







淘宝分析
1 淘宝内衣购买分析
目的:
- 非规则数据如何处理
- 掌握时间处理
- 如何选择维度
- seaborn与pandas操作
2 数据整理
2.1 实际工作中,我们的数据来自哪里
- 更多的根据自己产品采集数据
- 开源数据集
- 第三方数据
2.2 准备工作:
- 下载数据集
- 查看数据集
- 设定整理目标
数据内容:
- 文本文件
- 主要内容:2017-04-20 13: 06 :04,颜色分类:肤色薄款;尺码:38/85C,不错给婆婆买的,准备再买两件
从数据得到信息: - 时间,颜色分类,尺寸,评论
- 数据不规范需要提取
- 目标: 提取时间,类别,尺寸,评论
2.3 将数据整理成DataFrame对象
知识点:
- 文件操作
- 正则
- 列表
实现思路:
- 逐行读取文件
- 使用正则切分数据
- 将数据添加到列表中
- 创建DataFrame对象aFrame对象
提取
目标: 提取时间,类别,尺寸,评论
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import re
path = r'data\cup_all.txt'
f = open(path, encoding='utf-8')
result = []
for line in f:
t = re.sub(r'(颜色分类:)|(尺码:)', '', line.strip())
t = re.split(r'[,;]', t, maxsplit=3)
result.append(t)
df = pd.DataFrame(result, columns=['date', 'colortype','bsize', 'comment'])
df
| date | colortype | bsize | comment | |
|---|---|---|---|---|
| 0 | 2017-04-20 13:06:04 | 肤色薄款 | 38/85C | 不错给婆婆买的,准备再买两件 |
| 1 | 2017-04-23 21:44:20 | H007宝蓝色加粉色 | 34/75B | 和想象的一样好!价格实惠!拢胸效果很好穿着舒服,就是我要的是宝蓝加肤色!给发了一件粉色,也不... |
| 2 | 2017-05-18 10:36:31 | 超薄杯纯洁白 | 80C | 真的不错 |
| 3 | 2017-04-19 20:44:51 | 浅紫 | 36B=80B | 一次买了两件,内衣质量不错,无钢圈设计穿上很舒服也很有型,值得购买。 |
| 4 | 2017-05-07 09:16:47 | 卡其色 | 75A | 因为手机号填错了结果直接被退件了_(:_」∠)_但是卖家还是超好心地给我重新送了回来qwq |
| ... | ... | ... | ... | ... |
| 200762 | 2017-03-13 20:32:45 | 黑色 | 75A | 超级喜欢,蕾丝非常好看,又非常合适舒服,会回购,细肩带超级好看,也不会觉得松,很薄很舒适 |
| 200763 | 2017-05-31 13:51:40 | 拉丝黑色 | 80B=C杯 | 此用户没有填写评论! |
| 200764 | 2017-04-05 15:46:44 | 卡其 | 75A | 布料硬,穿着不舒服,聚拢效果一般,这种布料和聚拢效果配上这价格,不值得购买 |
| 200765 | 2017-05-19 10:19:12 | 全光肤 | 80C=36C | 衣衣穿着刚刚好,也很舒服,比我上次在店里买的一件还舒服,厚度也合适,夏天就喜欢穿薄点的,不然... |
| 200766 | 2017-05-21 21:37:25 | 灰色蕾丝 | 36A/80A | 穿着很舒服 |
