







突然接到了老师的任务需要公交站点数据画图,结果找了半天都没找数据,索性就自己爬取吧。
查网上的资料发现主要分为两个部分:
- 首先获取站点信息
- 根据地图匹配站点信息
知道了这些就开始吧!
1.首先是获取所有站点的信息
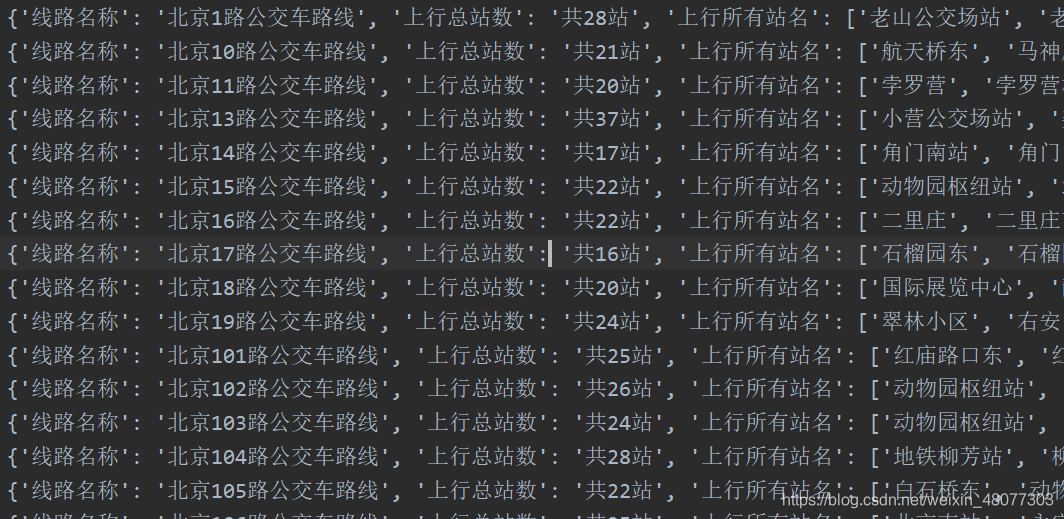
我们主要从这里: 车站信息.获取车站信息。我这里获取的是上行车辆信息。但代码中还包含下行车辆的代码。
import requests
from lxml import etree
import pandas as pd
# 列表用来保存所有公交信息
items = []
data22=pd.DataFrame(columns=["1","2"])
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
# 导航页爬取(以1,2,3·······开头)
def parse_navigation():
url = 'https://beijing.8684.cn/'
r = requests.get(url, headers=headers)
# 解析内容,获取所有的导航链接
tree = etree.HTML(r.text)
# 查找以数字开头的所有链接
number_href_list = tree.xpath('//div[@class="bus-layer depth w120"]/div[1]/div/a/@href')
# 查找以字母开头的所有链接
char_href_list = tree.xpath('//div[@class="bus-layer depth w120"]/div[2]/div/a/@href')
# 以列表形式返回所有链接
print(number_href_list + char_href_list)
return number_href_list + char_href_list
def parse_second_route(content):
tree = etree.HTML(content)
# 写xpath,获取每一个线路
route_list = tree.xpath('//div[@class="list clearfix"]/a/@href')
print("routlist",route_list)
route_name = tree.xpath('//div[@class="list clearfix"]/a/text()')
print("routname",route_name)
i = 0
# 遍历上边的列表
for route in route_list:
print('开始爬取%s线路······' % route_name[i])
route = 'https://beijing.8684.cn'+route
r = requests.get(url=route,headers=headers)
#print(1111)
# 解析内容,获取每一路公交车的详细信息
parse_third_route(r.text)
print('结束爬取%s线路······' % route_name[i])
i += 1
def parse_third_route(content):
tree = etree.HTML(content)
# -------------------依次获取内容--------------------
# 获取公交信息
bus_number = tree.xpath('//div[@class="info"]/h1/text()')[0]
#print("111111",bus_number)
# 获取运行时间
#run_time = tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0]
# 获取票价信息
#ticket_info = tree.xpath('//ul[@class="bus-desc"]/li[2]/text()')[0]
# 获取更新时间
#laster_time = tree.xpath('//ul[@class="bus-desc"]/li[4]/text()')[0]
#py=tree.xpath('/html/body/div[7]/div[1]/div[6]/@class')
# / html / body / div[7] / div[1] / div[6] / div[1]
# / html / body / div[7] / div[1] / div[6]
# / html / body / div[7] / div[1] / div[5]
#print("py",py)
#if 1 :#tree.xpath('/html/body/div[7]/div[1]/div[6]/@class')[0] == 'bus-excerpt mb15':
# 获取上行总站数
up_total = tree.xpath('/html/body/div[7]/div[1]/div[@class="bus-excerpt mb15"]/div[2]/div[2]/text()')[0]
#print("22222", up_total)
# 获取上行所有站名
up_route = tree.xpath('/html/body/div[7]/div[1]/div[@class="bus-lzlist mb15"]/ol/li/a/text()')
#print("33333", up_route)
# try:
# # 获取下行总站数
# down_total = tree.xpath('//div[@class="layout-left"]/div[7]/div/div[@class="total"]/text()')[0]
# # 获取下行所有站名
# down_route = tree.xpath('//div[@class="layout-left"]/div[8]/ol/li/a/text()')
# except Exception as e:
# down_total = ''
# down_route = ''
# else:
# up_total = tree.xpath('/html/body/div[7]/div[1]/div[6]/div[2]/div[2]/text()')[0]
# up_route = tree.xpath('/html/body/div[7]/div[1]/div[7]/ol/li/a/text()')
# try:
