









 本文探讨了注意力机制、BatchNorm与LayerNorm的区别,Bert参数量的影响因素,Decoderonly架构的优势,以及梯度消失和爆炸的原因。还结合实例解析了力扣刷题中的字符串问题,如翻转单词、右旋字符串和KMP算法的应用。
本文探讨了注意力机制、BatchNorm与LayerNorm的区别,Bert参数量的影响因素,Decoderonly架构的优势,以及梯度消失和爆炸的原因。还结合实例解析了力扣刷题中的字符串问题,如翻转单词、右旋字符串和KMP算法的应用。
上期文章
文章目录
一、上期问题
- clip编码优缺点
- Torch 和 Tensorflow 的区别
- RNN
- 1x1卷积在卷积神经网络中有什么作用
- AIGC 存在的问题
- AlexNet
二、本期理论问题
1、注意力机制
注意力机制是一种通过调整输入数据的权重来提高模型性能的方法。它通过给每个输入元素来分配一个权重,以确定该元素对模型输出的贡献程度。权重的分配是通过一个称为“注意力”的函数来计算的,该函数根据输入元素的特征和需求来计算权重。注意力机制的主要目的是将更多的权重分配给与模型目标相关的输入元素,以使模型能够更好地处理这些元素。
2、BatchNorm 和 LayerNorm 的区别
BN(批归一化)和LN(层归一化)都是神经网络中用于正则化的技术,它们的主要区别在于处理的样本和特征维度不同。
- BN是对一批样本内的每个特征(通道)做归一化。LN是对每个样本的所有特征进行归一化,在层这个维度上去做归一化,它的均值和方差是针对单个样本的所有通道进行计算的。因此,可以简单地将它们看作是横向和纵向的区别。
- LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对变长的输入sequence的normalize操作。由于NLP中的文本输入一般为变长,所以使用layernorm更好。
3、Bert 的参数量是怎么决定的。
Bert的参数量由其模型结构以及隐藏层的大小、层数等超参数所决定。具体来说,Bert 模型由多个 Transformer Encoder 层组成,每个 Encoder 层包含多个注意力头以及前馈神经网络层。因此,Bert 的参数量主要由这些层的数量、每层的隐藏单元数、注意力头的数量等因素决定。
4、为什么现在的大语言模型都采用Decoder only架构?
大模型从模型架构上主要分为三种:以BERT为代表的Only-encoder、以T5和BART为代表的Encoder-Decoder、以GPT为代表的Only-Decoder,还有以UNILM为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causal mask)。
- 对于BERT这类Only-encoder来说,它使用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调,相比之下Only-decoder的模型用next token prediction预训练,兼顾理解和生成,在各种下游任务上的zero-shot和few-shot泛化性能都很好。
- 对于引入了一部分双向attention的Encoder-Decoder和PrefixLM来说,他们虽然也能兼顾理解和生成,但是训练效率和工程实现上不如Only-decoder架构,Only-decoder架构支持一直复用KV-Cache,对多轮对话更加友好。
- Only-decoder模型整体上的泛化性能是最好的,潜在原因主要有:
- Encoder的双向注意力存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处;而casal attention的注意力矩阵式下三角矩阵,必然是满秩的,建模能力更强;
- 纯粹的Only-decoder架构+next token prediction预训练,每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大、数据足够多的时候,Only-decoder模型学习通用表征的上限更高;
- casal attention(即Only-decoder的单向attention)具有饮食的位置编码功能,打破了transformer的位置不变形,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱。
5、什么是梯度消失和爆炸
梯度消失是指在深度学习训练的过程中,梯度随着 BP 算法中的链式求导逐层传递逐层减小,最后趋近于0,导致对某些层的训练失效;梯度爆炸与梯度消失相反,梯度随着 BP 算法中的链式求导逐层传递逐层增大,最后趋于无穷,导致某些层无法收敛;
6、梯度消失和梯度爆炸产生的原因
出现梯度消失和梯度爆炸的问题主要是因为参数初始化不当以及激活函数选择不当造成的。其根本原因在于反向传播训练法则,前面层上的梯度是来自于后面层上梯度的乘积,属于先天不足。当训练较多层数的模型时,一般会出现梯度消失问题和梯度爆炸问题。
三、力扣刷题回顾-字符串
上期涉及题目:
本期题目:
151.翻转字符串里的单词:
- 给定输入:一个字符串 s
- 要求输出:反转字符串中单词的顺序
右旋字符串:
- 给定输入:一个字符串 s 和一个正整数 k
- 要求输出:将字符串中的后面 k 个字符移到字符串的前面
28. 实现 strStr():
- 给定输入:两个字符串 haystack 和 needle
- 要求输出:在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标。如果 needle 不是 haystack 的一部分,则返回 -1 。
459.重复的子字符串:
- 给定输入:一个非空的字符串 s
- 要求输出:检查是否可以通过由它的一个子串重复多次构成
对比分析:
151.翻转字符串里的单词和右旋字符串两道题都是字符串章节较为简单的题目,151.翻转字符串里的单词可以采用双指针的思想解决,右旋字符串使用字符串切片即可。28. 实现 strStr()和459.重复的子字符串是两道运用KMP算法的字符串题。KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
151.翻转字符串里的单词
class Solution:
def reverseWords(self, s: str) -> str:
lst=s.split()
left,right=0,len(lst)-1
while left < right:
lst[left],lst[right] = lst[right],lst[left]
left += 1
right -= 1
return " ".join(lst)
右旋字符串
k=int(input())
s=input()
left=len(s)-k
right=len(s)
s=s[left:right]+s[:left]
print(s)
KMP算法
- KMP算法是用来解决字符串匹配的问题: 在一个串中查找是否出现过另一个串。
- KMP的经典思想: 当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
- KMP中记录已经匹配的文本内容的关键是前缀表: 前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。前缀表中下标i对应的值就是记录了下标i之前(包括i)的字符串中有多大长度的相同前缀后缀。
- 前缀表为什么可以记录下一次匹配的位置:
下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
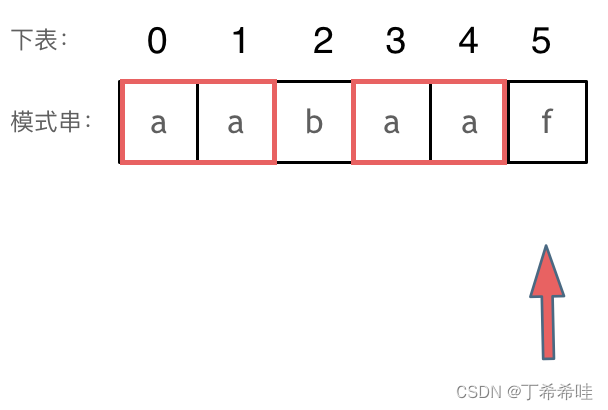
- 前缀表的计算:
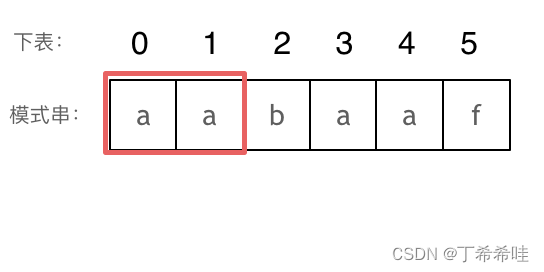
长度为前1个字符的子串a,最长相同前后缀的长度为0。(注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。)

长度为前2个字符的子串aa,最长相同前后缀的长度为1。
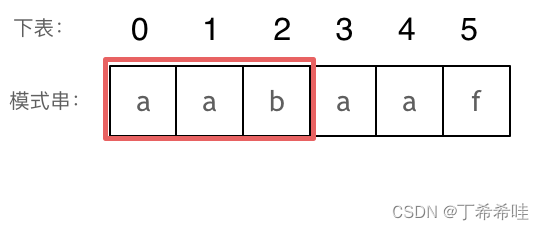
长度为前3个字符的子串aab,最长相同前后缀的长度为0。
以此类推: 长度为前4个字符的子串aaba,最长相同前后缀的长度为1。 长度为前5个字符的子串aabaa,最长相同前后缀的长度为2。 长度为前6个字符的子串aabaaf,最长相同前后缀的长度为0。
那么把求得的最长相同前后缀的长度就是对应前缀表的元素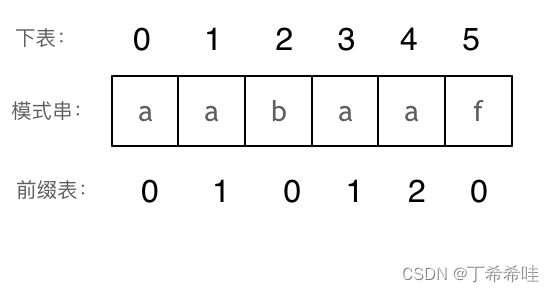
28. 实现 strStr()
- 定义next数组(前缀表):
- 初始化
- 定义两个指针分别遍历前缀和后缀
- 然后分别处理前后缀相同和不同的情况
- 更新next数组的值
- 进行匹配
- 获得子串的next数组
- 定义两个指针分别遍历子串和父串
- 依次匹配,分别处理匹配成功和匹配不成功的情况
class Solution:
def getNext(self,next,s):
# 初始化next数组
next[0] = 0
# 定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置
j = 0
for i in range(1,len(s)):
# 前后缀末尾不相同的情况,就要向前回退
while j > 0 and s[i] != s[j]:
j = next[j-1]
# 前后缀相同时,就同时向后移动i 和j
if s[i] == s[j]:
j += 1
# 将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度
next[i] = j
def strStr(self, haystack: str, needle: str) -> int:
if len(needle) == 0:
return 0
next = [0] * len(needle)
self.getNext(next,needle)
j=0
for i in range(len(haystack)):
while j > 0 and haystack[i] != needle[j]:
j = next[j-1]
if haystack[i] == needle[j]:
j += 1
if j == len(needle):
return i-len(needle)+1
return -1
459.重复的子字符串
- 定义next数组(前缀表):
- 初始化
- 定义两个指针分别遍历前缀和后缀
- 然后分别处理前后缀相同和不同的情况
- 更新next数组的值
- 进行匹配
数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
class Solution:
def getNext(self,next,s):
# 初始化next数组
next[0] = 0
# 定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置
j = 0
for i in range(1,len(s)):
# 前后缀末尾不相同的情况,就要向前回退
while j > 0 and s[i] != s[j]:
j = next[j-1]
# 前后缀相同时,就同时向后移动i 和j
if s[i] == s[j]:
j += 1
# 将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度
next[i] = j
def repeatedSubstringPattern(self, s: str) -> bool:
if len(s) == 0:
return False
next = [0]*len(s)
self.getNext(next,s)
if next[-1] != 0 and len(s)%(len(s)-next[-1]) == 0:
return True
return False
参考:
代码随想录算法训练营第七天|344.反转字符串,541. 反转字符串II,卡码网:54.替换数字,151.翻转字符串里的单词,卡码网:55.右旋转字符串
代码随想录算法训练营第八天|28. 实现 strStr(),459.重复的子字符串,字符串总结,双指针回顾
为什么现在的LLM都是Decoder only的架构?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