200767 rows × 4 columns
3 时间分析
需求:
- 什么时候备货
- 是么时候在线
知识点:
- 对时间进行处理:按照月,日,小时拆分
- 知识点:pandas时间处理,period
3.1 时间处理
- 将date转成DatetimeIndex
- 使用DatetimeIndex将其转换成月,日,小时转换成月,日,小时
#将时间列转DatetimeIndex
dindex = pd.to_datetime(df.date.values)
#设置Period为Day
df['day'] = dindex.to_period('D')
#设置Period为Month
df['month'] = dindex.to_period('M')
#设置为小时
df['hour'] = dindex.strftime('%H')
df.head()
| date | colortype | bsize | comment | day | month | hour | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-04-20 13:06:04 | 肤色薄款 | 38/85C | 不错给婆婆买的,准备再买两件 | 2017-04-20 | 2017-04 | 13 |
| 1 | 2017-04-23 21:44:20 | H007宝蓝色加粉色 | 34/75B | 和想象的一样好!价格实惠!拢胸效果很好穿着舒服,就是我要的是宝蓝加肤色!给发了一件粉色,也不... | 2017-04-23 | 2017-04 | 21 |
| 2 | 2017-05-18 10:36:31 | 超薄杯纯洁白 | 80C | 真的不错 | 2017-05-18 | 2017-05 | 10 |
| 3 | 2017-04-19 20:44:51 | 浅紫 | 36B=80B | 一次买了两件,内衣质量不错,无钢圈设计穿上很舒服也很有型,值得购买。 | 2017-04-19 | 2017-04 | 20 |
| 4 | 2017-05-07 09:16:47 | 卡其色 | 75A | 因为手机号填错了结果直接被退件了_(:_」∠)_但是卖家还是超好心地给我重新送了回来qwq | 2017-05-07 | 2017-05 | 09 |
3.2 时间统计
按照月进行统计
#sns设置,字体1.2倍
sns.set(font_scale=1.2)
#支持中文
sns.set_style({"font.sans-serif":['simhei','Droid Sans Fallback']})
#画布大小
plt.figure(figsize=(10,4))
#时间排序
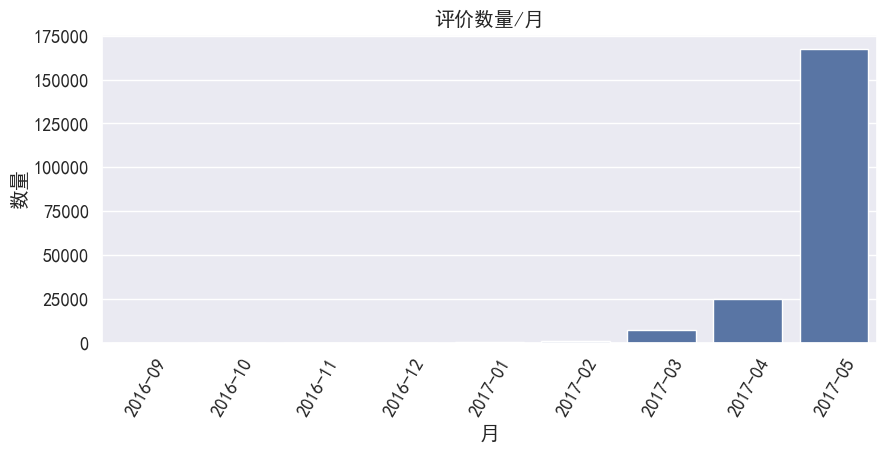
morder = sorted(df.month.unique())
#使用countplot进行统计,并按时间排序
ax = sns.countplot(x= df.month, order=morder)
#设置x轴标签旋转60度
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=60)
ax.set_title('评价数量/月')
ax.set_ylabel('数量')
ax.set_xlabel('月')
UserWarning: FixedFormatter should only be used together with FixedLocator
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=60)
Text(0.5, 0, '月')
按照小时排序
df.hour
0 13
1 21
2 10
3 20
4 09
..
