







博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
目录
一.引言
上一篇大语言模型推理服务框架—Ollama介绍了Ollama,Ollama以出色的设计一行命令完成推理框架部署,一行命令完成大模型部署,模型的下载不依赖梯子,速度非常快,大幅提升模型部署效率,同时,当有多卡GPU时,Ollama可以自动将模型分片到各个GPU上,博主使用V100显卡(单卡32G显存)部署llama3 70B(预计需要40G显存),自动完成了显存分配。
今天来介绍一下Xinference,与Ollama比较,Xinference自带Webui与用户交互更加友好,只需点一下所需要的模型,自动完成部署,同时,Xinference在启动时可以指定Modelscope社区下载模型,对于无法登陆抱抱脸的伙伴,可以大幅提升模型下载效率。
这里还是想说两句,大模型领域,美帝目前确实是领先的,我们能做的只能是努力追赶,但在追赶的过程中发现,好多优秀的大模型领域开源项目,都是默认配置hugging face的,一方面是下载模型时间甚至超过了熟悉项目本身,另一方面是压根连不上导致项目跑不起来,导致在这片土地上水土不服。当然对在这片热土上生存的企业及工程师,可能学习门槛的提升,也是一件好事,天热的技术护城河哈哈
二.一行代码完成Xinference本地部署
docker run -it --name xinference -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0- docker run -it:启动docker容器并在内部使用终端交互
