






对于区块链智能合约安全的内容总结
对于近几年对于该问题的解决方法有以下的三种解决方式,当然不仅仅局限于这三种方法;
1.把源代码当成一个文本内容进行输入利用(NLP)的技术模型(N-gram 以及 bag-of-words)
2.利用ASTs也就是抽象语法树,并且从ASTs中抽取出不同的调用路径用来学习序列样本
3.利用GNN模型,把源代码转换成图(这个图是图论中的图使用而不是images)
说完了具体的方法后,说一下抽象的方法;
1.静态分析法;通过对智能合约源代码进行静态分析,检测其中的漏洞。这种方法主要是基于代码分析,例如通过程序分析器、符号执行器等自动化工具来识别漏洞,但是无法检测到动态生成的合约,也无法考虑合约的上下文和交互行为。
2.动态分析法;通过对智能合约进行动态运行测试,检测其中的漏洞。这种方法主要是基于交互式测试,例如通过模拟攻击环境,生成不同的交易和操作序列,来发现漏洞,但是该方法需要消耗大量的计算资源,且无法完全涵盖所有可能的交互情况。
3.混合分析法;将静态分析和动态分析方法结合起来,通过对智能合约进行全面分析,检测其中的漏洞。该方法可以综合考虑智能合约的静态和动态特征,更加准确地检测漏洞,但是也需要消耗更多的计算资源。
4.人工审核法;通过专业的审计团队对智能合约进行人工审查,识别其中的漏洞。这种方法可以发现各种类型的漏洞,但是需要投入大量的人力和时间成本。
先介绍我最早接触到这个方面所阅读的一篇论文,很明显这个是基于静态分析(中的符号执行)的方法进行实现的,也就是DEFECTCHECKER: Automated Smart Contract Defect Detection by Analyzing EVM Bytecode,这是使用JAVA写的漏洞检测方式出现这个领域的背景是智能合约作为一个图灵完备的系统,不同以往的代码最大的特点就是可以持有加密货币,这也就给了攻击者们的攻击动机。另一方面,又由于合约的bytecode是公开的在permission-乐山市、
Network上面,因此攻击者们也就可以检测到是否有这种漏洞,而且数据集是作者们自己所准备的Defining Smart Contract Defects on Ethereum 相比于其他检测工具例如Oyente,mythril 以及 securify而言对于F-score以及每个合约的检测时间长短有所提升。。
主要贡献:more accurate 和 fastest
Ethereum Virtual Machine;以太坊虚拟机是一个基于栈的状态机,当一个交易需要执行时候,首先会把bytecodes分成byte,并且每个byte代表一个opcode,并且每一个opcode有独一无二的16进制数来表示。
总体的方案设计;
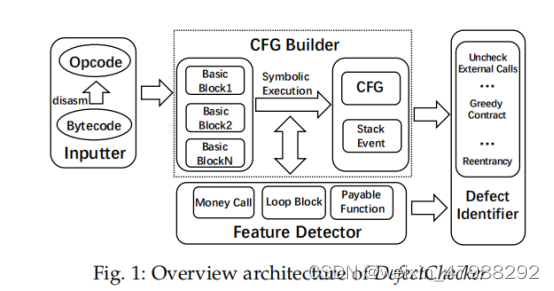
总体的设计主要包含有四个模块,inputter,CFG构造,feature 检测器,以及defect 分类器
最左边部分,首先利用geth把bytecode转变成opcode,然后把opcode转变成basic块,并且符号执行每个块中的指令集合,然后DC生成CFG并且记录所有的stack events(?),在符号执行的过程中,特征检测器检测三种特征,分别是Money Call Loop block 以及 payable function,基于此,DC辨认器会使用八种不同的规则去辨别到底是那种漏洞(很明显也使用了专家定义模块)
Basic Block Builder基本块的构造:
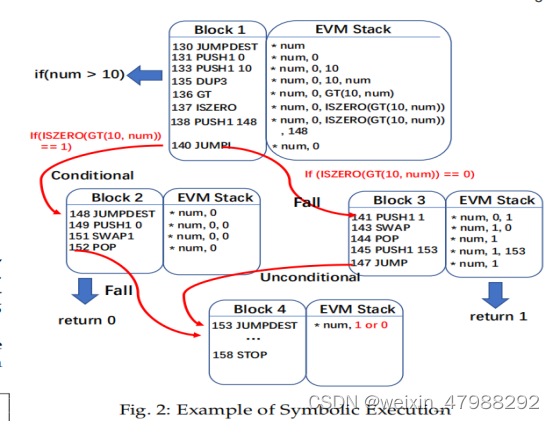
网站链接:https://paper.seebug.org/790/ 这里面有具体基本块的构造方法,这里笔者就不过多的赘述了
符号执行:
以太坊虚拟机不同于以往基于栈的状态机,evm字节码的跳转的位置需要被计算出来当符号执行期间,因此DC需要去符号执行evmopcode中的每一个opcode于此同时获得CFG.这里回答上一个问题也就是什么是stack events(它会记录所有的符号执行后的关于evm栈的状态)
这个图构造成CFG就是上面贴出来的图。

Feature detector
1 MONEY CALL
为了检测reentrancy漏洞,我们要检查是否这里存在一个转账操作,也就是说是否存在address.send,address.transfer address.call.value 所有的这些转账方法都是会产生CALL指令等。然后,仅仅只是检查是否有CALL 指令是不够的。因为在这篇文章中如果是CALL指令是由transfer ethers所产生的我们就把CALL称为money-call,否则就是no-money-call.call会读取七个栈里面的指令,前面三个就是gas limitation,recipient address.transfer amounts如果说 transfer-amounts>0那此时我们就可以确定Call为money-call
此时,只考虑money-call仍然不够大因为send以及transfer都没有办法造成重入攻击,所以此时我们还需要关注一个具体的值2300,应为只有send与transfer生的才会有一个具体的数字2300压入evm 栈中。这就代表着maximum gas consumption,只要这两点都确定之后我们才知道是否是call.value
2 LOOP BLOCK
在构造了CFG后,我们需要去关注那一个块是一个循环的开头,以及那些块构成了循环体。为了这个问题,我们一开始需要去遍历CFG所有路径通过DFS,然后标记我们已经访问过的,最后,如果我们走到了一个我们已经访问过的block,那么这个block就是起点,而其他的就是循环体.
3 PAYABLE FUNCTION
为了检查是否一个函数可以接受ether,一个函数只有包含了payable关键字才可以接受ether.为了检测他我们可以检查每个函数的第一个块,CALLVALUE指令被用来去显示接受ether的金额.如果它接受了ether那么callvalue是一个非零值.并且它可以被一个指令ISZERO来检测
下面就是DC的具体检查方法了
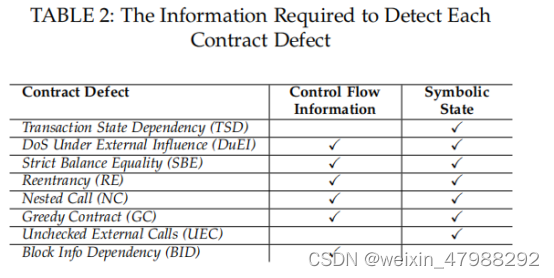
这个图显示了检查那个漏洞需要什么具体的条件.DC缺点:可能造成假阳以及假阴当检测NC DuEI时候。
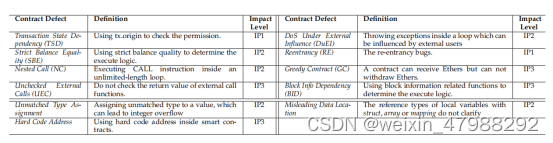
对于这几种漏洞的检测原理,在当前的背景下;
TSD也就是交易状态依赖也叫做tx.origin攻击,主要是利用了tx.origin与msg.sender之间的定义混淆的问题,具体的检测方法;
Tx.origin会生成ORIGIN的指令,所以我们使用符号执行对于bytecode分析的时候,需要额外关注ORIGIN这个指令。之后我们需要检测是否在ORIGIN后有EQ指令所读取。如果有这个eq指令会比较两个地址的值。
Dos under External Influence
如果一个智能合约包含这种漏洞,在它的指令集合中就会存在检测Money CALL的返回金额,并且停止当前的循环调用,为了检测这种漏洞,我们就需要找到与循环相关的块。然后,我们检测是否有一个块中是否包含着Money CALL,以及当前这个块是否是conditional,因为这样的话这个块需要检测返回值。然后这个块会跳往一个terminal块。
还有几种就交给读者自己阅读了,这里就不过多赘述了;