200762 20
200763 13
200764 15
200765 10
200766 21
Name: hour, Length: 200767, dtype: object
#通过评论信息,查看用户在线时间
# 先对数据按 'hour' 列进行排序
df = df.sort_values('hour')
# 绘图
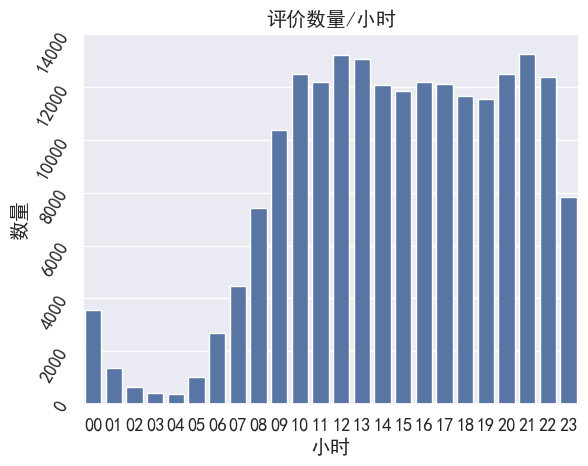
ax = sns.countplot(x=df.hour, orient='h')
# 先获取刻度位置
yticks = ax.get_yticks() # 将xticks改为yticks
# 再设置刻度位置
ax.set_yticks(yticks) # 将xticks改为yticks
#设置y轴标签旋转60度
_ = ax.set_yticklabels(ax.get_yticklabels(), rotation=60) # 将xticklabels改为yticklabels
ax.set_title('评价数量/小时')
ax.set_ylabel('数量')
ax.set_xlabel('小时')
Text(0.5, 0, '小时')
3.3 总结
- 通过月评价数量:在3月开始备货,到了45月是换机季节,多准备货源
- 通过小时评价量:用户在8点开始,就开始大量上线,一直到晚上11点,客流下降
4 用户属性分析
目的:
- 备货准备:尺寸,颜色,类型
知识点:
- pandas中的str方法与正则表达式
4.1 尺寸
- 查看数据:
- 根据ABCD简单获取尺寸
df.head()
| date | colortype | bsize | comment | day | month | hour | |
|---|---|---|---|---|---|---|---|
| 17352 | 2017-05-11 00:33:11 | 肤色-无钢圈 | 70A | 收到宝贝了,大小刚刚好,颜色又很漂亮,穿起来很聚拢!大爱呀 | 2017-05-11 | 2017-05 | 00 |
| 47791 | 2017-05-17 00:52:10 | 浅紫色+肤色 | 80C | 四个颜色都挺正,好评 | 2017-05-17 | 2017-05 | 00 |
| 54774 | 2017-05-28 00:22:24 | 肤色 | 70A=A杯 | 好棒!感觉比我买的三百多的都好;实话;很舒服! | 2017-05-28 | 2017-05 | 00 |
| 135326 | 2017-05-28 00:01:04 | 灰蓝色 | 80B | 内衣收到后还不错,就是有味儿 | 2017-05-28 | 2017-05 | 00 |
| 117839 | 2017-05-22 00:51:52 | 1991黑色套装 | 34/75B(厚杯) | 一般般 | 2017-05-22 | 2017-05 | 00 |
- 解决方式:使用正则去获取ABCD
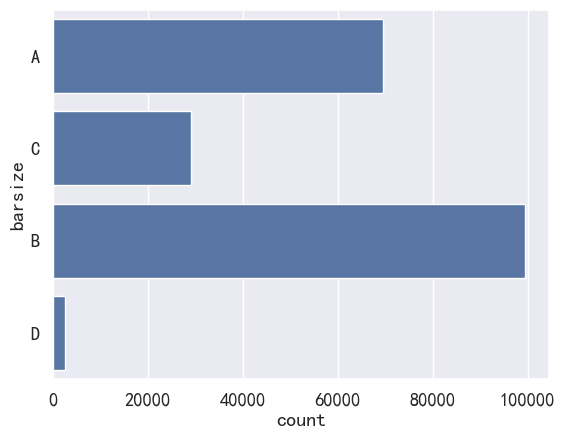
df['barsize'] = df['bsize'].str.extract(r'([ABCD])')
_ = sns.countplot(df['barsize'])
ax.set_title('大小')
ax.set_ylabel('数量')
ax.set_xlabel('size')
Text(0.5, 28.25, 'size')
4.2 类型
类型:颜色,材质等,因为信息混到一起,我们不在做拆分
- 统计各个类型数量数量
type_count = df.colortype.value_counts()
type_count
colortype
肤色 22922
黑色 18535
卡其色 3569
粉色 3200
白色 3152
...