- --name xinference:指定docker容器名字为xinference,如不设置随机生成
- -d:后台运行,如果不设置会进入到docker容器内
- -p:9997:9997,宿主机端口:docker容器端口
- -e XINFERENCE_MODEL_SRC=modelscope:指定模型源为modelscope,默认为hf
- -e XINFERENCE_HOME=/workspace:指定docker容器内部xinference的根目录
- -v /yourworkspace/Xinference:/workspace:指定本地目录与docker容器内xinference根目录进行映射
- --gpus all:开放宿主机全部GPU给container使用
- xprobe/xinference:latest:拉取dockerhub内xprobe发行商xinference项目的最新版本
- xinference-local -H 0.0.0.0:container部署完成后执行该命令
三.两行代码完成Xinference分布式部署
master部署:
docker run -it --name xinference-master -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-supervisor -H "${master_host}"work部署:
docker run -it --name xinference-worker -d -p 16500:16500 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace -e "http://${supervisor_host}:9997" -H "${worker_host}"四.开箱即用webui
浏览器打开:http://123.123.123.123:9997/ui/#/launch_model/llm
1.Launch Model
启动模型,包含语言模型、图片模型、语音模型、自定义模型,提供了模型搜索框,基本主流模型都已经收录。
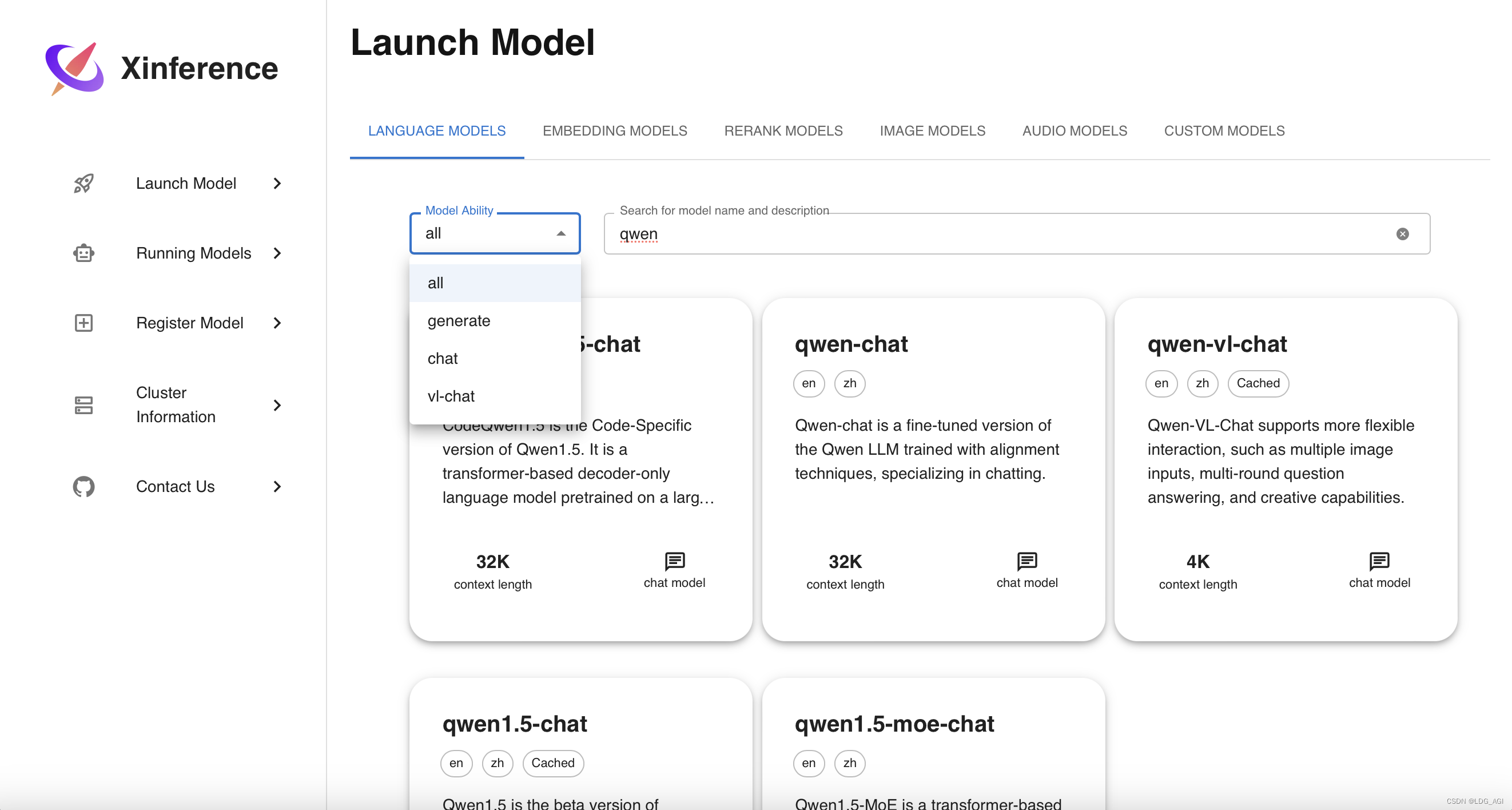
以qwen1.5为例,搜索qwen1.5选择chat版本:
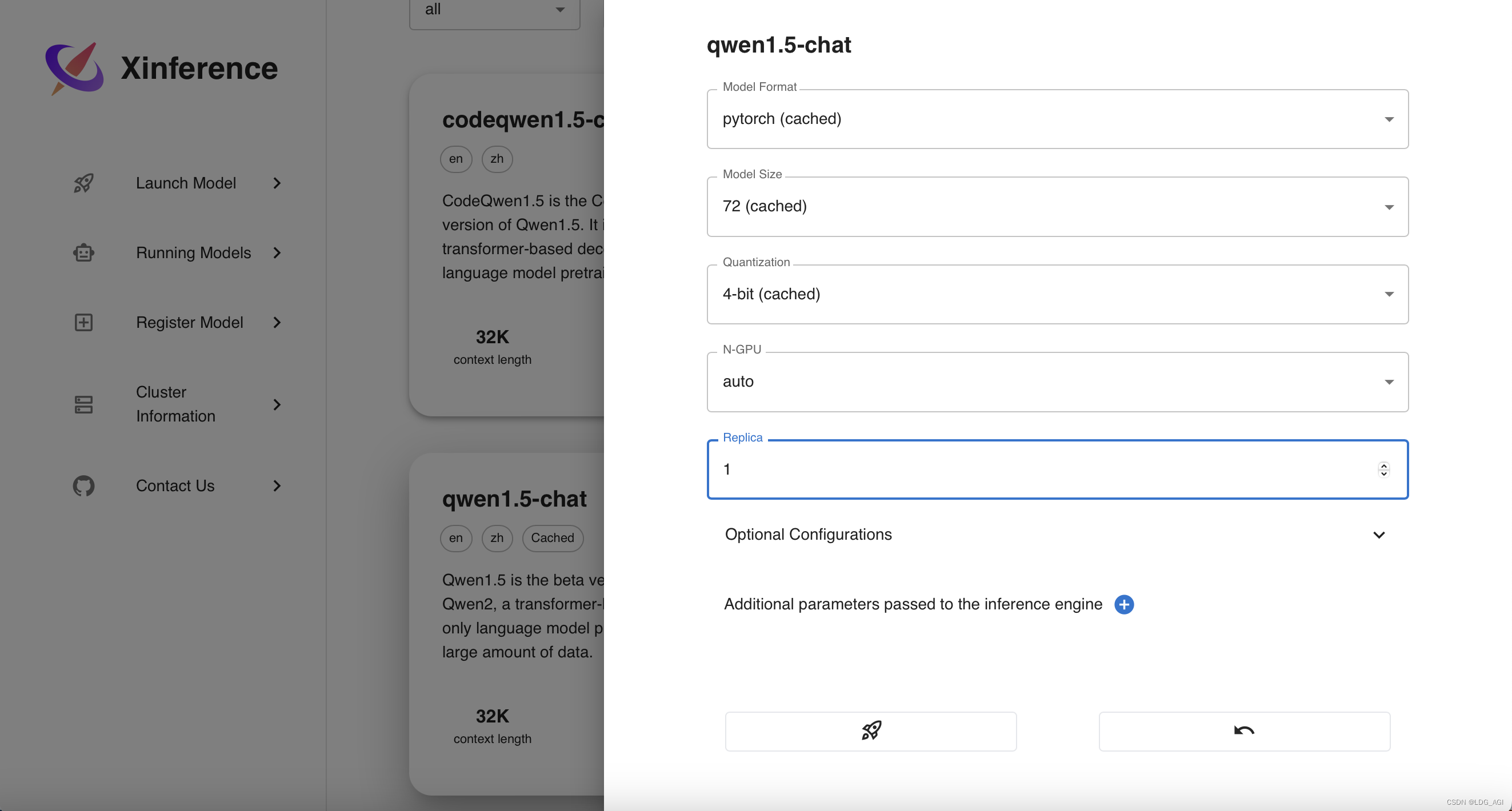
- Model Format(模型格式):包含pytorch、gptq、awq、ggufv2等
- Model Size(模型尺寸):包含0.5B~110B全尺寸模型,
- Quantization(模型量化):包含4位、8位、不量化等
- N-GPU(使用GPU数):可以自动或手动选择使用GPU数
- Replica(副本数量):提供服务的副本数量
点击下面的小火箭,发射(启动)模型模型,会去modelscope上自动下载模型并启动
2.Running Models
