







通义千问(Qwen)是阿里云推出的一个大规模语言模型系列,专注于提供广泛的知识和普适性.
发展历程
- 2023年4月:通义千问首次问世,标志着阿里云在大语言模型领域的初步探索。
- 2023年8月:宣布开源,推出了参数规模从5亿到1100亿不等的多个版本,适应不同场景的需求。
- 2023年9月13日:正式向公众开放,强调其跨领域的知识和语言理解能力。
- 2023年至2024年间:持续迭代升级,增加了文生图、智能编码、文档解析、音视频理解等功能。
- 2024年5月9日:在北京举办的AI智领者峰会上,发布了通义千问2.5版本,并宣布原通义千问APP更名为“通义APP”,集成全栈能力。
版本介绍
- 初代模型至2.0版本:自发布以来不断迭代,通过邀请用户测试体验逐渐优化,并成为国内首个开放公测的大模型应用产品。
- 通义千问2.5:
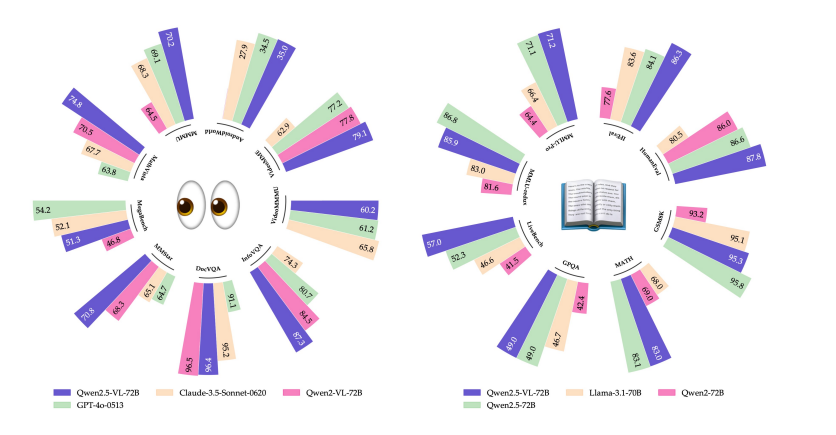
- 相比前版,在理解能力、逻辑推理、指令遵循、代码能力等方面分别提升了9%、16%、19%、10%。
- 开源了包括语言模型、视觉语言模型、音频语言模型以及数学语言模型在内的多种类型模型,覆盖了从0.5B到72B的不同参数规模。
- 提供了基础模型和指令调优模型,适用于不同的应用场景。
- 支持通过API调用、模型下载等方式接入,个人用户可通过APP、官网和小程序免费使用。
核心改进
1、动态NTK-aware RoPE:
一般的语言大模型只能处理几千到几万个token,如果输入的文本太长,就会被裁剪掉,一般会从前裁剪--左截断,导致输入文本不能被完全的理解,通义千问团队推出的Qwen2.5-1M系列模型,将上下文长度提升至100万tokens,这意味着模型可以一次性处理相当于一本中等长度小说的文本内容,支持超长文本推理。
2、混合注意力机制:
结合MQA(多查询注意力)和GQA(分组查询注意力),显存占用降低30%。
混合注意力机制是一种旨在优化传统Transformer架构中自注意力机制的技术,通过结合不同的注意力策略来降低计算复杂度和显存占用。具体来说,MQA(多查询注意力)和GQA(分组查询注意力)是两种改进的注意力机制设计。
多查询注意力(MQA)
在标准的自注意力机制中,每个token都会生成一组查询(Q)、键(K)和值(V)向量。而在MQA中,只有查询向量是为每个head独立计算的,而所有head共享相同的键和值向量。这种方法减少了需要计算和存储的参数数量,从而降低了显存占用和计算成本。
分组查询注意力(GQA)
GQA可以看作是MQA的一种扩展或变体,它将查询、键和值向量划分为多个小组,每个小组内部共享这些向量,但不同小组间保持独立。这种方式既保留了模型捕捉不同上下文信息的能力,又进一步减少了计算开销和内存需求。
混合注意力机制的优势
当结合MQA和GQA形成一种混合注意力机制时,其主要优势在于:
-
降低显存占用:通过减少需处理的参数数量,尤其是对于大型模型而言,能够显著降低显存占用。据称,这种混合方法可使显存占用降低30%。
-
提高效率:不仅节省了内存资源,也加快了计算速度,使得训练和推理过程更加高效。
-
维持性能:尽管进行了上述优化,但通过精心设计的混合策略,可以在不明显牺牲模型性能的前提下实现这些节省。
3、激活函数优化:
采用SwiGLU v2,增强非线性表达能力。
SwiGLU(Swish-Gated Linear Unit)是一种结合了Swish激活函数和门控线性单元(GLU)的混合激活函数

核心特性
- 门控机制:通过Swish激活的权重动态调节信息流,过滤不重要信息;
- 平滑性:Swish的连续可导性缓解了ReLU的梯度消失问题;
- 非单调性:允许模型捕捉更复杂的非线性模式;
- 参数效率:相比传统FFN(ReLU + 线性层),SwiGLU通过门控减少冗余计算。
4、量化感知训练:
原生支持GPTQ-Int4量化,精度损失小于1%。
将神经网络中的权重和激活值从高精度(如32位浮点数FP32)转换为低精度(如8位整数INT8或4位整数INT4)
主要架构
输入嵌入层:支持多语言Tokenizer,词表大小152K,包含中/英/代码/符号等混合语料
最多支持29种语言。
位置编码:动态NTK-aware旋转位置编码(RoPE),自适应调整基频。
Transformer层:32层,每层包含:混合注意力(MQA/GQA 动态切换)、SwiGLU v2前馈网络
、RMSNorm归一化。
输出层:动态权重投影,支持多任务输出(文本生成、分类、回归)
注意:通义2.5也是only-decoder结构
最后
尽管通义千问3.0已在多个方面实现升级,具备更强的推理能力、更广的知识覆盖和更优的多语言支持,但2.5版本在文本理解、代码生成、逻辑推理等方面依然表现卓越,尤其在中文场景上稳定可靠。对于许多开发者和企业而言,通义千问2.5仍然是高效、实用的选择,能够满足大部分自然语言处理任务的需求,在实际应用中持续发挥着重要作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