油光款灰蓝色 1
拉丝-杏色薄款 1
亚光-红色 1
111肤色套装 1
999酒红 1
Name: count, Length: 669, dtype: int64
- 结果:几百个类型,没办法可视化?
- 过滤销量小于1000的
type_count =type_count[type_count>1000]
type_count
colortype
肤色 22922
黑色 18535
卡其色 3569
粉色 3200
白色 3152
黑色+肤色(两件装) 2701
贵族黑 2656
肤色薄款 2459
轻肤 2189
灰色 2143
蓝色 1971
肤颜色 1948
558#黑色 1693
肤嫩色 1668
肤色-无钢圈 1663
卡其 1653
全光肤 1642
贵族黑(绑带款) 1622
肤粉色(绑带款) 1543
薄杯肤色 1540
LB1029黑色 1415
558#肤色 1269
灰蓝色 1257
黑色薄款 1254
藕荷色 1230
110|肤色 1226
肤色无钢圈薄杯 1214
藏青 1211
轻粉 1185
酒红 1144
肤色单件 1097
灰色蕾丝 1096
光面肤无钢圈 1089
咖啡色-无钢圈 1080
肤色套装 1069
纪念粉 1061
浅蓝纯色 1043
薄款黑色 1021
Name: count, dtype: int64
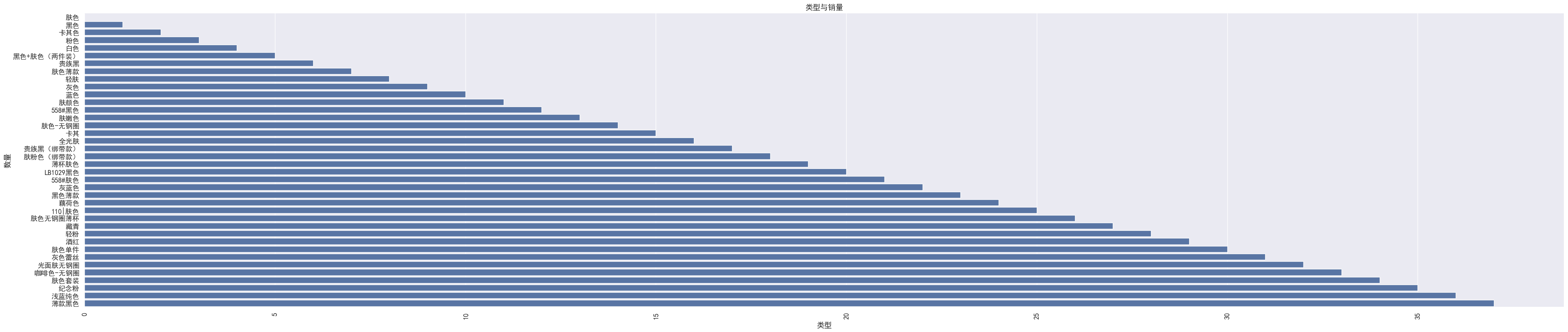
tcount = type_count.reset_index()
plt.figure(figsize=(50,10))
ax = sns.barplot(x= tcount.index, y='colortype', data=tcount)
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
ax.set_title('类型与销量')
ax.set_ylabel('数量')
ax.set_xlabel('类型')
UserWarning: FixedFormatter should only be used together with FixedLocator
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
Text(0.5, 0, '类型')
4.3 总结
- 根据大小,备货尽量选择AB,然后准备C,稍微准备点D
- 根据类型,我们可以选择大家喜欢的选择颜色,进行备货
扩展:
- 对类型与颜色再次提取,提取出更多颜色
- 对品论信息进行分类,但是品论没有对应的商品,所以无法确认商品好坏商品好坏



















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