# down_total = tree.xpath('//div[@class="layout-left"]/div[6]/div/div[@class="total"]/text()')[0]
# down_route = tree.xpath('//div[@class="layout-left"]/div[7]/ol/li/a/text()')
# except Exception as e:
# down_total = ''
# down_route = ''
# 将每一条公交信息存放到字典中
# item = {
# '线路名称': bus_number,
# '运行时间': run_time,
# '票价信息': ticket_info,
# '更新时间': laster_time,
# '上行总站数': up_total,
# '上行所有站名': up_route,
# '下行总站数': down_total,
# '下行所有站名': down_route
# }
item = {
'线路名称': bus_number,
'上行总站数': up_total,
'上行所有站名': up_route,
}
#data22.append(up_route)
items.append(item)
def parse_second(navi_list):
# 遍历上面的列表,依次发送请求,解析内容,获取每个页面所有的公交路线url
for first_url in navi_list:
first_url = 'https://beijing.8684.cn' + first_url
print('开始爬取%s所有的公交信息' % first_url)
r = requests.get(url=first_url, headers=headers)
# 解析内容,获取每一路公交的详细url
parse_second_route(r.text)
# 爬取完毕
fp = open('北京公交.txt', 'w', encoding='utf8')
for item in items:
fp.write(str(item) + '\n')
fp.close()
def main():
# 爬取第一页所有的导航链接
navi_list = parse_navigation()
# 爬取二级页面,需要找到以1开头的所有公交路线
parse_second(navi_list)
if __name__ == '__main__':
main()
结果如图:
2.获取地点的经纬度
我这里采用的高德地图的WEB服务开发者的KEY,主要思想就是把爬取的数据转化为list类型然后逐个匹配经纬度。会有 问题的部分是可能会查不到地点的经纬度,这就需要我们设置默认值(0,0)
import requests
import pandas as pd
data=pd.read_csv("df3.csv")
print(data.iloc[:,2])
list2=data.iloc[:,2].tolist()
print(list2)
print(type(list2))
list1=[]
url = 'https://restapi.amap.com/v3/geocode/geo?parameters'
proxy={'http':'http://117.88.176.38'}
print(len(list2))
for i in range(len(list2)):
# print(list2[1])
# print(list[1])
params = {
"city":"北京",
"key":"自己的key",
'address':list2[i],
'out':'JSON'
} # 输出结果设置为json格式
res = requests.get(url,params)
#print(res.text)
res2=eval(res.text)
if res2["geocodes"]!=[]:
res3=res2["geocodes"][0]
#print(res3)
print("第",i, "经纬度为--------", res3["location"])
list1.append(res3["location"])
# list1.append(res3["location"])
else:
res3="0,0"
print("第", i, "经纬度为--------", "00000000000000000000000000000")
list1.append(res3)
data3=pd.DataFrame(list1)
data3.to_csv("fiall_data.csv")
3.其实最主要的是数据处理的部分
我们获取的是字典类型的数据,如何转化为列表List
3.1取出站点信息
import pandas as pd
import random
data=pd.read_csv('北京公交2.txt',header=None,sep="/t",encoding="utf-8")
print(len(data))
list1=[]
for i in range(len(data)):
df=eval(data.loc[i][0])
for x in df['上行所有站名']:
list1.append(x)
df2=pd.DataFrame(list1)
df2=df2.drop_duplicates(keep='first')
print(df2.head(10))
df2.to_csv("df2.csv")
print(len(df2))
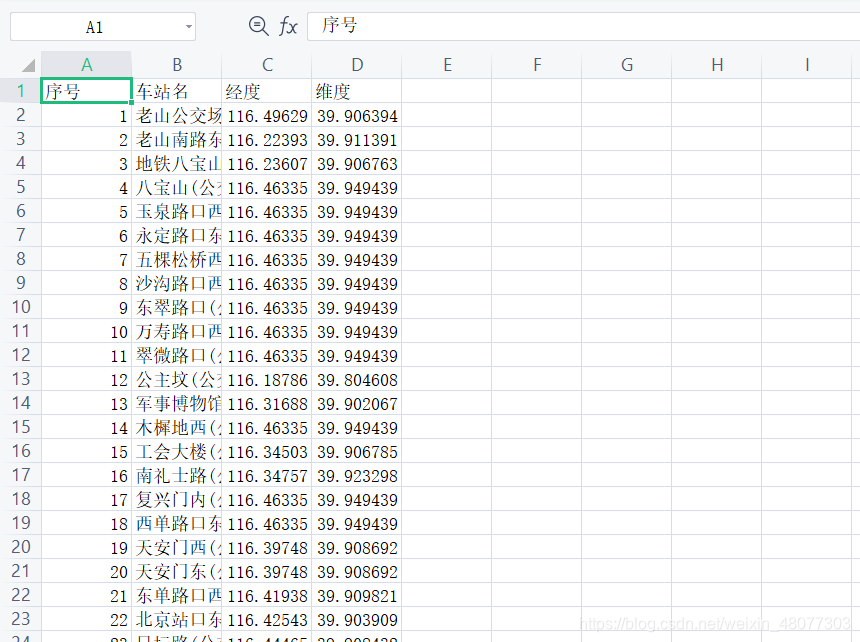
3.2将爬取的经纬度和地点匹配
import pandas as pd
data1=pd.read_csv("df3.csv")
data2=pd.read_csv("fiall_data.csv")
a=data1.iloc[:,2]
b=data2.iloc[:,1]
data3=pd.DataFrame(columns=["chezhan","jingdu"])
data3["chezhan"]=a
data3["jingdu"]=b
print(data3.head())
data3.to_csv("data3.csv")
运行完所有就可以获取到所有站点的经纬度信息,就可以在GIS中画图了。


















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