总结:这篇文章很明显就是一个静态分析的案列,所以对于一些实际发生的事情,以及一个漏洞的变体就无法精确的定位到。可以就会造成假阳,假阴等结果,但是它对于opcode的操作还是一个比较经典的操作方式了。可以作为拓展思维
ok现在来介绍第二篇文章啦
Reentrancy Vulnerability Detection and Localization: A Deep Learning Based Two-phase Approach这篇文章与Peculiar: Smart Contract Vulnerability Detection Based on Crucial Data Flow Graph and Pre-training Techniques 这篇文章是有相似之处的
传统的检测方法是无法定位具体漏洞的位置的,这篇文章做到了,但是也只能检测重入漏洞。摘要解释:ReVulDL这个框架整合了漏洞检测以及漏洞定位,并且它使用了一个基于图的预训练模型,去学习合约中各个变量之间的复杂关系的传播链。而对于漏洞定位ReVulDL则是使用了一个Interpretable machine 去学习定位可疑statements在合约中的具体位置,它使用了DL的方法也就是NLP。
具体的检测过程如下:
数据预处理
文章中首先对区块链合约进行了数据预处理,将其转换成对应的控制流图。控制流图是一个有向图,它表示了程序执行时所有可能的路径。
模型训练
在数据预处理完成后,文章使用了一个基于深度学习的分类器来判断合约是否存在可重入漏洞。该分类器使用了卷积神经网络和长短时记忆网络,通过学习输入的控制流图来输出对应的分类结果。
注意力机制
如果分类器输出合约存在可重入漏洞,那么文章接着使用了一种注意力机制来定位漏洞所在的代码行。注意力机制可以将模型对合约的关注点集中到最有可能存在漏洞的代码行上,从而提高了定位的准确性。
模型评估
最后,文章使用了多种指标对该方法进行了评估,包括准确率、召回率、F1值等。实验结果表明,该方法在检测和定位可重入漏洞方面具有较高的准确性和可靠性。
综上所述,这篇文章的原理是使用深度学习技术对合约进行分类,判断是否存在可重入漏洞,并使用注意力机制定位漏洞所在的代码行,最终达到检测和定位可重入漏洞的目的。
相比于传统的动态以及静态的检测方法,这最大的改变就是可以不使用人工定义的启发式算法(manually crafted heuristics),而对于近几年出来的基于DL的方法有很多好处…,但是对于具体漏洞的定位做的还不是很完善,此外漏洞检测以及localization是两个交互性任务,一般来说定位,利用的是漏洞的特征。因此在这个背景下提出来了这篇文章的框架。
对于漏洞检测阶段;
具体来说,考虑一个智能合约SC,ReVulDl首先会构造CHsc的传播链也就是调用链利用SC的源码的data flow graph;接着利用一个基于图的预训练模型去学习调用链之间复杂的关系(比如说数据依赖关系等),然后最后使用一个训练好的模型去决定是否当前的智能合约包含reentrancy漏洞
对于漏洞定位阶段;
如果在SC中检测存在重入漏洞,利用IML去定位;具体来说,ReVulDl首先(准备好检测智能合约的具体信息 比如说下训练好的模型对于是否这个合约有漏洞与否)以及SC在测试数据集中的传播链。然后利用post-hoc interpretability method 去寻找智能合约调用链的最小与漏洞相关的子链,利用的原理是如果一条边eSC在CHSC中是关键的对于检测漏洞,eSC应当被包含在minCHsc中,并且最后使用crucial variables以及他们的传播链在minCHsc去定位可疑statements潜在可能造成漏洞的;
主要贡献;
1.提出这个框架
2.不仅可以实现检测漏洞还可以定位具体位置
3.在large-scale dataset 进行了实验,并且实验效果非常好
基础知识.
