# UA池
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
from random import choice
USER_AGENT = choice(USER_AGENT_LIST) #随机UA
ROBOTSTXT_OBEY = False # ROBOT协议
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 5 # 设置并发数为5,默认16
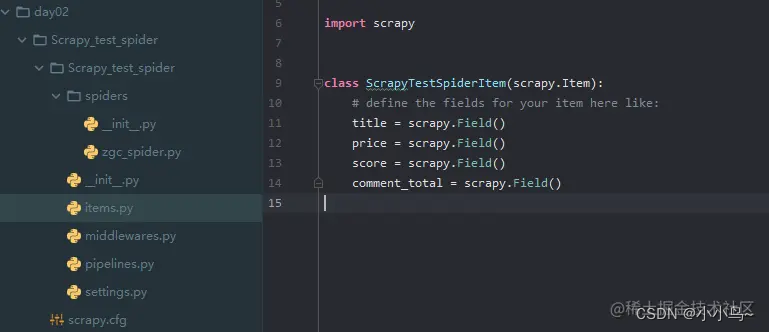
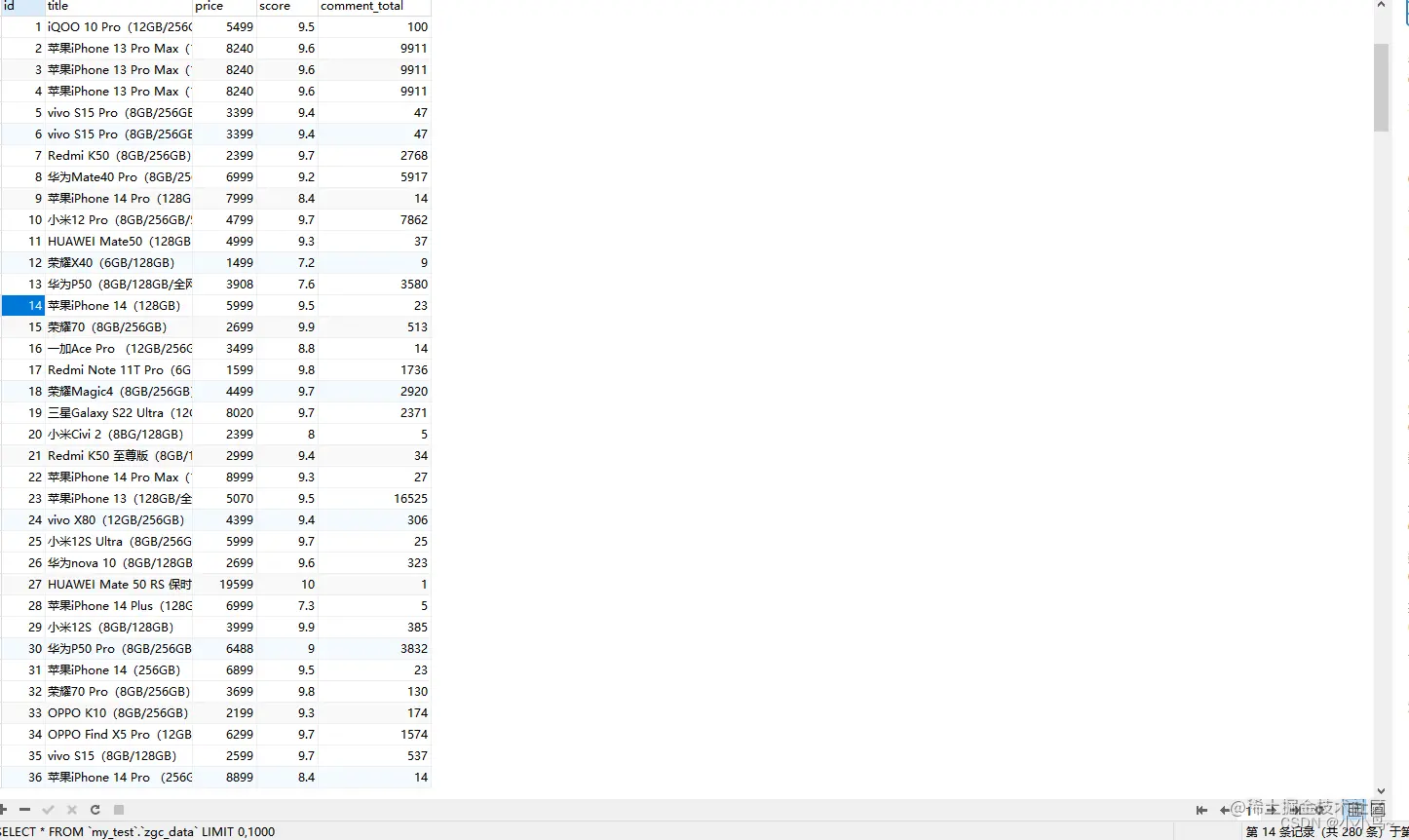
4.item中定义字段信息
比如我们要采集手机的标题,价格,评分,评论数量。
import scrapy
class ScrapyTestSpiderItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() #标题
price = scrapy.Field() #价格
score = scrapy.Field() #评分
comment_total = scrapy.Field() #评论总数
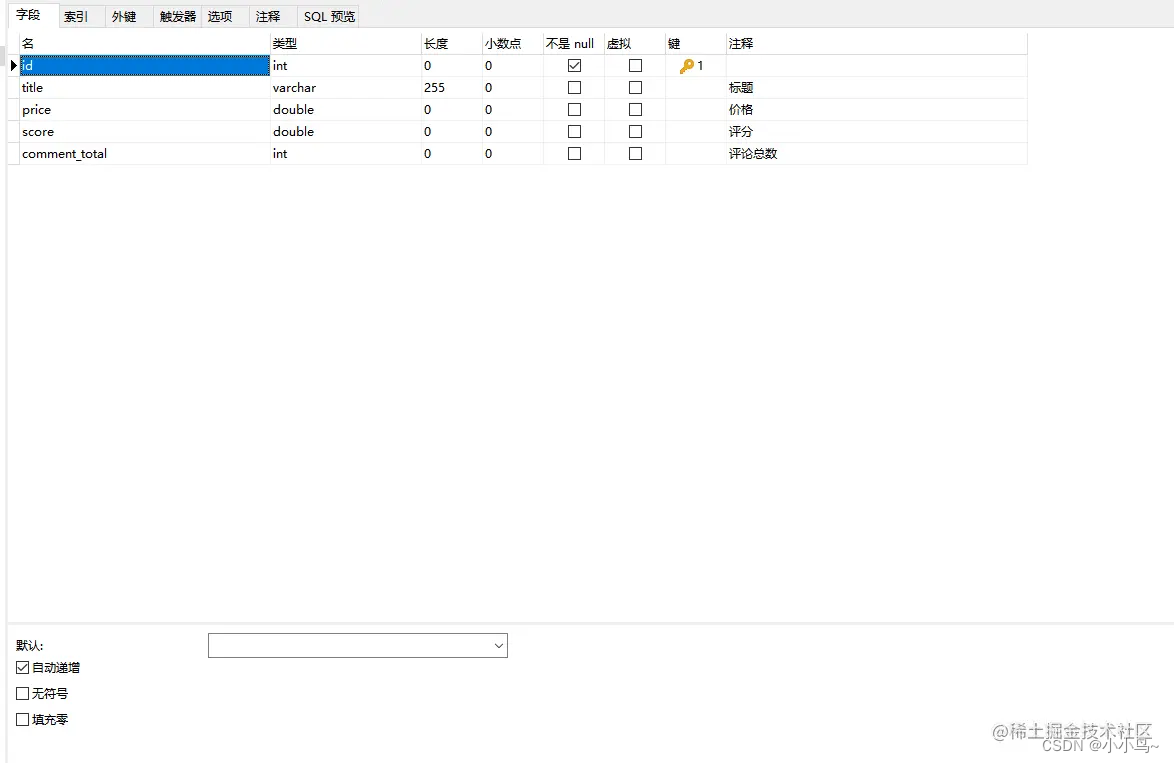
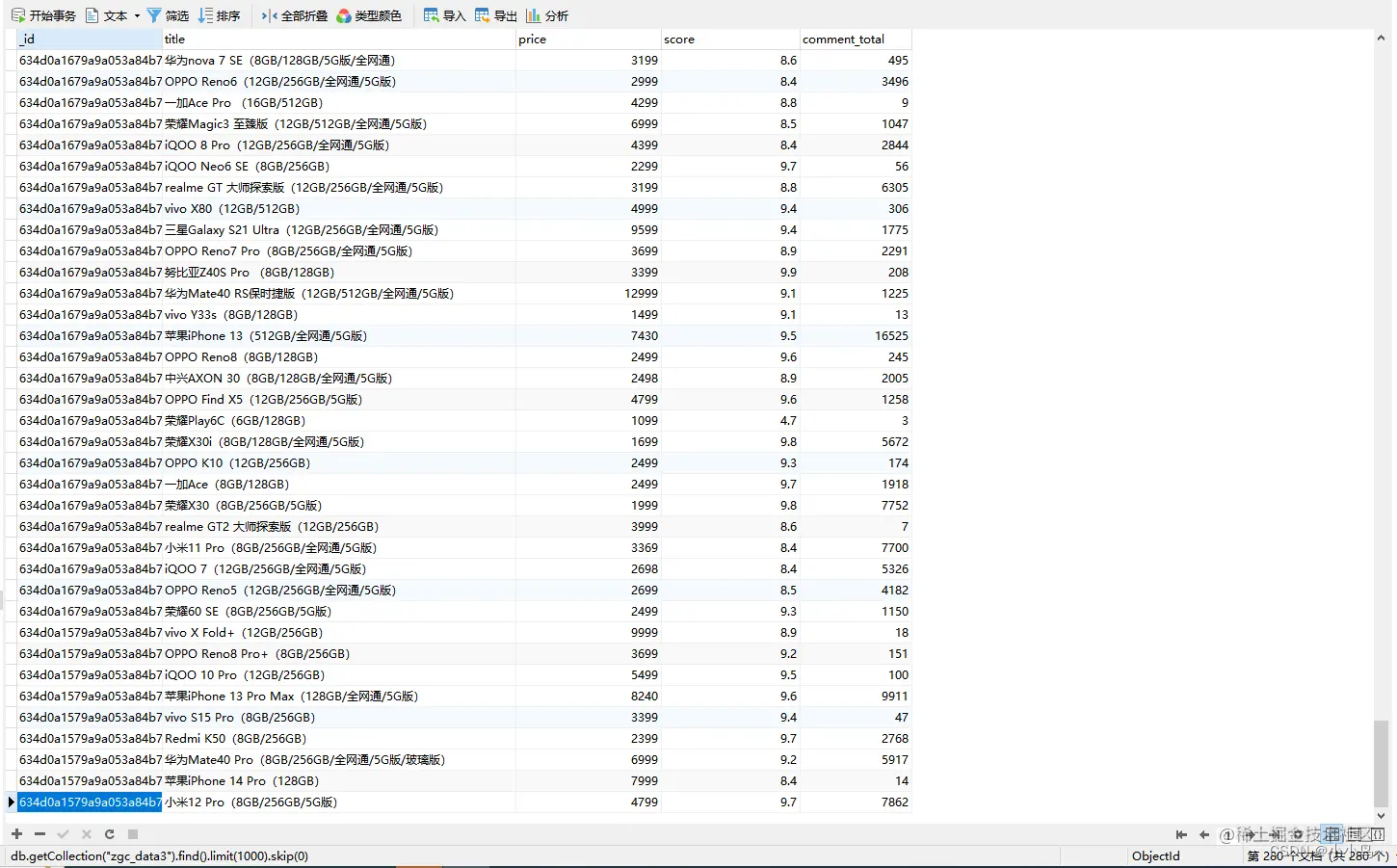
5.mysql设计表结构
