









朴素贝叶斯
常用于文本分类的朴素贝叶斯算法基于贝叶斯假设而来。和逻辑回归是概率判别式模型不同,朴素贝叶斯算法是概率生成式模型,不需要直接计算生成的概率值。朴素贝叶斯算法对小规模数据处理效果较好,但是若样本属性有关联时分类效果不好。
其最优化目标是是使得后验概率最大,通过贝叶斯假设使得联合概率可以分开乘积(否则则要通过极大似然方法估计参数,再转化成最优化的极值问题求解),这也就大大简化了计算,算法因此也十分简洁。
代码实现如下:
import numpy as np
#载入文本
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性词汇,0代表不是
return postingList,classVec #返回实验样本切分的词条和类别标签向量
def createVocabList(dataSet):
VocabList = set([]) #创建不重复的空集
for document in dataSet:
VocabList = VocabList | set(document) #取并集
return list(VocabList)
#词集模型
def setOfWords2Vec(VocabList,inputSet):
retVec = [0] * len(VocabList)
for word in inputSet:
if word in VocabList:
retVec[VocabList.index(word)] = 1
return retVec
# #词袋模型
# def setOfWords2Vec(VocabList,inputSet):
# retVec = [0] * len(VocabList)
# for word in inputSet:
# if word in VocabList:
# retVec[VocabList.index(word)] += 1
# return retVec
#朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numDocs = len(trainMatrix)
numwords = len(trainMatrix[0])
p0Num = np.zeros(numwords)
p1Num = np.zeros(numwords)
p0Demon = 0.0
p1Demon = 0.0
pc1 = sum(trainCategory)/float(numDocs)
for i in range(numDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Demon += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Demon += sum(trainMatrix[i])
p1Vect = p1Num / p1Demon
p0Vect = p0Num / p0Demon
return p0Vect,p1Vect,pc1
#朴素贝叶斯分类函数
def classifyNB(vec2Classify,p0Vect,p1Vect,pc1): #vec2Classify为文本经过向量化后的向量
#这里转变成log方便数学计算
p1 = sum(vec2Classify * p1Vect) + np.log(pc1)
p0 = sum(vec2Classify * p0Vect) + np.log(1.0-pc1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
list0posts, listClasses = loadDataSet()
myVocabulist = createVocabList(list0posts)
trainmat = []
for postinDoc in list0posts:
trainmat.append(setOfWords2Vec(myVocabulist,postinDoc))
p0V,p1V,pcV = trainNB0(np.array(trainmat),np.array(listClasses))
testEntry = ['love','my','dalmation']
testVec = np.array(setOfWords2Vec(myVocabulist, testEntry))
if classifyNB(testVec, p0V, p1V, pcV) == 1:
print(testEntry, '属于侮辱类')
else:
print(testEntry, '属于非侮辱类')
testEntry = ['stupid','garbage']
testVec = np.array(setOfWords2Vec(myVocabulist,testEntry))
if classifyNB(testVec,p0V,p1V,pcV) == 1:
print(testEntry,'属于侮辱类')
else:
print(testEntry,'属于非侮辱类')
if __name__ == '__main__':
testingNB()
运行结果:
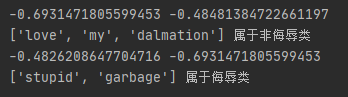
参考:
1、《机器学习实战》















 2677
2677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