Interpretable Machine Learning
本篇文章使用的是post-hoc interpretability 也就是事后可解释性;他们的目标是在不改变基础模型的情况下,提供对已获得哪些知识以及解释模型中学习表示或特征的哪一部分负责预测结果的理解。
Propagation chain-传播链
传播链是指一定数量的指定程序代码片段之间存在一个代码序列。在这个序列中,任何两个相邻的代码片段之间都存在直接或间接的数据/控制依赖关系。在本文中,我们使用数据流关系来构造传播链,因为它们在相同源代码的不同抽象语法下是相同的语义是相同的,并且更易于深度学习模型学习。例如,构造c = a + b的数据流图后,可以清楚c的值依赖于a和b,为理解变量c的语义提供了新的视角。因此,ReVulDL 利用智能合约传播链中的关系,使用基于图的预训练模型来学习关系以检测重入漏洞。
Data-preparation 数据准备
ReVulDL首先需要准备数据(智能合约代码特征以及传播链)。对于一个智能合约而言,REVULDL提取出不同类型的数据通过以下的两个steps:1.智能合约源代码的表示.re会捕获智能合约源代码的内容以token序列也就是单词序列的方式.没一句源代码的单词都会被收集然后打乱成为一个sequence。ReVulDL 去掉了一个字符的 sub-token,以避免噪声的影响。具体来说,假设有一个合约A,从A开始,源代码集为C = {c1, c2, …, cmc},变量集为V = {v1, v2, …, vmv}。然后,将两个集合拼接成一个序列 I = {[CLS], C, [SEP], V },其中 [CLS] 是两个集合前面的特殊标记, [SEP] 是拆分的特殊符号源代码集 C 和变量集 V。对于 A 的表示,序列 I 被转换为输入向量,其中每个token由token本身及其位置的embed表示。
Construct of propagation chains
ReVulDL首先将智能合约源代码解析成抽象语法树(AST);然后从AST中提取数据流关系;最后从数据流关系构建传播链。具体来说,ReVulDL 使用 treesitter(一个转换源代码变成ASTs的工具github有源码可以直接调用) 将源代码集 C = {c1, c2, …, cmc } 转换为 AST,来自源代码 C 的 AST 包含合约源代码的语法信息,而终端(叶子)用于获取变量集 V = {v1, v2, …, vmv }。对于变量集合 V = {v1, v2, …, vmv } 中的每个变量,标记为 vi ,我们创建一条从 vi 到 vj 的直边 ε = vi , vj ,表示第 j 个变量的值来自于或是从第 i 个变量计算的。
Reentrancy Vul 检测过程
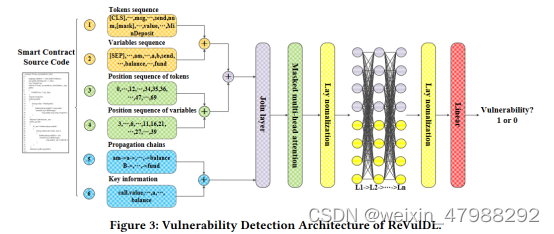
由6个部分组成,分别是input unit、join layer、masked multi-head attention layer、layer normalization layers、n transformer layers和linear layers。Data Preparation构建的ReVulDL中有6个输入单元:token序列、Variable序列、token位置序列、Variable位置序列、传播链和关键信息。具体的检测过程看这篇blog过程链接
