









0907(049天 线程集合03 线程、死\活锁、juc包)
每日一狗(田园犬西瓜瓜)

线程集合03 线程、死\活锁、juc包
文章目录
1. 死锁、活锁
死锁
死锁:值多个现场因竞争资源而造成的一种僵局(互相等待),若无外力所用,这些进程会一直等下去
产生的四个必要条件:
- 互斥:资源不会被共享而且一份
- 不可被阻断:所持有的资源我占着不用那我没辙
- 请求等待:允许同时申请多把锁
- 循环等待:你等我,我等你…没完没了
避免死锁:
- 给锁加上申请顺序
- 给锁加上一个持有时间
如何判定死锁:
怀疑死锁,获取线程栈信息。
1、获取线程的pid,使用jps查看当前运行程序的进程编号
2、打印线程堆栈:使用jstack pid命令,linux环境可以使用kill -3 pid
然后用 jitwatch 工具帮助分析该日志
活锁
由于某些资源他老是获取不到,就会
解决办法:在程序执行过程加入随机执行
死锁、活锁的区别
相同:处于无法向前推进的状态
不同点:处于活锁线程的状态可以通过等来解决;死锁没辙,等到CPU退休也没办法向前推进
2. 线程饥饿
就是一个线程老是获取不到执行机会,由于线程调度机制是系统实现的,Java程序
无法指定某一线程必须开始执行。
但是可以通过wait、yield、sleep方式来释放CPU资源,让其他线程拥有更多的执行机会。
3. 如何判定一个线程是否用有锁
Thread.holdsLock(Object obj),可以用于判定synchronized的对象是否被获取,
ReentrantLock 的boolean isLocked(),可以判定改锁是否被某个对象获取,
之前感觉
4. 线程相关模型
1)启动一个os的用户线程,然后实际的任何操作都直接对应该用户线程,这就是1:1,这样做之后,调度就由os负责,jvm就不管了,hotspot等主流jvm基本上都是这种做法
2)启动一个虚拟线程,然后执行的时候,交给os上的一个用户线程去执行,这样做的好处就是,jvm可以自己实现调度,而且可以控制虚拟线程的大小,这就是n:m或者1:m,看具体的实现,而如果将线程虚拟化之后,调度就可以由jvm来实现了,做成1:m还是n:m完全看jvm调度的实现,这就是协程,go其实是这种做法,早期的solaris上的hotspot也是这种做法,后来改了,改成选择1的做法,这样在不同os上hotspot的实现就统一了
双检测模型(线程安全单例模式)
忽略volatile关键字程序也可以很好的运行,只不过代码的稳定性不是100%,说不定在未来的某个时刻,隐藏的 bug 就出来了
CAS模型
比较-相等-修改,底层实现使用Java中的原子类来保证CAS操作的原子性。
特性
- 通过调用 JNI(native本地对等类) 的代码实现
- 非阻塞算法:不会出现把别人卡住的情况
- 非独占锁:不是排它锁
存在的问题:
- ABA问题
- 循环时间长开销大
- 只能保证一个共享变量的原子操作
如何解决ABA问题
引入原子引用或者原子标记。可以在其除了数据之外在添加一个标记值来标识改数据的版本,使用时间戳作为版本号,在写入对比的同时对版本进行对比,就可以解决ABA问题。
解决循环时间开销大:
CAS就是对比相同且交换,为了保证线程安全问题,他在发现主内存中的数据与预期的不同时需要重新将这个数据拿出来重新计算,这就导致在竞争激烈的时候修改成功的概率就降低了,这就得用更多的执行次数来进行修改操作。即CAS的在满足线程安全的同时随着临界资源竞争更加激烈效率会越来越低。
解决方法就是加入超时设置,你自旋多少次后就可以去睡会了,不要再抢着修改了。
只能保证一个共享变量的原子操作
有一个原子引用的玩意,我自己封装一个容器不就行了或者传入的直接就是是一个数据容器。
**典型案例:**原子量(待整理)
自定义计数器
public class AtomicCounter {
private static AtomicCounter instance = new AtomicCounter();
private AtomicCounter() {
}
public static AtomicCounter getIntance() {
return instance;
}
// 存储的数据,同时利用CAS提供线程安全的特性
private AtomicInteger counter = new AtomicInteger();
public int getCounter() {
return counter.get();
}
public int increase() {
// 内部使用死循环for(;;)调用compareAndSet(current, next)
return counter.incrementAndGet();
// return counter.getAndIncrement();
}
public int increase(int i) {
// 内部使用死循环for(;;)调用compareAndSet(current, next)
return counter.addAndGet(i);
// return counter.getAndAdd(i);
}
public int decrease() {
// 内部使用死循环调用compareAndSet(current, next)
return counter.decrementAndGet();
// return counter.getAndDecrement();
}
public int decrease(int i) {
// 内部使用死循环调用compareAndSet(current, next)
return counter.addAndGet(-i);
// return counter.getAndAdd(-i);
}
public static void main(String[] args) throws Exception {
final AtomicCounter ac = AtomicCounter.getIntance();
// 可缓存线程池
ExecutorService service = Executors.newCachedThreadPool();
Set<Integer> set = new CopyOnWriteArraySet<>();
for (int i = 0; i < 1000; i++) {
service.execute(new Runnable() {
public void run() {
