







 这篇博客介绍了一个使用Python自动化加密多个PDF文件的方法。通过PyPDF2库,脚本首先获取指定文件夹内所有PDF文件的路径,然后逐个读取、加密并保存为新文件,加密密码可自定义。这样可以极大地提高工作效率,保护PDF内容的安全。
这篇博客介绍了一个使用Python自动化加密多个PDF文件的方法。通过PyPDF2库,脚本首先获取指定文件夹内所有PDF文件的路径,然后逐个读取、加密并保存为新文件,加密密码可自定义。这样可以极大地提高工作效率,保护PDF内容的安全。
每个人都有秘密,每个公司也是。如果我们生成了很多PDF,一个一个地加密,将费时费力。这种重复的繁重的事儿交给Python,
import PyPDF2 #可从PDF文档提取信息
import os #用于获取需要合并的PDF文件所在路径
path="data/" # 文件夹路径
#1.获取需要加密的文件名及路径
files=[]
for file in os.listdir(path):
if file.endswith(".pdf"): #排除文件夹内的其它干扰文件,只获取PDF文件
files.append(path+file)
files以上可以获取我们需要加密的PDF文件所在路径及文件名
#2.获取每个PDF文件并加密保存
for file in files:
pdf_obj=open(file,'rb')# 以二进制读取,将保留PDF中的所有信息