Reentrancy vulnerability localization
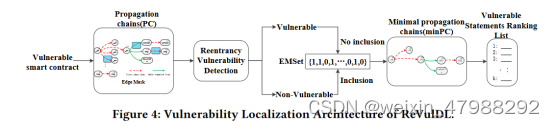
主要就是PC转化成minPC在这一部分主要需要实现,同时在利用事后解释器去定位漏洞的具体位置。
具体的总体结果如下所示:
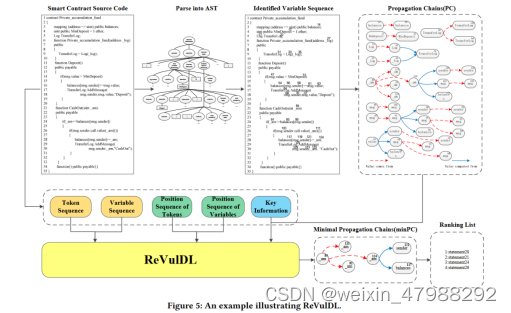
这篇论文的实验是可以复现的;具体操作看作者写的readMe文件就可以了。还有一些细节技术实现这里就不介绍了(笔者也没看懂)
实验部分
评估指标:利用precision ,recall,以及f1分数
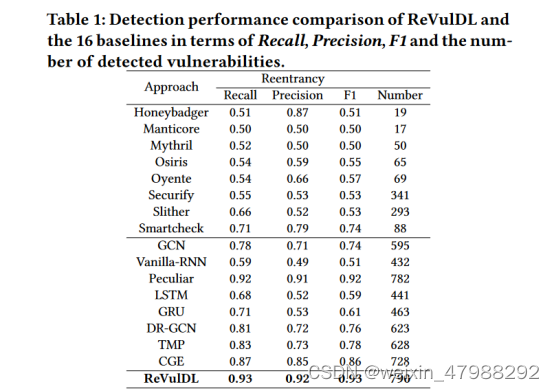
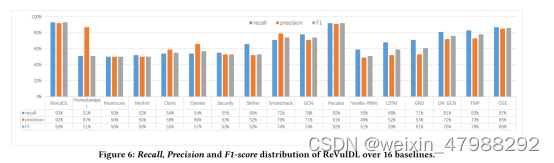
能够拓展的部分就是去检测其他的漏洞
这篇文章的insights 就是实现漏洞代码的localization
第三篇文章Smart Contract Vulnerability Detection Using Graph Neural Networks这篇文章的话,就是近几年来使用GNN比较典型的检测漏洞框架的文章,在检测三种漏洞分别是reentrancy、timestamp 以及 unlimited loop,这三种漏洞检测是这篇文章的主要目的;
摘要;现存的工作方法对于智能合约漏洞检测的方法很严重的依赖于固定的专家模式也就是expert rules,这样的话导致不能检测漏洞的变体,有较高的假阳性以及假阴性。具体的技术实现是使用了一个DR-GCN以及一个TMP去实现具体我们所需要的tools
具体的方法,这里笔者简单介绍一下。首先,我们把智能合约的源代码转换成一个图,根据项目语句之间的数据流或者控制流,不同于之间的文章直接使用源代码或者利用opcode,而在这个图里面每个节点代表关键的函数调用或者说是变量,与此同时,边的话就代表他们的执行顺序。由于大部分的GNNs本质上是平面传播的(也就是说每个节点被GNN一视同仁的)在信息传播上,因此我们就需要把图减少,使用一个归一化过程去吧图进行减少。然后把GCN扩展为DR-GCN去解决归一化过程。ok,下面我们就需要去考虑边的问题的。我们需要考虑不同的角色以及时序关系在不同的项目元素之间并且提出了一个新颖的时序传播网络(TMP)
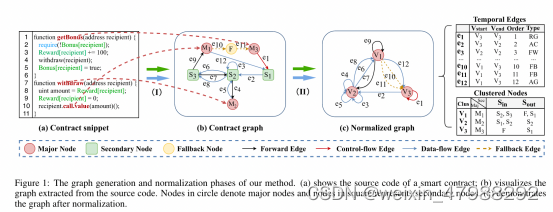
Method overview
分为三个不同的阶段:1,也就是图的生成阶段,他会提取出控制流以及数据流的语义从源代码中并且清楚的回退机制;2,一个图的归一化操作收到了K-partite graph k分图;3,新颖的消息传播序列对于模型以及漏洞检测
Graph Generation
收到了之前的文章能够在提取数据的时候仍旧保存不同项目元素之间的语义关系,主要是点的构造分为了major,secondary,fallback,三类节点的使用。对于重入漏洞而言,怎么样挑选重要节点。主要节点象征着对检测特定漏洞很重要的自定义或内置函数的调用。一个节点的建模指的是有对转账函数的调用或者说是内嵌了call.value的函数。这两点对于检测重入是很重要的。
