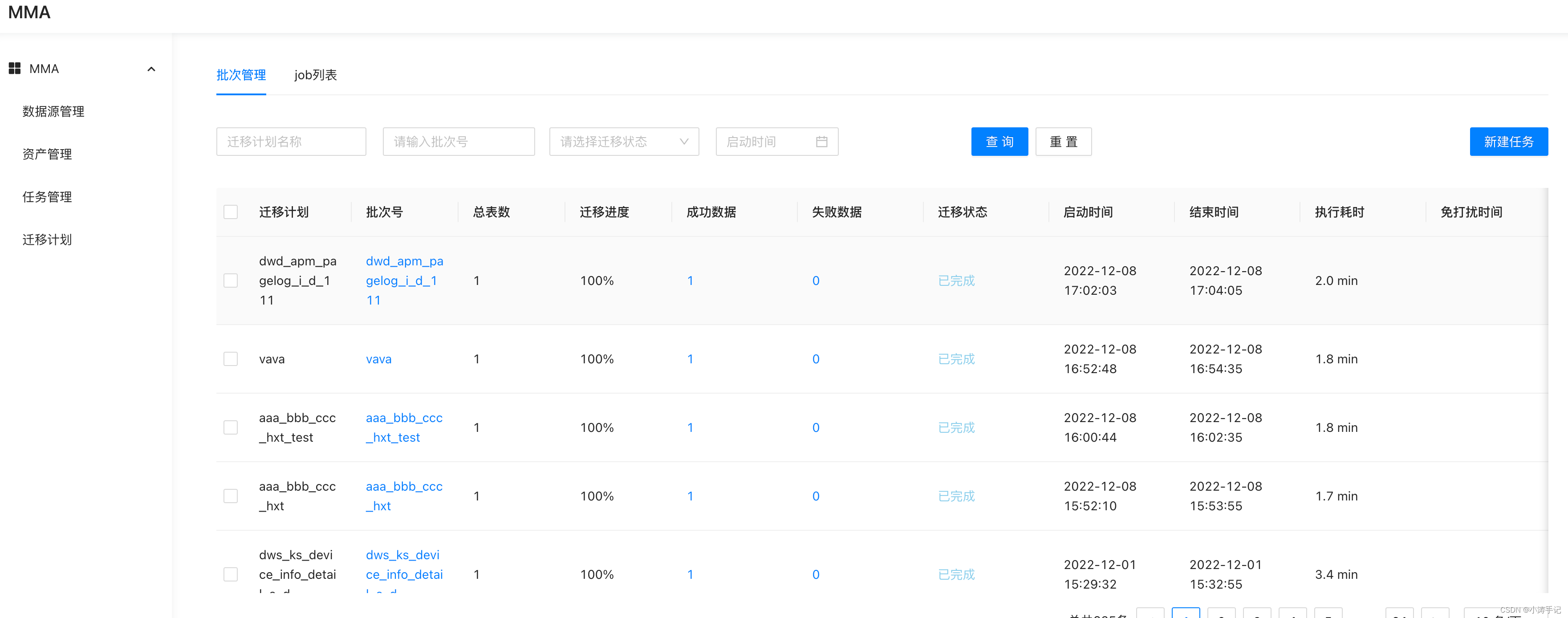
现在需要删除dataworks中这些无用的表,大概有20000多个,拉到dataworks中大概2000多个表
写一个删除语句删一个表,太难受了,啥时候才能删完!
