







之前,我们尚未讨论如何可靠、快速地将消息从一个节点发送到另一个节点。本章目的是讨论多个处理器互连的结构。互连网络最重要的两个性能指标是延迟和带宽。
基于共享存储多处理器的几个通信特性,与诸如局域网或因特网等其他网络系统相比,共享存储多处理器对互连结构性能具有独特的要求:
1. 消息非常短。许多消息是一致性协议的请求和响应,但不包含数据,也有一些消息包含少量(高速缓存块大小的)数据,这些数据在当前主流系统中为64或128字节。
2. 消息生成很频繁,因为每个读或写缺失都可能生成涉及几个节点的一致性消息。
3. 由于消息是因处理器读或写时间而生成的,所以处理器隐藏消息通信延迟的能力相对较低。
4. 拓扑(或网络的形状)大部分是静态的。
因此,共享存储多处理器互连结构必须提供非常低的延迟和节点之间的高带宽通信,并且针对小的和几乎均匀大小的分组进行过优化。
共享存储多处理器互连网络应当被设计成具有尽可能少的通信协议层,以便最小化通信延迟。例如,互连网络可以仅使用2个协议层次:链路级协议确保单个分组在单个链路上的可靠传送,节点级协议确保分组从一个节点到另一个节点的可靠传送。其次,通信协议应以精简为基本特征。例如,复杂的策略(端到端和涉及丢弃分组的流量控制)可能会对性能造成损害。相反,应该仅在链路级执行流量控制,以避免接收端缓冲区溢出。此外,通常应避免丢弃分组,并且路由协议不需要维护和查找大型的路由表。
在设计共享存储多处理器的互连网络时需要考虑的另一个特性是它如何与多处理器的其他组件交互,如高速缓存一致性和存储一致性模型。
由于性能、可扩展性和成本要求的差异,通过对于某个系统的最佳互联网络对于其他系统可能不是最佳的。
互连网络将多个处理器紧密连接在一起,形成了共享存储多处理器系统,一个或一组处理器封装在一个节点中,这样的节点可以由一个或多个处理器核、高速缓存或层次结构的高速缓存、存储器、通信控制器组成,通信控制器是通过路由器和网络结构接口的逻辑,而路由器通过连接到其他路由器以形成网络。
两台路由器之间的物理线路称为链路。链路可以是单工的,即数据只能在一个方向上发送,或者是双工的,即数据可以在两个方向上发送。互连网络的一个重要特征是网络的形状,称为网络拓扑。

