







起因:
学校每月免费流量120G,然而月底最后一天了才用了70G,于是就琢磨着怎么把剩下的50G花光。然后想起之前一个视频博主的影视解析很不错,于是萌生了把这个博主的所有视频爬取下来的想法,在这里把爬取方案做个记录和分享。
题外话:之所以选择西瓜视频而不是其他的视频平台,是该博主对《楚门的世界》的电影解析只在西瓜视频上没有被删减,前文所述个人认为很不错的影视解析是《Silo》的,推荐大家可以去看看这部剧,真的还蛮不错的。
方案:

- 访问博主主页
- 获取其所有视频的链接
- 获取其各个视频的真实地址
- 下载视频
具体实现流程:
- 访问博主主页
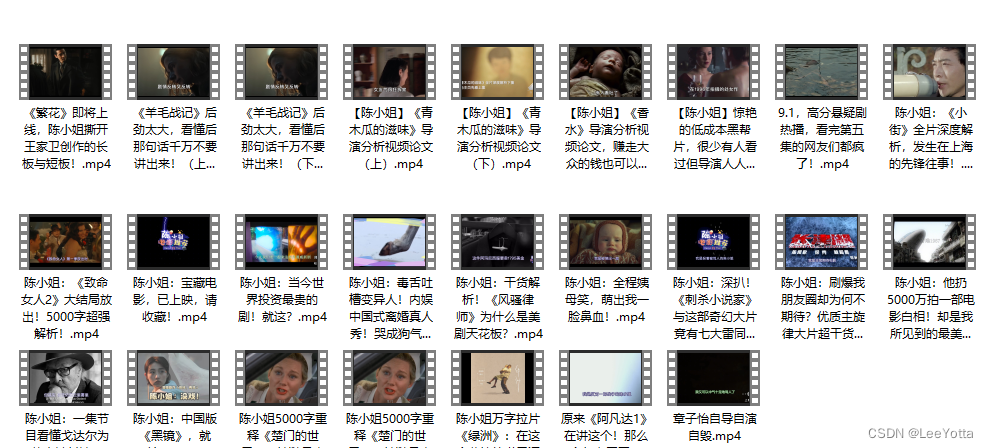
这一步没啥好讲的,找到你想爬取的视频博主的个人主页,界面大致如下:
- 获取其所有视频的链接
这里的链接指的是视频的短链接,也就是平时分享视频的链接地址,格式就像这样:
https://www.ixigua.com/7266702277002723879那么怎么在个人主页获取其所有视频的短链接呢? 我这里的方案是在检查页面元素后发现短链接的地址存在于class="HorizontalFeedCard__title color-link-content-primary" 的<a>元素中。
具体实现我是在浏览器的控制台上用JavaScript代码实现的,同时我也获取了<a>元素的textContent用于下载视频的命名:
function getAllAHrefAndText(selector) {
// 查找所有符合选择器条件的<a>元素
var elements = document.querySelectorAll(selector);
// 创建空数组来存储href属性内容和文本内容
var hrefArray = [];
var textArray = [];
// 遍历并将每个元素的href属性值和文本内容添加到数组中
for (var i = 0; i < elements.length; i++) {
var element = elements[i];
var href = element.getAttribute('href');
// 将href属性前面拼接字符串"https://www.ixigua.com"
if (href) {
var fullHref = "https://www.ixigua.com" + href;
hrefArray.push(fullHref);
}
textArray.push(element.textContent);
}
// 返回包含href属性内容和文本内容的对象
return {
href: hrefArray,
text: textArray
};
}
// 调用函数并传入选择器作为参数
var result = getAllAHrefAndText('a.HorizontalFeedCard__title.color-link-content-primary');
// 打印结果
console.log("链接内容:", result.href);
console.log("文本内容:", result.text);得到的结果如下图:

刚好JavaScript的Array和python的List格式是一样的,复制之后贴到python里就行:

- 获取其各个视频的真实地址
由于西瓜视频使用了音视频分离,所以需要在短链接的界面打开控制台输入下面的JavaScript命令分别获取各个视频的真实视频及音频地址:
// 视频地址
window.atob(window._SSR_HYDRATED_DATA.anyVideo.gidInformation.packerData.video.videoResource.dash_120fps.dynamic_video.dynamic_video_list.pop().main_url); //
// 音频地址
window.atob(window._SSR_HYDRATED_DATA.anyVideo.gidInformation.packerData.video.videoResource.dash_120fps.dynamic_video.dynamic_audio_list.pop().main_url);这段JavaScript代码简单解释一下就是获取main_url的字符串数据(base64 编码)并将其解码为原始数据。
那么接下来就是如何用python模拟在浏览器访问视频地址,并打开控制台执行上述两条命令以获取音视频的真实地址了,我使用了python的selenium库,具体代码如下:
def spider(url):
# 创建一个Chrome浏览器实例,并使其防止被检测“Chrome正受到自动测试软件的控制”
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 打开网页
driver.get(url)
# 待优化部分,理论上可以有更好的等待机制,我这里偷懒直接等待10s
time.sleep(10)
# 执行JavaScript代码并获取视频URL
js_code_video = 'return window.atob(window._SSR_HYDRATED_DATA.anyVideo.gidInformation.packerData.video.videoResource.dash_120fps.dynamic_video.dynamic_video_list.pop().main_url);'
video_url = driver.execute_script(js_code_video)
js_code_audio = 'return window.atob(window._SSR_HYDRATED_DATA.anyVideo.gidInformation.packerData.video.videoResource.dash_120fps.dynamic_video.dynamic_audio_list.pop().main_url);'
audio_url = driver.execute_script(js_code_audio)
# 打印视频URL
# print(video_url)
# print(audio_url)
# 关闭浏览器
driver.quit()
return str(video_url), str(audio_url)
- 下载视频
这里其实应该有很多种实现,毕竟音视频地址都拿到了,这里分享一下我的方案,我采用的是FFmpeg,原理如下:
ffmpeg -i video.mp4 -i audio.mp3 -c:v copy -c:a aac -strict experimental output.mp4只需将video.mp4的部分换成视频地址,audio.mp3的地方换成音频地址,output.mp4换成你想保存的路径就行。
有关FFmpeg的下载和基本使用可以看我之前的博客,有相关的分享。
这里的具体实现用python的os库执行控制台命令,具体代码如下:
for i in range(len(urls)):
video_url, audio_url = spider(urls[i])
print("url: ", i, " has gotten.")
# 这里写的很丑陋,应该有更好的写法,但我这里也能用就没多管
cmd = 'ffmpeg -i "' + video_url + '" -i "' + audio_url + '" -c:v copy -c:a aac -strict experimental ' + 'E:/' + titles[i] + '.mp4'
# print(cmd)
os.system(cmd)
print("done.")结果:
成功爬取!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











