






 本文介绍了如何使用Python的requests库获取网页内容,通过BeautifulSoup解析HTML,提取表格数据,然后利用正则表达式和pandasDataFrame结构,将数据存储为CSV文件的过程。
本文介绍了如何使用Python的requests库获取网页内容,通过BeautifulSoup解析HTML,提取表格数据,然后利用正则表达式和pandasDataFrame结构,将数据存储为CSV文件的过程。
获取网页中的表格并存储为csv
0、需要用到的包
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
1、请求网页并获取内容
# 发送 GET 请求并获取响应
response = requests.get('https:xxxxxxx')
# 将内容存储
text = response.text
soup = BeautifulSoup(text, "lxml")
2、获取表格内容
# 获取表格
tables = soup.find_all("table")
# 提取第一个表格的数据
data1 = tables[0].extract()
这里我感兴趣的内容有两种形式:
(1)<td></td>中的<strong>中的标题和<i>中的内容

(2)<td></td>中的<a>中的网页链接和标题和<i>中的内容
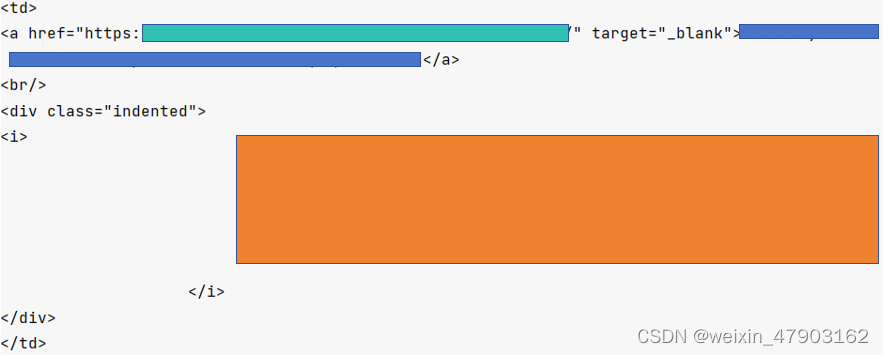
3、准备提取工作
# 提取所有的相关内容,得到每个<td></td>内容
related_content = data1.find_all('td')
# 通过内容信息,构造相应的正则表达式
pattern1 = r'<strong>(.*?)</strong>'
pattern2 = r'<a href="(.*?)" target="_blank">(.*?)</a>'
pattern_c = r'<i>\n \n (.*?)\n \n </i>'
# 创建一个dataframe,用于存储需要的信息
mydataframe1 = pd.DataFrame(columns=['title', 'content', 'link'])
4、提取特征并存储到dataframe中
for i in range(len(related_content)):
fs = related_content[i].find('strong') # 寻找标识
fi = related_content[i].find('i')
fa = related_content[i].find('a')
if(fs == None and fa == None): # 如果fs和fa都没有,则continue
continue
if(fs != None): # 如果有fs
match_title = re.search(pattern1, str(fs))
match_c = re.search(pattern_c, str(fi))
cur_title_cnt = match_title.group(1)
cur_content_cnt = match_c.group(1)
cur_length = len(mydataframe1)
mydataframe1.loc[cur_length] = [cur_title_cnt, cur_content_cnt, None]
else:
match_title = re.search(pattern2, str(fa))
match_c = re.search(pattern_c, str(fi))
cur_link_cnt = match_title.group(1)
cur_title_cnt = match_title.group(2)
cur_content_cnt = match_c.group(1)
cur_length = len(mydataframe1)
mydataframe1.loc[cur_length] = [cur_title_cnt, cur_content_cnt, cur_link_cnt]
# 保存第一个表格
mydataframe1.to_csv('xxxxx.csv', index=False)
在实际运用中,需要根据实际获得的网页数据和目标需求调整find和match的信息。















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