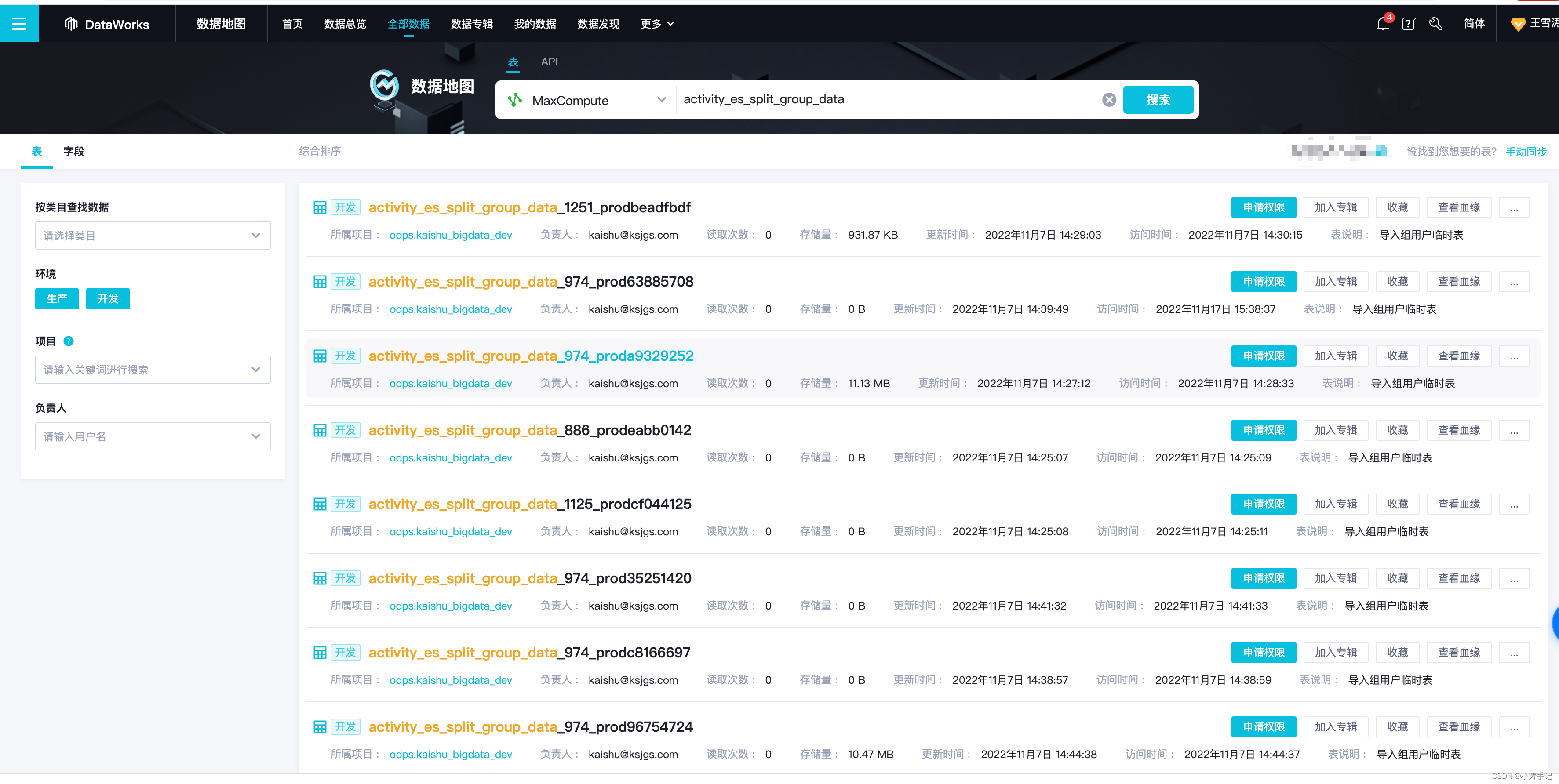
在hive中查看表信息找到这个表在hdfs中存储的路径
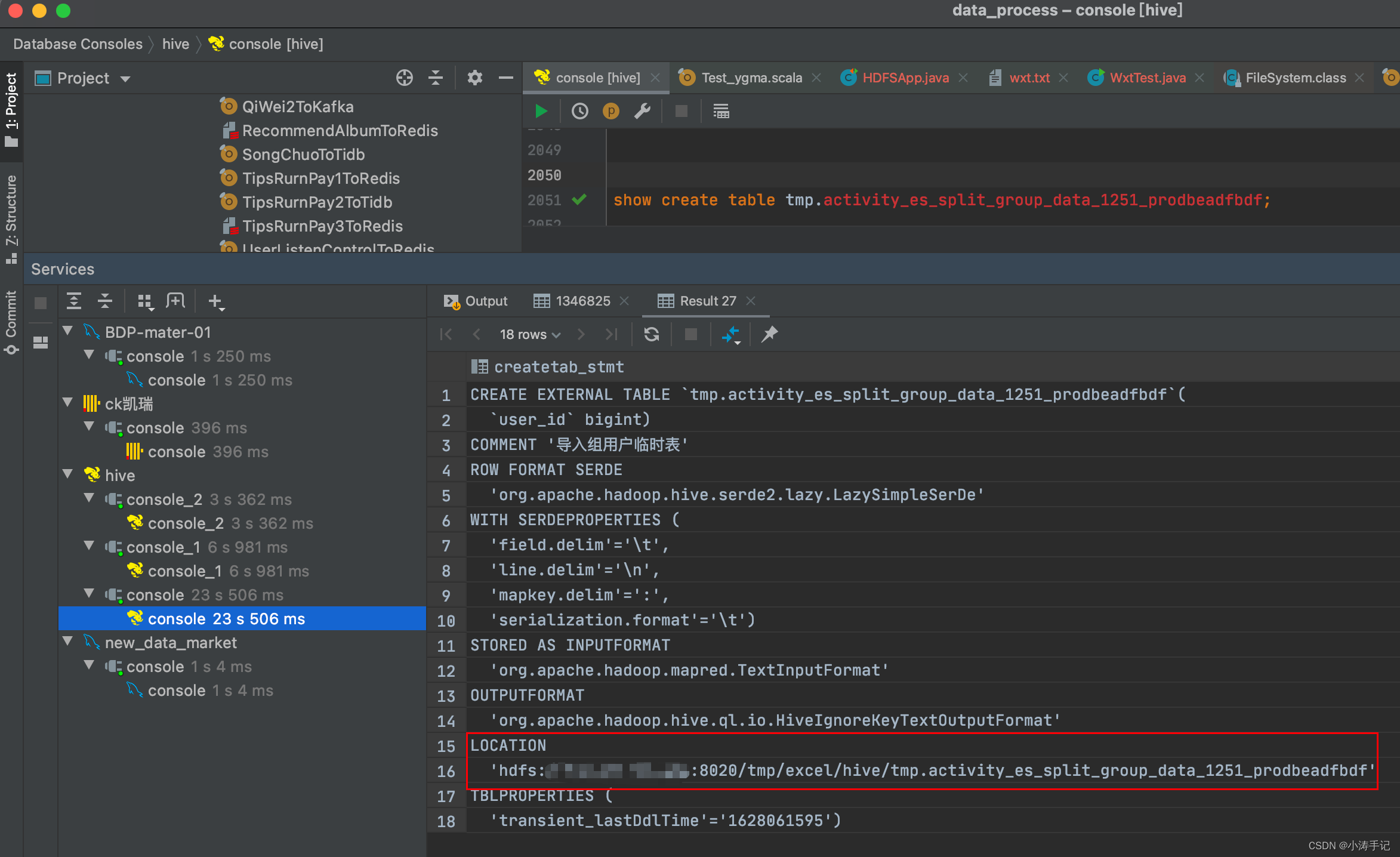
hdfs文件路径
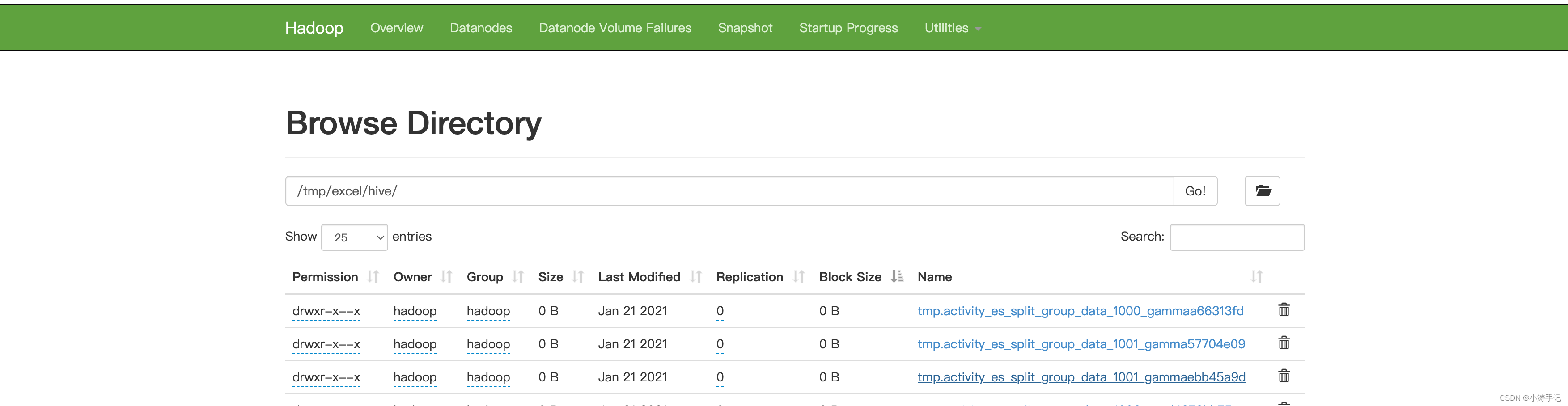

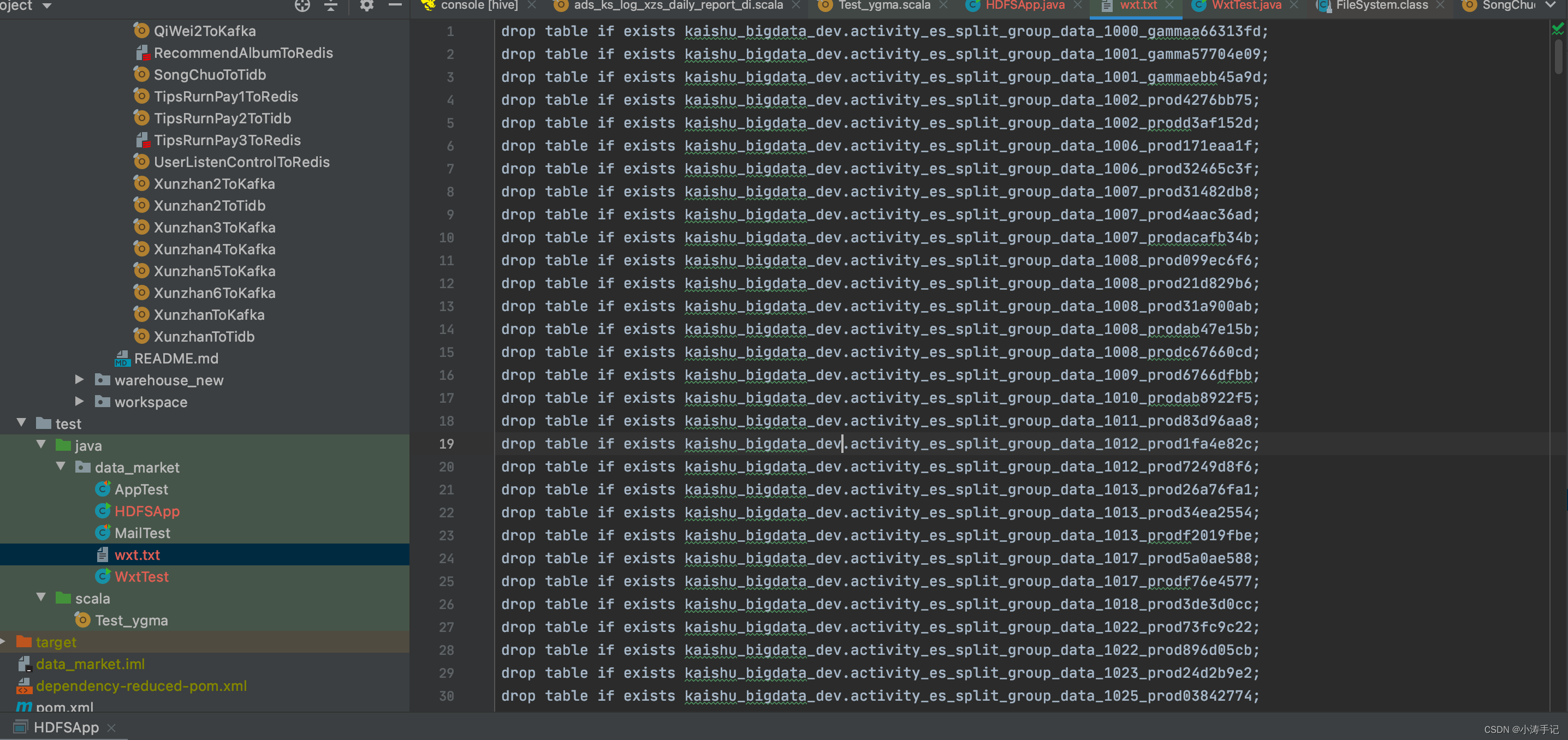
然后写java程序获取目录下的所有文件夹名称,再处理成删除表语句
package data_market;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.net.URI;