11.1 链路、信道和延迟
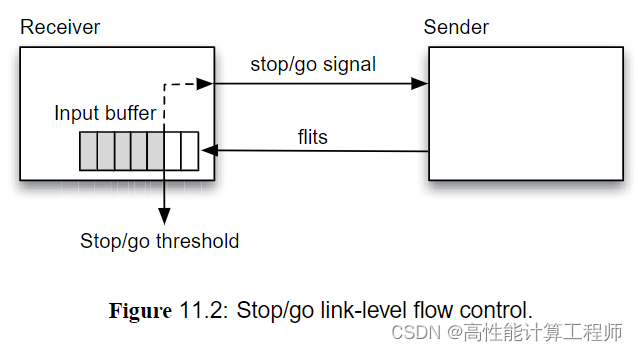
链路是连接两个节点的一组导线。在一个周期内可以传输的最小数据称为Phit。Phit通常由链路的宽度确定。例如一条10位宽的链路可以容纳1字节的(8位)Phit,而剩余的2位用于控制信号或奇偶校验信息。然而,数据是以称为Flit的链路级流量控制单元位单位传输的。Flit可以由一个或多个Phit组成,这些Phit作为单个流量控制单元必须用几个时钟周期来传输。接收端可以同意或者拒绝接收一个Flit的数据,这基于接收端可用的缓冲区大小和所用的流量控制项协议。
流量控制机制工作在链路级,以确保数据不会被过快地接收,避免接受路由器的缓冲区溢出。在有损网路中,缓冲区溢出会导致Flit被丢弃并重新传输,从而导致延迟。因此,不会丢弃和重传Flit的无损网络成为首选。stop/go协议的阈值有发送和接收两端之间的往返时延确定。
考虑到数据传输将通过不止一条链路时,有两种网络交换策略。一种策略是电路交换,在传输数据之前为发烧和接收端“预定”链接。这意味着发送端首先发送命令以建立到接收端的连接,传输路径上的路由器将为消息传输预留适当的输入和输出端口以及端口之间连接。一旦连接完成,接收端应答建立完成的消息。此后,发送端可以向接收端发送消息。从这里开始,消息可以非常高效地传播,它不需要被分成多个小的分组,单个数据包也不需要包含路由信息。由于输入端口和输出端口连接已经预留,因此数据包在每个路由器也不会受到大多路由延迟的影响。
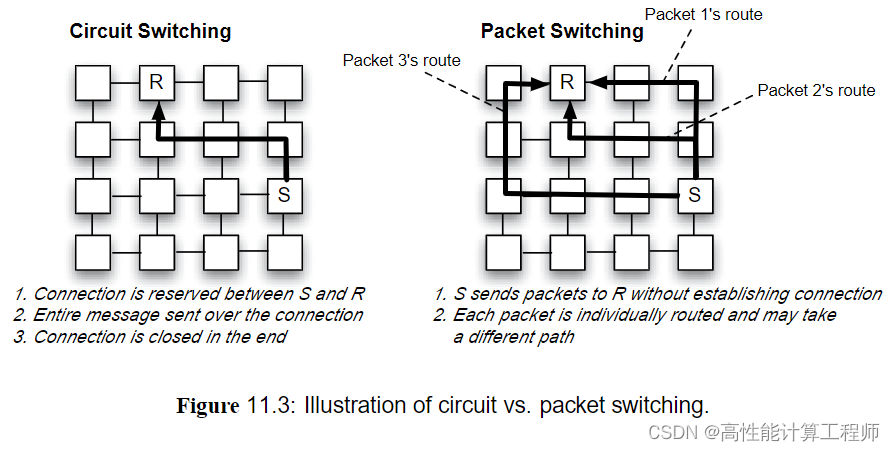
另外一种交换策略是分组交换。对于分组交换,当在信道上传输大消息时,消息会分段并封装成分组。消息的每个部分都变成一个分组的有效载荷,并增加头部和尾部进行封装。这种分段允许消息以彼此独立的部分发送,分组的头部和尾部确保可靠传递,并且抱哈足够的信息以便在目的地将分组重新组装成原始消息。分组交换中的分组头部具有更多信息,包括目的地和可能的路由信息。分组在链路上以Flit的粒度传输,根据分组相对于Flit的大小,可能需要多个Flit来传输分组。分组的头部和尾部包含诸如校验和之类的信息,校验和是一组冗余的二进制位串,允许检测或校正分组中因传输错误而改变了的二进制位。