模型下载启动后,在Running Models内可查看,可以点击Actions下面的窗口弹出测试UI
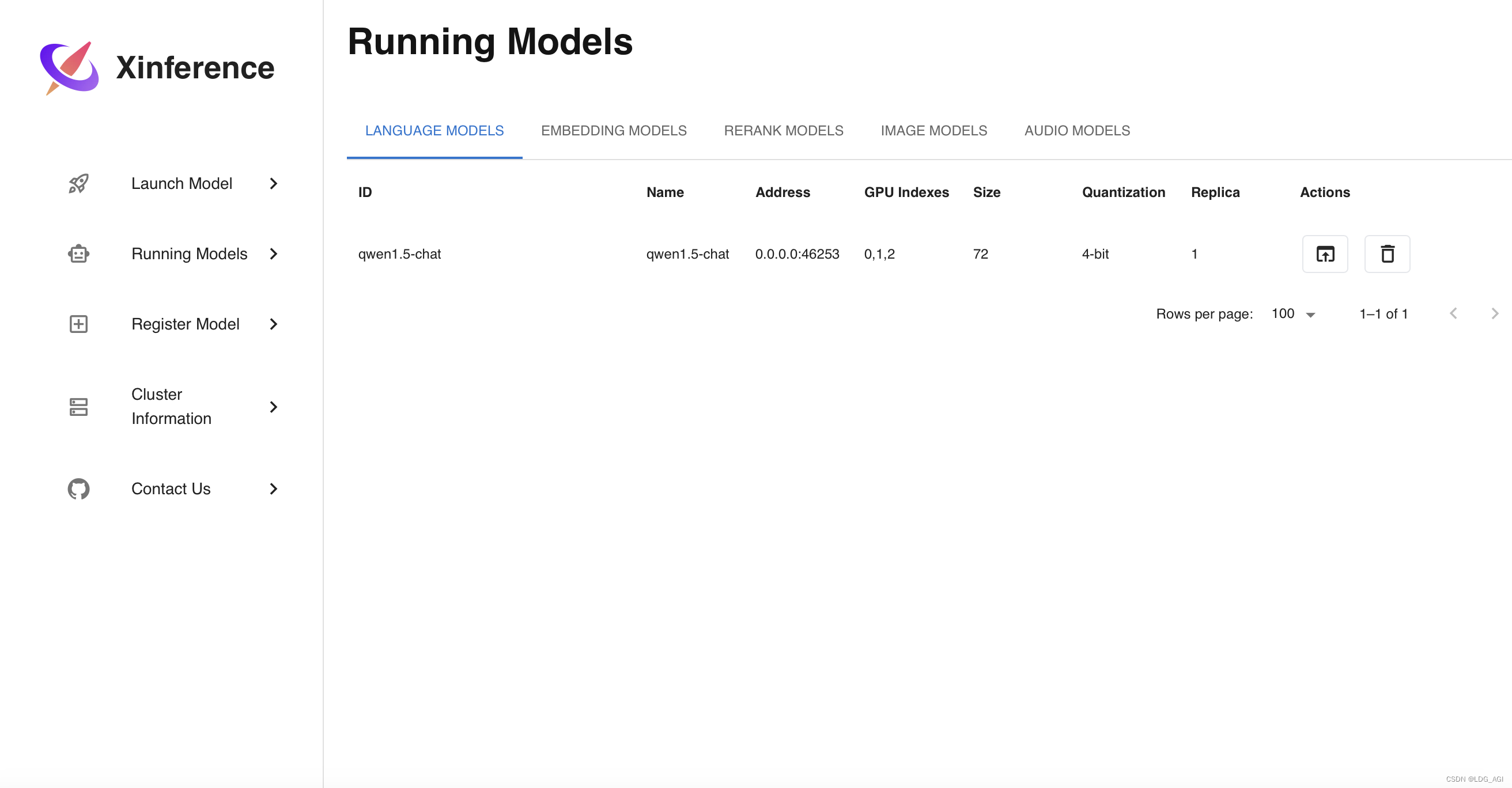
- ID:模型id,后面在调用的时候会用到
- Name:模型name,后面在调用的时候会用到
- Address:模型部署的container端口,后面只会用到宿主机的地址和端口,container状态下后面不需要
- GPU Indexes:GPU索引,Xinference框架会自动根据GPU资源情况切分模型部署在多张卡上
- Size,Quantization:模型尺寸与量化位数
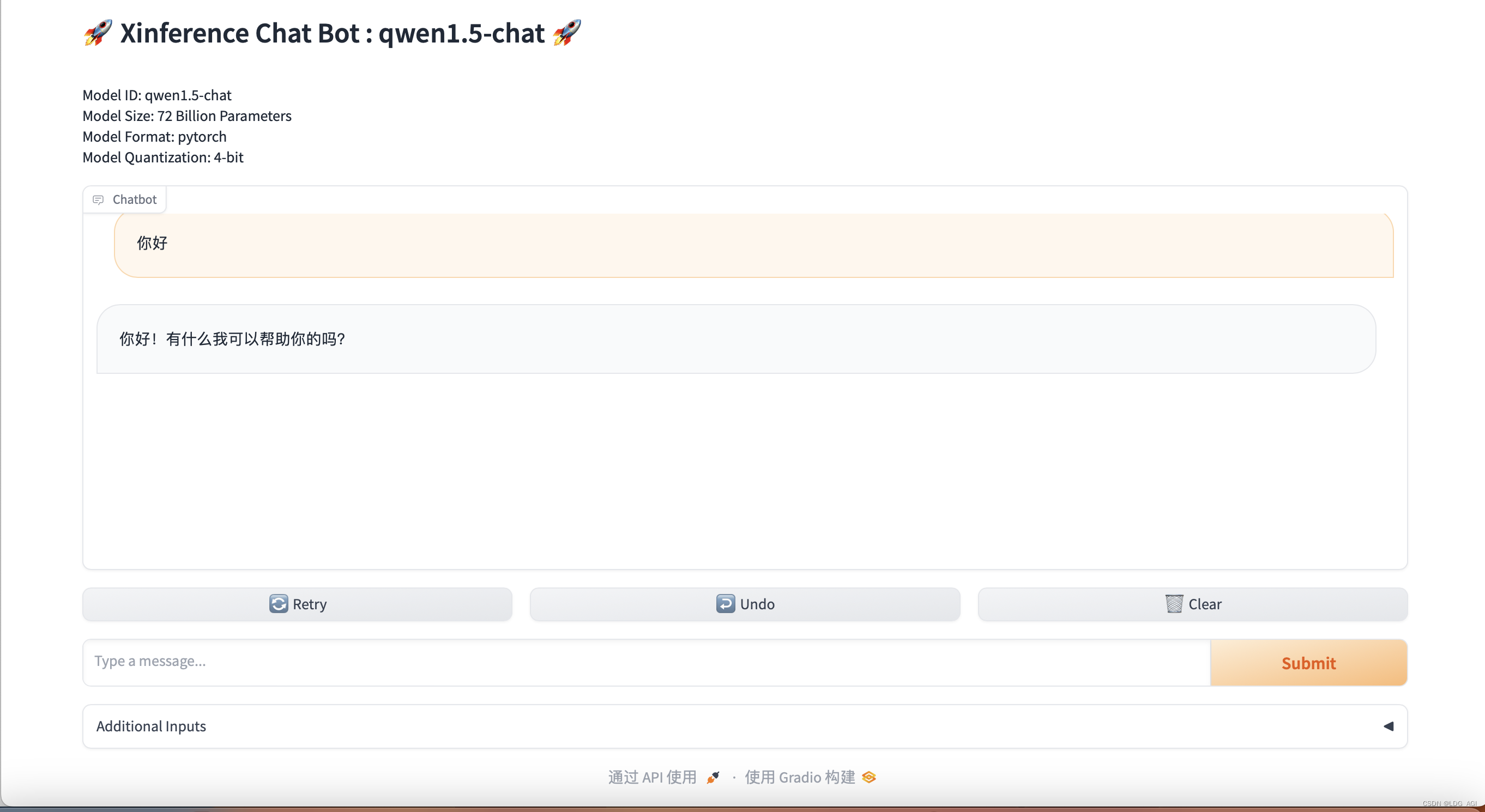
2.1测试qwen1.5-chat
2.2模型存储路径
在启动docker container时,指定了container根目录并且指定了宿主机关联路径:
- -e XINFERENCE_HOME=/workspace
- -v /yourworkspace/Xinference:/workspace
这样不用登陆container在宿主机本地也可以查看下载到的模型
3.Register Model
你也可以注册自己下载或微调后的模型:
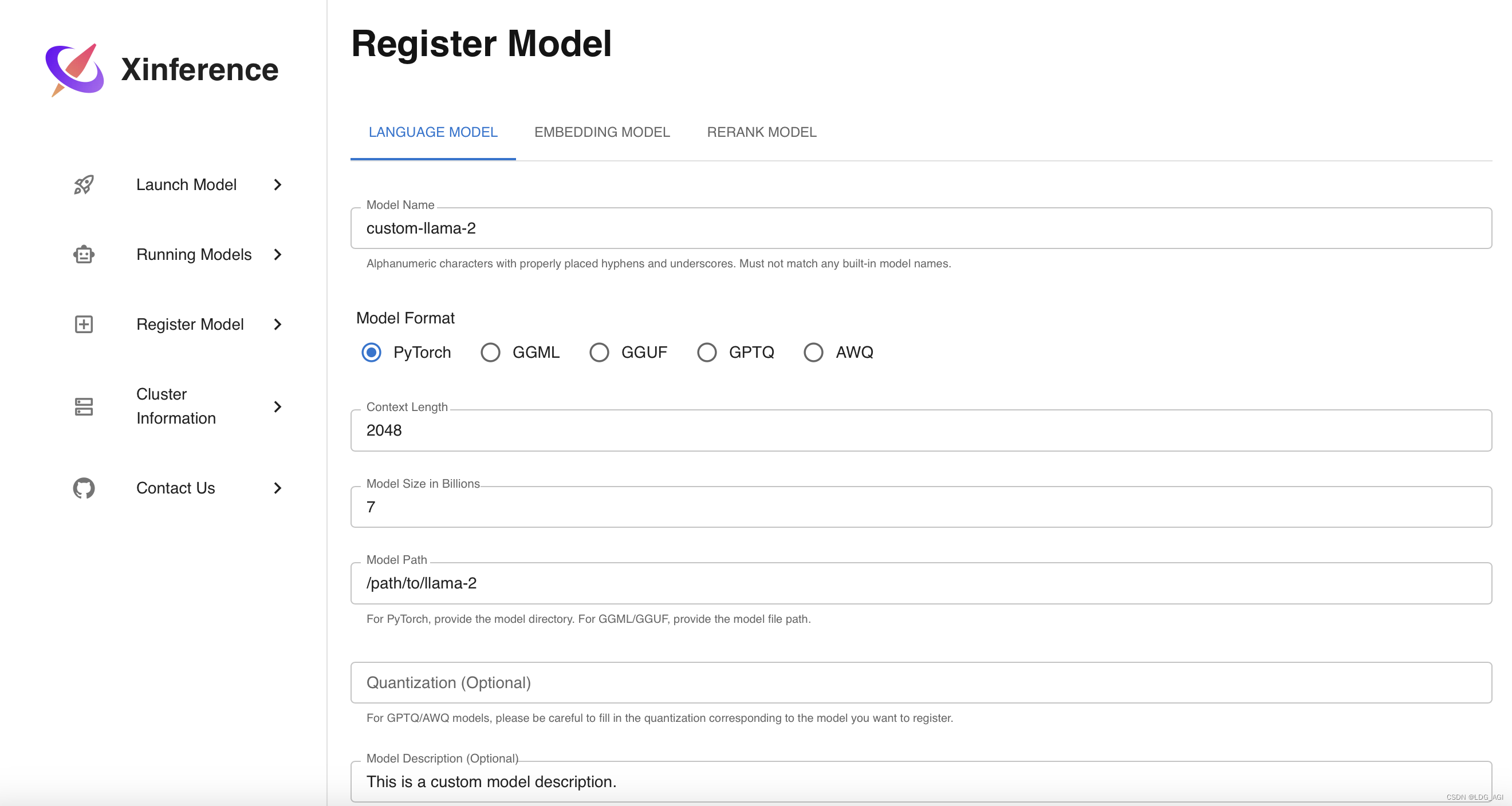
只需要配置模型名、模型格式、上下文长度、模型尺寸、模型路径等
注册完成后在Launch Model — Custom Models 内启动即可。
4.Cluster Information