/**
* 获取hdfs上某个目录下的所有文件夹名称,转化成删除表语句写入本地文本
*/
public class HDFSApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://xxx.cluste:8020"), configuration, "xxx");
FileStatus[] statuses = fileSystem.listStatus(new Path("/tmp/excel/hive/"));
FileWriter writer = new FileWriter("/Users/edy/IdeaProjects/ks_bdp_data_process/data_process_spark/src/test/java/data_market/wxt.txt");
for(FileStatus file : statuses) {
String path = file.getPath().toString();
String[] split = path.split("hdfs://xxx-1.cluste:8020/tmp/excel/hive/tmp.");
String sql = "drop table if exists kaishu_bigdata_dev." + split[1] + ";";
try {
writer.write(sql+"\r\n");
writer.flush();
// writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
生成的文本文件
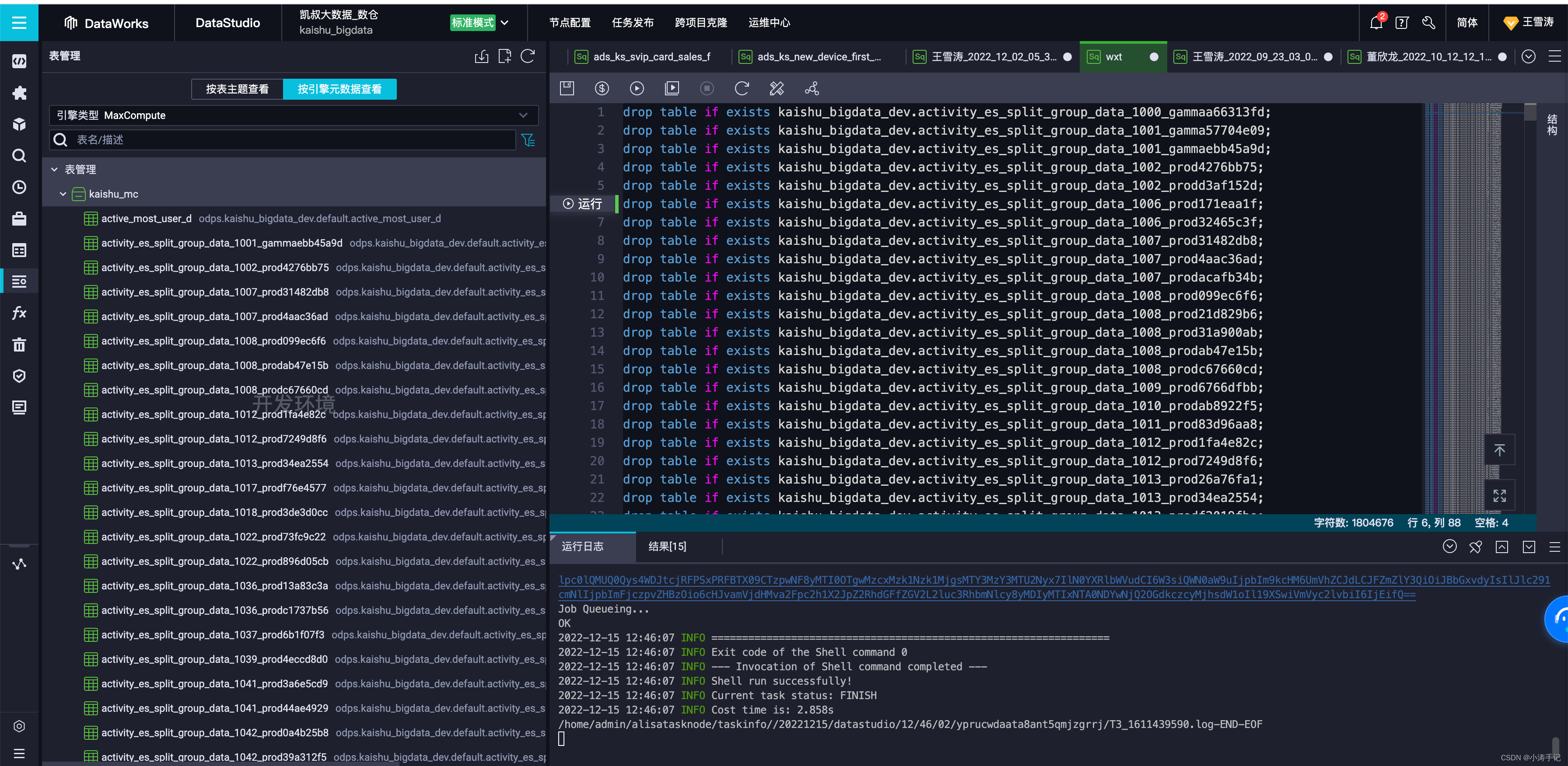
最后复制粘贴到dataworks上运行,删除表















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









