







1、spark是什么?
Spark是一个基于内存的并行计算框架(类似于hadoop中mr,但是并不能取代hadoop,因为存储和资源调度依然要依赖hadoop)
Hadoop组件:
Hdfs:并行存储框架
Mapreduce:基于磁盘的并行计算框架
Yarn:资源调度器
2、spark组件
SparkCore、SparkSql、SparkStreaming、SparkMllib、SparkGraphX
3、spark比haodoop快
基于内存:spark比hadoop快100倍以上
基于磁盘:spark比hadoop快10倍以上
4、spark为什么比hadoop快?
1、spark将中间运算结果保存在内存中,而hadoop保存在磁盘中
2、Spark运行任务开启的是线程,而hadoop开启的是进程
5、spark集群搭建种类
Standalone集群
Standalone-HA集群
Yarn集群(on cluster模式,on client模式)
6、spark集群角色分布
主节点:master 从节点:work
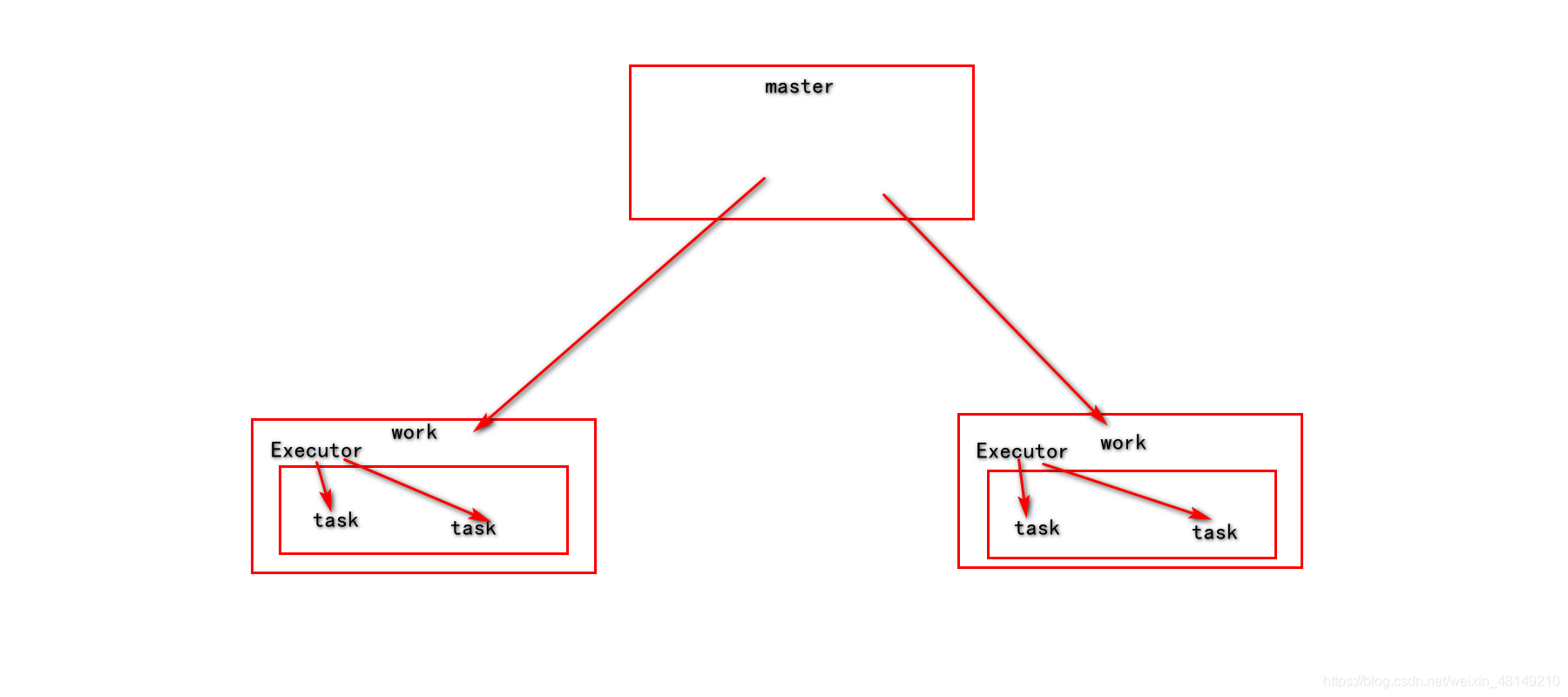
主节点master,从节点worker
由Executor进程开启 task线程执行任务。
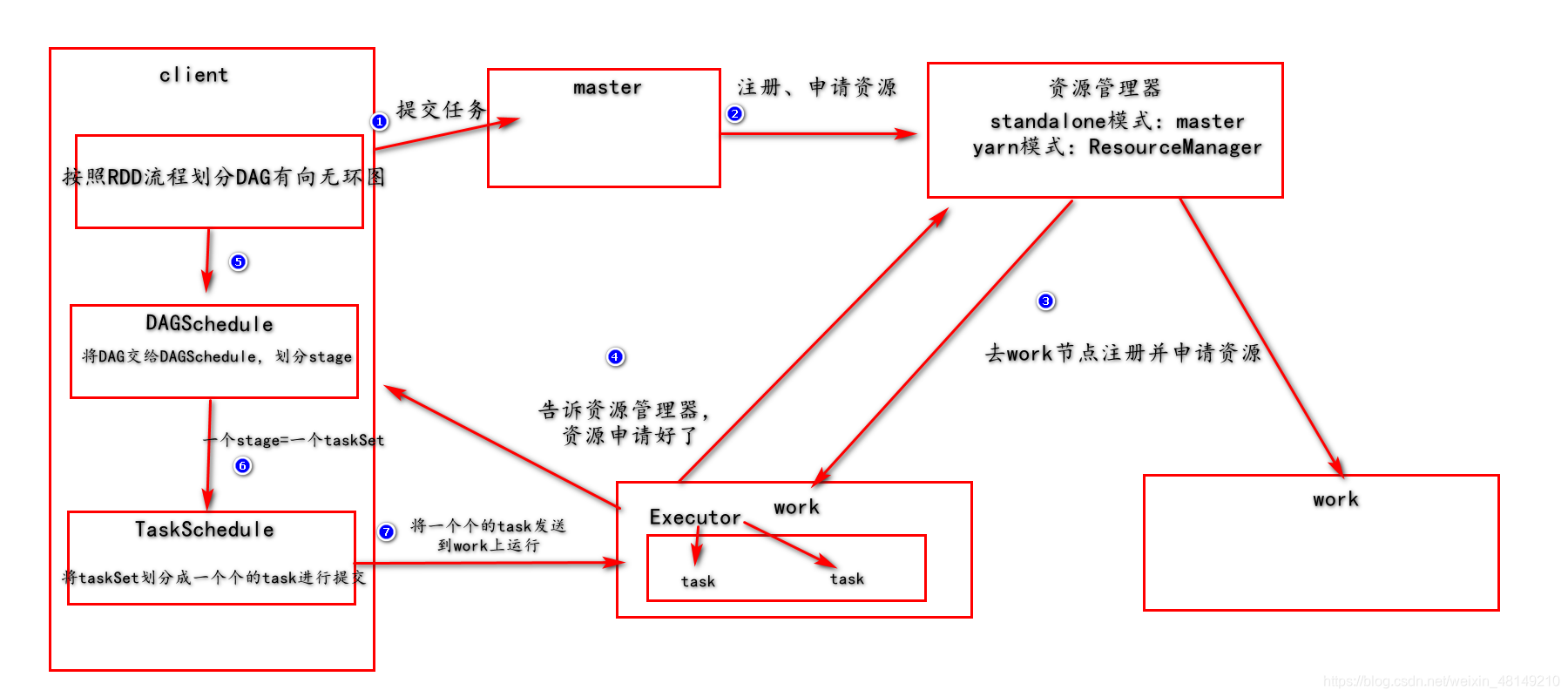
spark运行流程:
7、core和线程
执行任务开起的是线程,线程决定着并行度,而线程就是机器的core
8、spark相关术语
DAG:有向无环图
一个DAG=一个Job
一个DAG可以划分多个Stage
一个Stage=一个TaskSet
一个TaskSet=多个task
一个Core=一个线程
一个线程执行一个task
9、spark-shell和spark-submit命令的区别
Spark-shell:会给我们初始化好spark程序入口,可以直接通过写代码运行,适用于学习、测试使用。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可 sparksession 是sparksql