这里会展示集群Supervisor节点和worker节点的数量以及具体CPU、GPU使用情况,方便管理。
五.模型使用
参考上一篇Ollama,我们可以使用curl或者dify平台调用Xinference部署的推理服务,
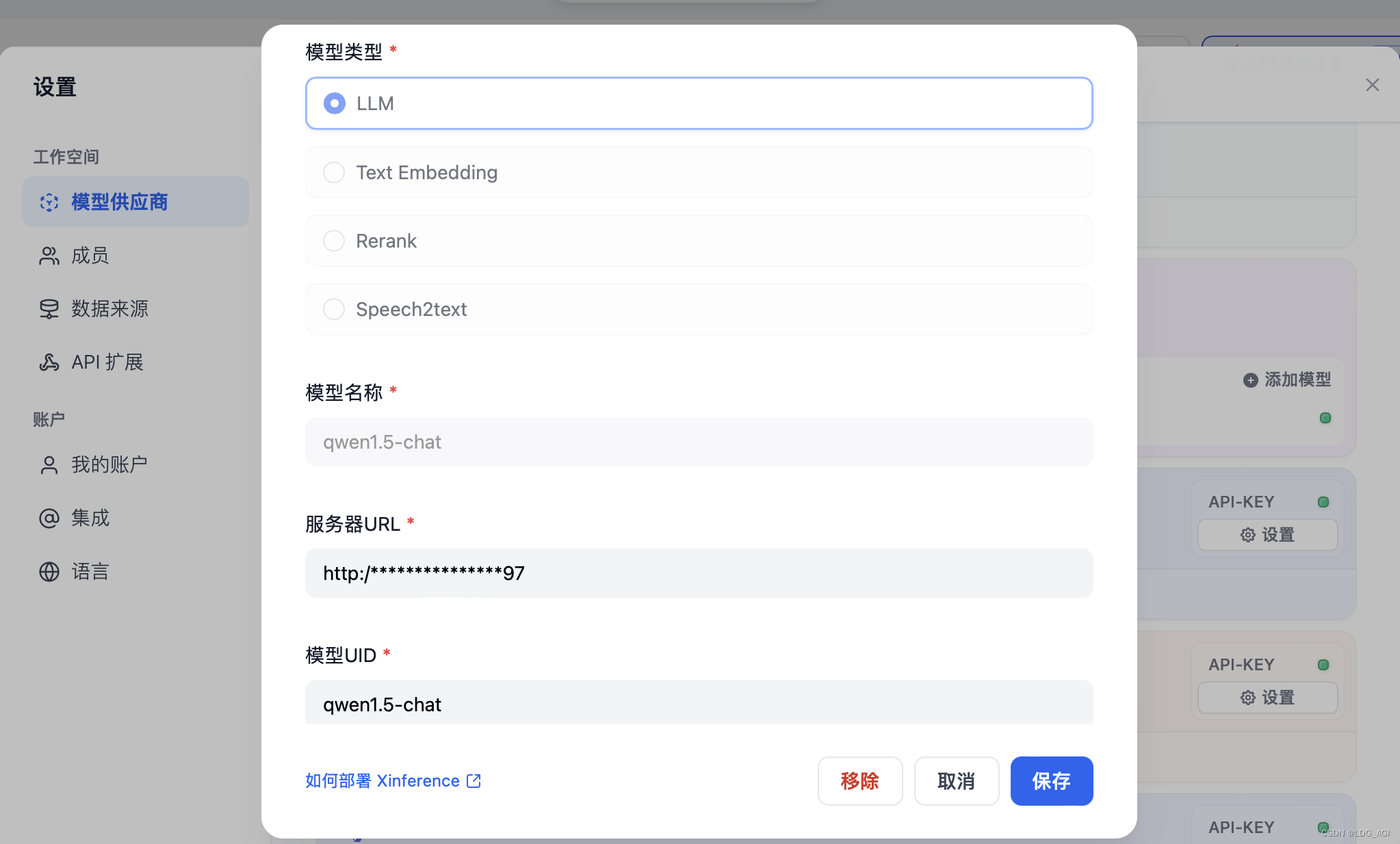
DIFY:只需要配置模型名称、服务器URL、模型UID,其中模型名称和模型UID在Running Models列表中可以查到,服务器URL是http://宿主机host:port。记得带http://否则会报错。
CURL:
与OpenAI一样的post请求:
curl -X 'POST' \
'http://123.123.123.123:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen1.5-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is the largest animal?"
}
]
}'返回:
{"id":"chatd9e11eea-0c57-11ef-b2c7-0242ac110003","object":"chat.completion","created":1715075692,"model":"qwen1.5-chat","choices":[{"index":0,"message":{"role":"assistant","content":"The largest animal on Earth