pdf_reader=PyPDF2.PdfFileReader(pdf_obj,strict=False)
pdf_writer=PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
page_obj=pdf_reader.getPage(page_num)
pdf_writer.addPage(page_obj)
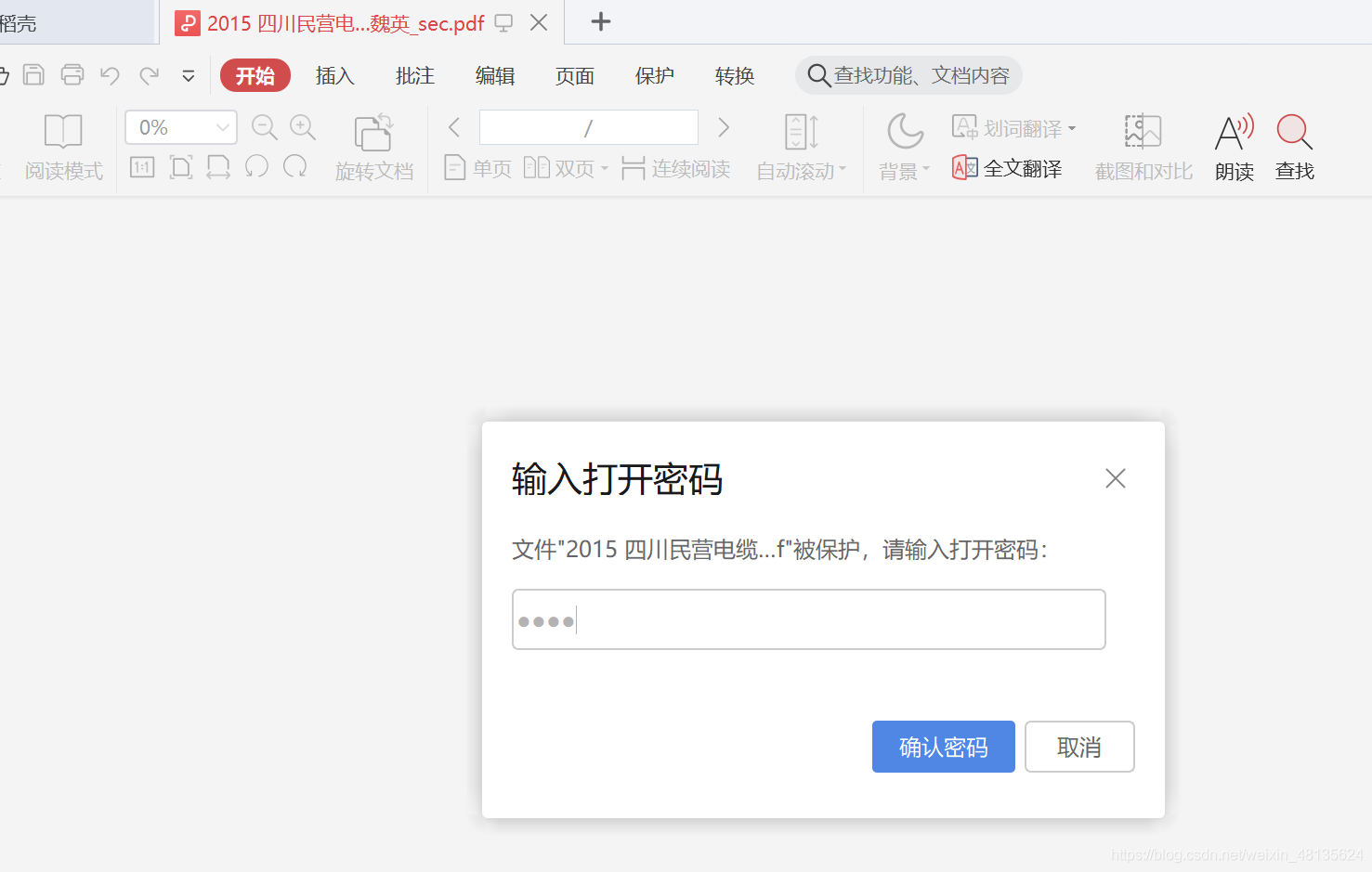
pdf_writer.encrypt('pass')# 加密,密码设为'pass',可个性化调整
#写入并保存PDF文件
pdf_output_file=open(file.split(".")[0]+"_sec.pdf",'wb') #以二进制写入,将保留源PDF中的所有信息
pdf_writer.write(pdf_output_file)
pdf_output_file.close()
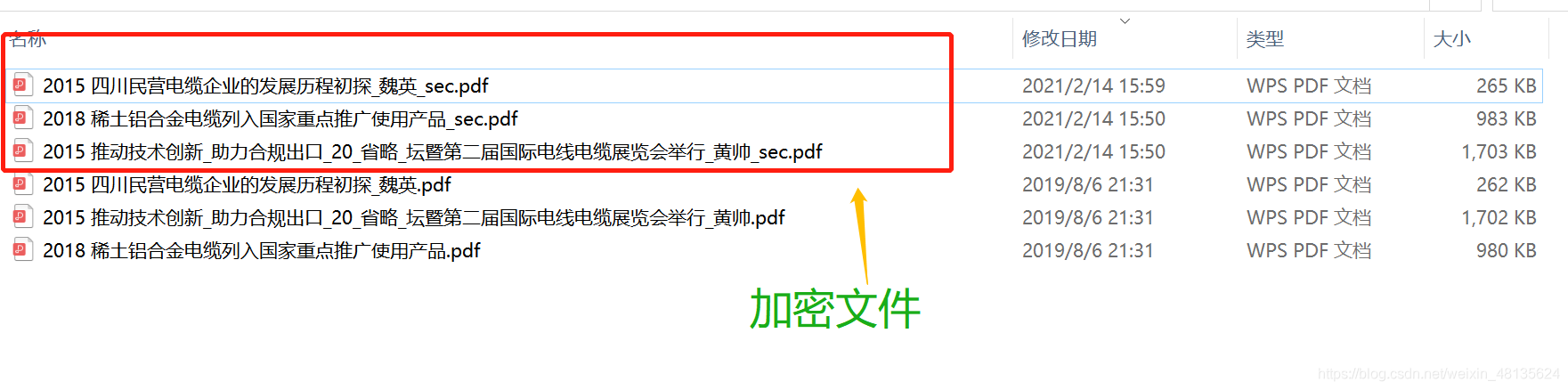
为避免源文件出问题,此处我们保存为新的文件,命名方式为在源文件名后加上“_sec”。


















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