int rr=ac.increase();
set.add(rr);
System.out.println(Thread.currentThread() + "::" + rr);
}
});
}
Thread.currentThread().sleep(2000);
System.out.println(set.size());
service.shutdown();
}
}
AQS模型
AQS:抽象队列同步器 AbstractQueuedSynchronizer
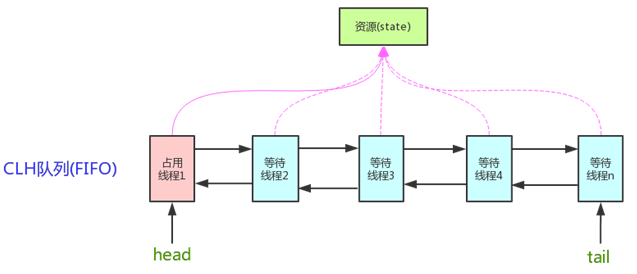
AQS中包含了两个部分
- 临界资源
- 一个FIFO的CLH的阻塞队列(等待唤醒队列):这个就是那个存储没有获取到锁的那个线程存储队列
如果这个共享资源空闲了,则将当前请求资源的线程设置为有效的工作线程,同时将共享资源设置为锁定状态,如果请求的共享资源被占用,那就需要一套线程阻塞等待以及被唤醒是锁分配的机制,这个机制AQS是用CLH队列
5. juc包中几个玩意
信号量 Semaphore
应用场景:有限资源的使用限制
- public Semaphore(int permits)//permits表示初始可用的资源,注意,只是初始值为permits,并不是资源的最大数,通过释放资源的操作可以使可用资源数量超过初始值
- public Semaphore(int permits, boolean fair)// fair等待资源的线程是否采用公平策略获取锁,true即是先来先得。(公平锁)
- acquire()//申请资源,当申请的资源>现有可用资源时,申请资源的线程将被阻塞,直到有可用资源或者申请线程被打断,若线程被打断,则抛出InterruptedException异常
- release()//释放一个资源
Java中的信号量是一个功能完备的计数器,能监控临界资源的等待线程数量。
可以指定可用资源数,可以设定公不公平,按照等待时间来进行
障碍器 公共屏障 CyclicBarrier
应用场景:要有足够多的线程执行到那个步骤才会继续向后走
Java5中添加了障碍器类,为了适应一种新的设计需求,比如一个大型的任务,常常需要分配好多子任务去执行,只有当所有子任务都执行完成时候,才能执行主任务,这时候,就可以选择障碍器了。障碍器是多线程并发控制的一种手段
CyclicBarrier(int parties)//参与线程的个数
CyclicBarrier(int parties, Runnable barrierAction);//Runnable参数是最后一个到达线程要做的任务
int await();// 线程调用await()表示自己已经到达栅栏
int await(long timeout, TimeUnit unit)
让所有的线程都等待完成后才会继续下一步行动。
把一个任务分配给多个线程同时去执行,最终的结果就然后整合一些就是任务结果。
一个线程到达之后会先被阻塞住,只有到达的线程达到指定数量时才会继续往后执行。
Runnable是最后一个来到阻塞时的线程来进行执行的,也就是说最后一个线程会去执行最后的一个整合任务。
工作原理:主要工作原理,通过构造函数创建一个指定屏障数的屏障类,在各线程中调用await(),调用后当前线程将被阻塞,直到调用的次数到指定屏障数后。所有阻塞的线程将恢复继续执行。
yield
把当前线程从运行态转换成就绪态,让当前线程重新参与CPU的资源竞争。需要注意的是这个方法的调用并不会途径任何的中间状态,直接从运行态转入就绪态。
主要用于解决线程饥饿问题。
join
使当前线程进入阻塞状态,等待指定线程执行完毕或特定时间。
需要注意的是 join 释放的是那个线程对象上的锁。
底层使用 wait 进行实现线程等待。
闭锁 CountDownLatch
CountDownLatch是一个同步工具类,join的增强版。允许一个或多个线程,等待其他一组线程完成操作,再继续执行。底层实现为AQS
public CountDownLatch(int count); 构造函数,初始化计数器值为count,count只能被设置一次
public void await()throws InterruptedException; 调用await()方法的线程会被挂起,直到count值为0才继续执行
public boolean await(longtimeout, TimeUnit unit)throws InterruptedException; 和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public void countDown();将count值减1
它是通过控制计数器的值来达到等待的目的。
当计数器的值>0时,调用countDownLatch.await()会阻塞当前线程,直到其他线程调用countDownLatch.countDown()将计数器的值减到0时,阻塞线程将被唤醒。计数器的值>0时调用await()方法不会阻塞当前线程。
主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。
这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
问:
join和countDownLatch的区别
-
join用于让当前执行线程等待join线程执行结束。其实现原理是不停检查join线程是否存活,如果join线程存活则让当前线程永远wait。
-
countDownLatch没有这个线程,只要count减小到0,不管被等待线程是否执行结束,等待线程都可以继续执行(被唤醒,进入可执行状态)。
yield与join的区别
| yield | join | |
|---|---|---|
| 是否释放锁 | 只释放CPU资源剩下啥都不释放 | 释放当前线程对象锁资源,底层使用的是wait进行阻塞,而与之呼应的同步程序为同步方法,即锁对象为线程对象 |
| 最后去哪里了 | 调用后状态即为可运行态 | 调用后挂在到线程对象的阻塞队列中,等待指定线程被唤醒 |
| 应用场景 | 就是释放一些CPU资源,让其他线程拥有更多的可能去执行,一定程度上避免了线程饥饿问题 | 用于就是我这个线程需要那个线程执行完毕后才能执行,或者那个线程跑多长时间也行 |
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