is the blue whale (Balaenoptera musculus). Adult blue whales can grow up to lengths of around 98 feet (30 meters) and can weigh as much as 200 tons (180 metric tonnes). They are marine mammals found in all major oceans, primarily in the Antarctic and Sub-Antarctic waters. Their size is a result of their filter-feeding lifestyle; they feed on large quantities of small shrimp-like creatures called krill, rather than needing to hunt larger prey."},"finish_reason":"stop"}],"usage":{"prompt_tokens":25,"completion_tokens":111,"total_tokens":136}}OpenAI兼容的API:
Xinference 提供了与 OpenAI 兼容的 API,所以可以将 Xinference 运行的模型直接对 OpenAI模型进行替代
from openai import OpenAI
client = OpenAI(base_url="http://123.123.123.123:9997/v1", api_key="not used actually")
response = client.chat.completions.create(
model="qwen1.5-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the largest animal?"}
]
)
print(response)六.总结
本文简要讲述了一行代码完成Xinference本地部署以及两行代码完成Xinference分布式部署以及webui和接口调用,其中快捷部署、极为友好的webui、可配modelscope以及提供兼容OpenAI的API等诸多优点,实属良心之作。
真诚的希望通过写博客的方式将自己涉猎过的大模型开源项目分享给大家,由于个人经历有限,不能保证每篇文章都写的特别深入,但尽量保证内容自己实际操作过,避免大家重复踩坑。如果想了解更多关于Xinference大模型推理框架的内容,可参考官方文档:Xinference官方文档 。
最后,还是很期待大家关注、点赞、评论、收藏噢,您的鼓励是我持续码字的动力!
如果您对AI感兴趣,可以接着看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
















 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