对比电路交换和分组交换,电路交换会因为建立连接而导致显著的延迟,同时,一旦连接建立,如果不立即使用,会使连接的利用率下降。此外,如果有新的连接与已有连接冲突,需要等到已有连接释放,这会给其他通信或连接带来显著的延迟。然而,电路交换也有其优势:连接建立之后,消息传递速度非常快,因为路由器只需要将消息转发给输出端口,而无需决定路由或资源分配;只需要少量的缓冲,因为消息会转发到下一个路由器,在那里有足够的资源来接收信息。更低的延迟、更简单的路由逻辑和最小的缓冲区降低了路由器的功耗。分组交换的情况正好相反。分组交换会在每个路由器引发的显著路由延迟和功耗,但不会引入连接建立或拆除的开销,并且可以每个分组的基础上管理资源,能够更容易地叠加许多不同的通信任务。
11.2 网络拓扑
网络拓扑是互连网络的形状,即节点是如何互连在一起的。因为它会显著影响网络性能(时延、距离、直径、对分带宽)和成本。网络拓扑的选择通常需要再设计阶段的早期决定。
对于小型的多处理器,有时单个路由器就足以互连所有处理器。但是,当节点数大于或等于单个路由器可以连接的节点数时,路由器必须通过网络拓扑的形式相互连接。
几种常见拓扑类型:
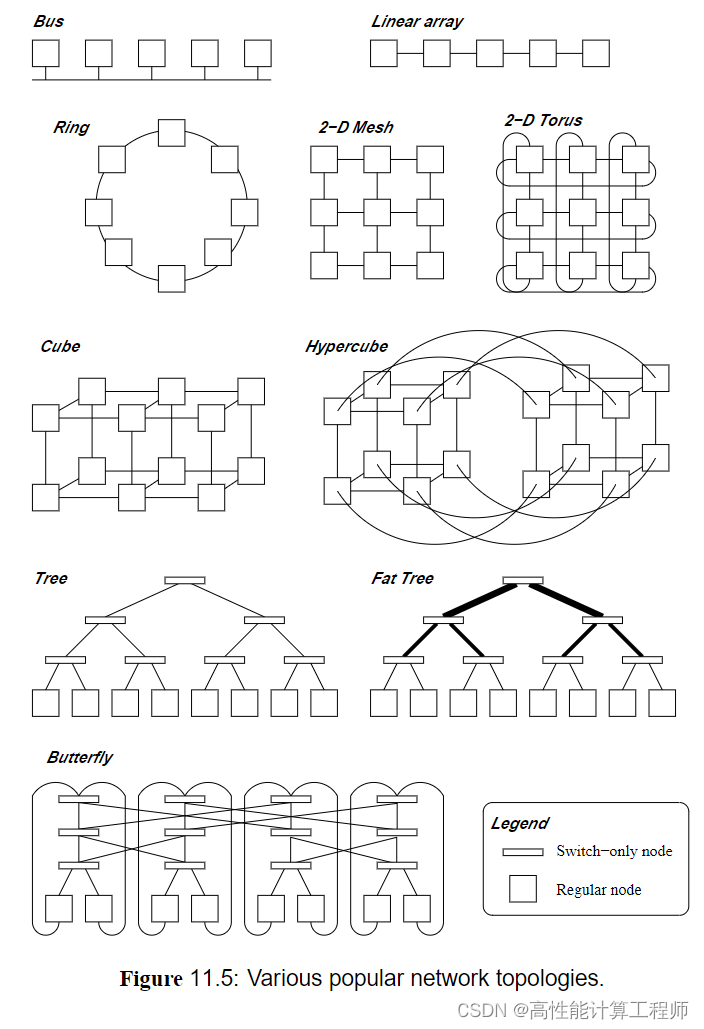
在树中,节点位于叶子上,彼此不直接相连,它们通过中间路由器连接。树存在有限带宽问题,根级链路接收的流量多于叶级链路。为了避免根级链路成为系统的瓶颈,可以使用两种相关的拓扑。一种是胖树,与低层级链路相比,胖树具有更胖的高层级链路。另一种是蝶形网络,它实际是一种具备多个高层中间路由和链路拷贝的树。由于蝶形网络中各级链路和路由器的数量相等,它在根级链路不会受到有限带宽的影响。

11.6 多核设计问题
关于单个芯片上互连核称为片上网络NoC体系结构。虽然芯片间的互连网络和NoC在网络拓扑、路由、死锁和路由器体系结构方面面临类似的设计问题,但NoC具有多核特有的设计特性。
NoC特性:
1. 布线:用于互连的布线通常限制在上层的几个金属层,这些金属层是与电源和时钟信号分发网络共享的。
2. 链路延迟和路由器延迟关系:在芯片间互联的场景下,链路延迟与路由器延迟相比是显著的。在NoC中设计低延迟、高度流水化的路由器变得越来越重要。
3. 功耗:NoC将于核或高速缓存等其他组件竞争芯片功耗预算,因此选择低功耗NoC设计非常重要。

当前设计问题:
1. 不规则拓扑:在某些情况下,多核芯片可以集成异构核、异构高速缓存和各种IP块。导致异构通信带宽的增加。
2. 服务质量:对QoS的需求随着多核多样性的增加而增加。
3. 功耗管理:用于NoC的功耗管理技术可分为减少静态功耗和动态功耗,为了减少静态方面,一种可能的技术是响应网络流量的突发和骤降而对端口和链路进行功率门控。缺点是遭受高延迟的风险,因为组件需要一定时间来再次通电。为了减少动态方面,一种肯呢个的技术是动态电压调节,当路由器或链路的带宽利用率低时,调低它们的电压。
4. 电路交换:优点是连接一旦建立,消息可以高效传输,具有最小的缓冲量,同时由于不需要对路由器资源进行仲裁而具有非常小的路由器延迟。缺陷是带宽利用率低以及连接建立延迟高。但是它在某些情况下更具有吸引力:高路由器延迟、多跳和较大的分组。















 6340
6340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









