







阅读笔记 DAGA 低资源标记任务数据扩充方法
文章目录
题目: DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
代码:github
前言
本文旨在记录学习所得所感,如有错漏敬请斧正
概述
数据增强技术已被广泛用于提高机器学习性能,因为它们增强了模型的泛化能力。在这项工作中,为了为低资源标记任务生成高质量的合成数据,作者提出了一种新的增强方法,该方法使用在线性化标记语句上训练的语言模型。
Introduction
与图像和语音不同,旋转、裁剪、遮盖等人工转换规则很难推广到语言的原始数据中。因为简单的失真通常不会改变图像所包含的视觉信息的含义,但是删除或替换一个单词可能会使句子的含义完全改变。
在自然语言处理领域已经有了不少已经取得较好效果的数据增强方法,如back translation等,但是对于*sequence tagging(分词、词性标注、命名实体识别等)*任务,其相对一般的下游任务(翻译、分类等)而言对数据增强产生的噪声要更为敏感。目前常见的的sequence tagging数据增强方法有使用弱标记器注释未标记的数据、利用对齐的双语语料库诱导注释和同义词替换等方法。而这三种方法都有自己的局限性:弱标记数据将不可避免地引入更多噪声;双语语料库需要额外资源,同义词替换依赖于额外知识,这二者皆不适用于低资源语言。
本文研究了使用生成方法的序列标记任务的数据库扩充,主要方法为:
- 首先将标记语句线性化
- 在线性化的数据上训练语言模型
- 使用语言模型生成
这个方法的特点是统一了句子生成和语言模型标记的过程,而且不需要像WordNet这样的额外资源,同时也可以借助条件生成技术对未标记数据或者知识库等资源进行利用。
Background
1、NER
NER(Name Entity Recognition)命名实体识别是信息提取的重要任务,主要作用是将文本中的命名实体定位并分类为预定义类型。这个任务有两个主要难点:其一是NER的手动标记训练数据量有限,其二则是由于可以被命名的单词种类有限,从小样本的训练数据中很难概括出单词种类。
2、Part-of-Speech (POS) Tagging
Part-of-Speech (POS) Tagging词性标注主要作用为给给定句子中的每个单词分配一个语法类的标记,是促进句法分析和观点分析等下游任务的基础。但目前的词性标记器的问题之一是:在低资源语言和稀有单词上,其准确度会显著下降。
3、Target Based Sentiment Analysis
Target Based Sentiment Analysis基于目标的情感分析旨在检测句子中的观点目标并预测目标上的情感极性
Proposed Method
1、Labeled Sentence Linearization
首先执行句子线性化,将标记的句子转换为便于语言模型学习单词和标签分布的线性序列。为使语言模型学习到单词和标签的关系,如下图所示,将标签插入到相应单词之前,将标签视为单词的修饰词。