6.爬虫代码编写
python
import scrapy
from Scrapy_test_spider.items import ScrapyTestSpiderItem
class ZgcSpiderSpider(scrapy.Spider):
name = 'zgc_spider'
allowed_domains = ['detail.zol.com.cn']
start_urls = ['https://detail.zol.com.cn/cell_phone_index/subcate57_list_1.html']
count = 5 #控制翻页次数
def parse(self, response):
item = ScrapyTestSpiderItem()
li_list = response.css('#J_PicMode li')
for li in li_list:
price = li.css('div.price-row > span.price.price-normal > b.price-type::text').get()
title = li.css('li > h3 > a::text').get()
score = li.css('div.comment-row > span.score::text').get()
comment_total = li.css('div.comment-row > a.comment-num::text').get()
if not price or not title or not score or not comment_total:
continue
item['title'] = title
item['price'] = float(price)
item['score'] = float(score)
item['comment_total'] = int(comment_total.replace('人点评',''))
yield item
# 翻页操作
next_page = response.css('a.next::attr(href)').get()
if next_page and self.count:
print(response.urljoin(next_page))
yield scrapy.Request(response.urljoin(next_page),callback=self.parse)
self.count -= 1
if __name__ == '__main__':
from scrapy.cmdline import execute
execute('scrapy crawl zgc_spider'.split())





















 2489
2489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