secondary nodes构造,主要节点代表重要的调用,次要节点用于对关键变量建模,例如user balance和bonus flag。形式上,关键变量定义为次要节点 S1、S2、…。 . . etc。
回退节点构建。此外,我们构建了一个回退节点 F 来激发攻击合约的回退功能,它可以与被测功能进行交互。回退功能是智能合约中的一种特殊设计,是许多安全漏洞的成因。
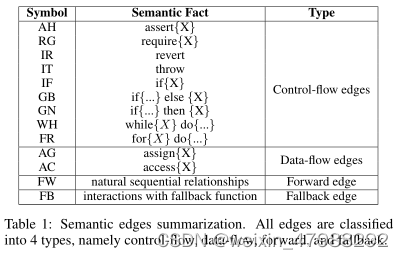
我们利用边来表示不同节点之间的之间的丰富的语义信息。每一条边都代表我们现在合约调用的一条路径,同时还要保存边的次序。我们可以把边变成一个元组tuple(Vs,Ve,o,t),o代表时间顺序也就是说是第几条边,t也就是边的类型;
Contract Graph Normalization
主要是只保存重要节点,其他的节点S与F都淘汰,需要注意的是当进行合并的时候被合并的节点的特征要传播向相邻的主要节点,需要注意每个节点都需要要传播去相邻节点。
对于合并之后的主节点有三个节点也就是,self-feature,S-in以及S-out,图构造好了之后,现在就是检测的过程了;
具体的技术;DR-GCN 是Kipf and Welling 提出的一种新的卷积神经网络去处理结构化的图数据。
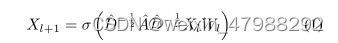
A_hat = A + I A是邻接矩阵自循环I次,Xl 是l层的特征矩阵,而Wl是训练的权重矩阵,在这个等式之中,对角节点度矩阵D_hat被用来归一化A这个A就是我们上面构造好的图。
TMP
这里使用的TMP网络是由一个读入和读出两个阶段组成,TMP会传递信息沿着被边连续的根据他们各自的order来进行传递。TMP计算一个标签label对于整个图的节点聚合。
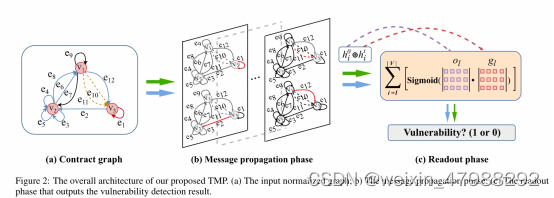
具体的消息传播过程,消息会沿着所有的边进行传播,一个单位时间传播一步。在时间步step0的时候,隐藏状态h_i0对于每个节点Vi初始化Vi节点的特征,在时间步Kth也就是第k条边传播的时候eK,并且更行隐藏状态Vek(这个意思是第k条边的终点节点V)。尤其是,消息Mk的计算是基于hsk也就是基于第k条边的开始节点的隐藏状态信息具体计算公式如下:
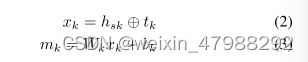
对于具体隐藏状态的更新公式,如下所示;
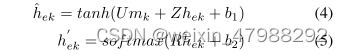
readout阶段也就是具体的消息输出阶段;
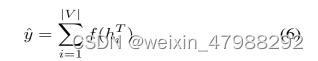
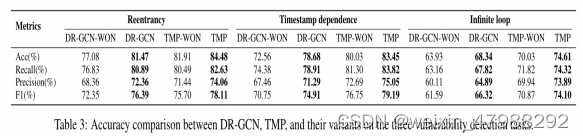
具体的实验检测结果:
IDEA 对于以往GCN的改进,并且混合了TMP机制来融合节点的特征,并且实验结果达到了比较优化的结果















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