对于具有大量O标记的任务(如NER、E2E-TBSA等),将标记从线性化序列中移除,同时在句子线性化之后,在句子的开头结尾添加特殊标记**[BOS]和[EOS]**以标记句子边界,促进模型训练和数据生成。
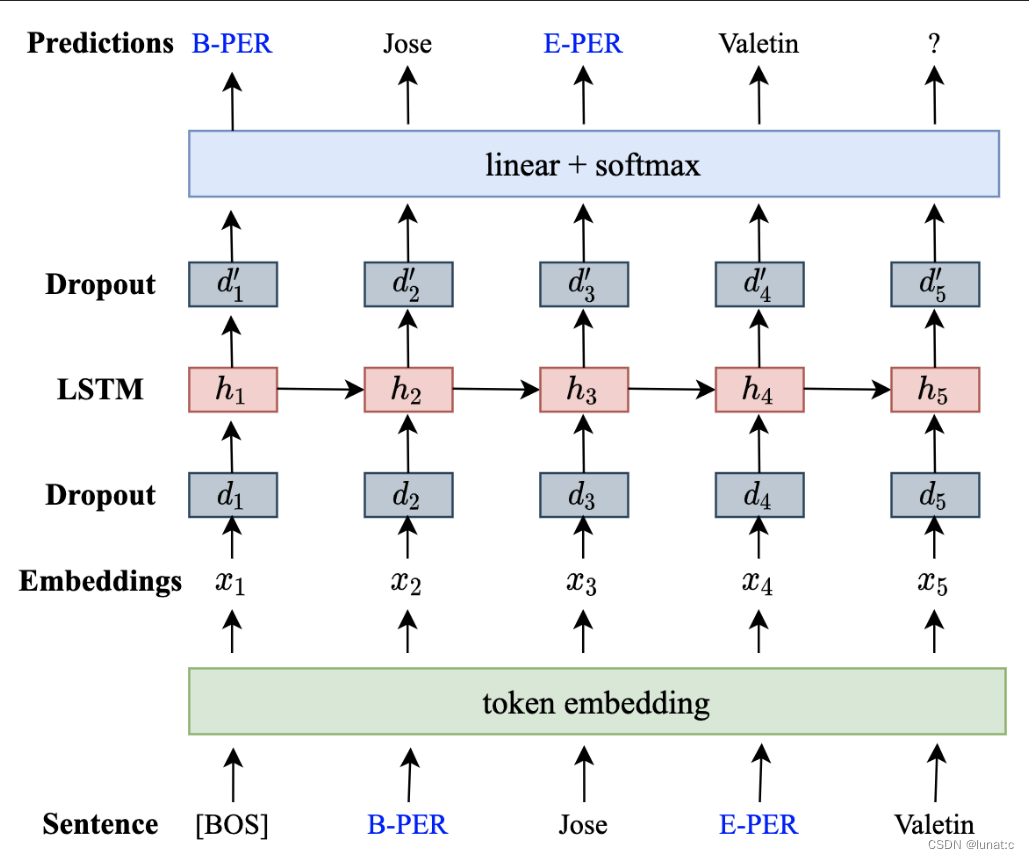
2、Language Modeling and Data Generation
在线性化之后,使用语言模型来学习单词和标记的分布。这里采用的是一个单层LSTM递归神经网络语言模型(RNNLM)。如下图所示,对于线性化后的标记序列,首先进行标记嵌入,然后将嵌入后的结果输入dropout层,这里的目的是随机去掉一些标记的特征,防止模型过拟合;然后将dropout层的输出输入LSTM中以产生隐藏状态,然后输入dropout层,最后进行多分类。
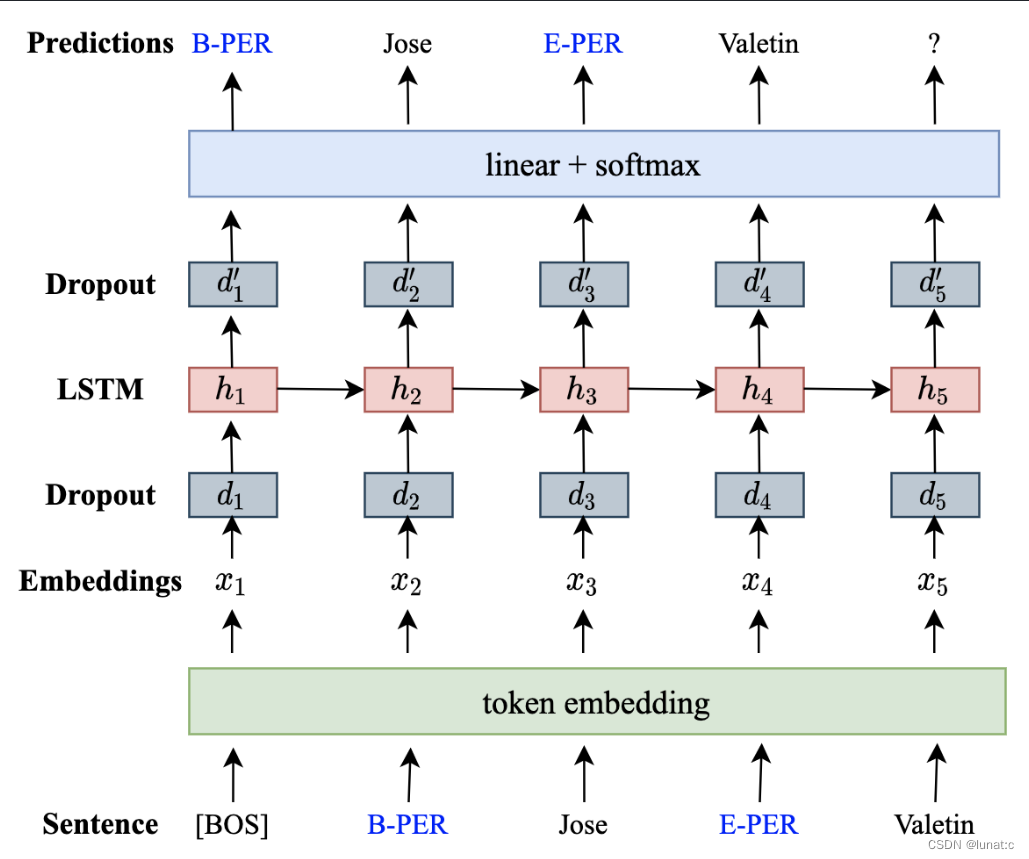
在训练完成后,可以用其生成用于标记任务的训练数据,首先将 [BOS] 输入网络,生成下一个最高概率的标记,该标记又被作为输入生成下一个标记。由于我们在相应的单词前插入了标签,所以当预测给定的句子 “我预订了飞往” 的下一个标记时, “S-LOC”的概率比其他选项要大得多 ,因为语言模型在前面的学习中学到了大量这样的例子,而在预测更下一个词时,因为 所有的 “S-LOC” 后都是位置词,因此*“伦敦”、“巴黎”、“东京”*都是可能的选择,它们之间的概率非常相近,由于增加了随机性,所以模型会选择其中的任意一个。
3、Post-Processing
生成的序列为线性格式,所以需要转换成原格式。同时,使用一些简单规则来清理生成的数据:
- 删除没有标签的句子
- 删除所有单词都是[unk]的句子
- 删除标签前缀顺寻不正确的句子
- 删除单词序列相同但标签不同的句子
4、Conditional Generation
提出条件生成方法,允许模型在低资源场景下使用未标记的数据或者知识库。在每个序列的开头加上**[labelled]、[unlabeled]、[KB]**条件标签之一,以标记它们的起源,其中KB表示通过将知识库与未标记的数据匹配来标记序列,这个方法使得语言模型可以学习这些数据间的共享信息。
而当实际生成数据时,在序列开头加上[labeled]















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









