







1、excel准备

A列为保存的文件名,B列为网址,C列为文件的路径地址。
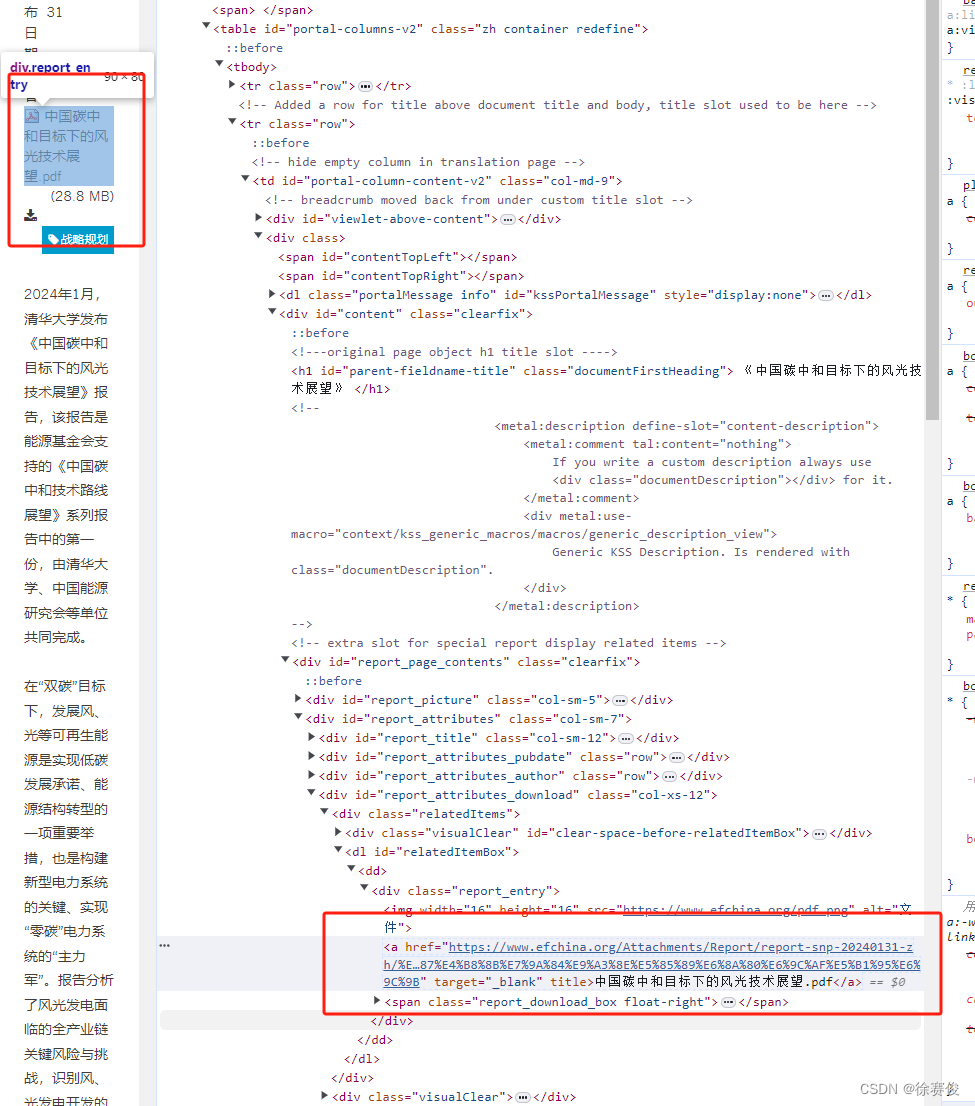
选中元素复制selector,#relatedItemBox > dd > div > a[href],调取这个路径下标签a 属性href的链接,然后下载文件。
import tkinter as tk
from tkinter import filedialog
import pandas as pd
import requests
import os
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin, unquote
def get_links_from_xpath(base_url, xpath):
'''
从指定XPath下获取所有链接
:param base_url: 给定的网址
:param xpath: 指定的XPath
:return: 包含所有链接的列表
'''
try:
response = requests.get(base_url)
response.raise_for_status()
html_content = response.text
except requests.RequestException as e:
print(f"Error retrieving links from {base_url}: {e}")
return []
# 使用Beautiful Soup解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
# 找到指定XPath下的所有链接
links = soup.select(f"{xpath}")
# 提取链接的href属性值
hrefs = [link.get('href') for link in links if link.get('href')]
# 将相对链接转换为绝对链接
base_parsed = urlparse(base_url)
abs_hrefs = [urljoin(base_parsed.scheme + "://" + base_parsed.netloc, href) for href in hrefs]
return abs_hrefs
def download_file(url, output_folder):
'''
下载文件并保存到指定文件夹内
:param url: 文件链接
:param output_folder: 指定的输出文件夹
'''
try:
response = requests.get(url)
response.raise_for_status()
except requests.RequestException as e:
print(f"Error downloading {url}: {e}")
return
# 从文件链接中获取文件名
filename = os.path.basename(unquote(url))
# 创建对应的文件夹
os.makedirs(output_folder, exist_ok=True)
# 拼接完整的文件路径
filepath = os.path.join(output_folder, filename)
# 检查文件是否已经存在,如果存在则跳过下载
if os.path.exists(filepath):
print(f"Skipped: {filepath} (already exists)")
return
# 保存文件到指定文件夹
with open(filepath, 'wb') as f:
f.write(response.content)
print(f"Downloaded: {filepath}")
def choose_excel_file():
'''
选择Excel文件并读取网址和XPath
'''
# 创建Tkinter窗口
root = tk.Tk()
root.withdraw() # 隐藏Tkinter窗口
# 打开文件选择对话框并获取选择的Excel文件路径
excel_file_path = filedialog.askopenfilename(filetypes=[("Excel files", "*.xlsx *.xls")])
# 读取Excel文件中的网址和对应的XPath
if excel_file_path:
df = pd.read_excel(excel_file_path)
for index, row in df.iterrows():
# 获取网址和XPath
url = row['URL']
xpath = row['XPath']
output_folder = os.path.join('pdf_files', str(row['filesname']))
# 获取指定XPath下的所有链接
links = get_links_from_xpath(url, xpath)
# 下载并保存所有链接指向的文件
for link in links:
download_file(link, output_folder)
if __name__ == "__main__":
choose_excel_file()

















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