scala> sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.collect
spark-shell
启动spark-shell注意事项
启动spark-shell默认情况是本地模式,local[]
Local[N]:N是一个具体的数字,指的事启动几个线程
local[*]:指的事使用机器最多的cores去运行任务
- 默认读取hdfs,读取本地加file://
- Spark-submit:提交jar包运行使用,适用于开发使用。
- Hdfs上的文件时共享的,每一台worker节点都能找到,但是本地文件不是共享的,读取本地文件时,需要每台节点相同的目录下都有相同的文件!
10、yarn的两种模式
Client:用于测试使用,driver运行在client端
Cluster:用于开发使用,driver运行在集群上。
11、进入公司运行任务
1、找组长要服务器的测试环境(服务器在你看来一切正常,但是你提交任务把数据搞混乱了,找组长,让他恢复环境。)
2、在测试环境下运行成功
3、再找组长要开发环境。
12、RDD是什么?它有什么特点?它是否可以携带数据
RDD:弹性分布式数据集
特点:不可变、可分区、可并行计算的集合
是否可以携带数据:不可以携带数据,相当于java当中的接口
13、RDD分区数
默认分区数是2个,可以通过设定设定分区数
14、RDD的算子
RDD算子分为两类:一类是转换算子(Transformations),一类是执行算子(Action)
15、区分算子
转换算子:返回值是RDD的就是转换算子
执行算子:返回值不是RDD的就是执行算子
转换算子是懒执行,不会运算,只做连接,当遇到执行算子的时候会带动所有转换算子参与运算。
16、cache和persist、checkpoint
缓存,持久化:cache、persist
检查点:checkpoint
Cache=persist(),默认是将数据只缓存到内存中
在工作当中,使用的是Memory_And_Disk
17、缓存、持久化的缺点
将数据缓存到内存中,容易丢失,缓存到磁盘中,磁盘容易损坏,为了解决这个问题,出现了checkpoint
18、检查点checkpoint的优势
1、切断了RDD依赖链的关系
2、将数据持久化到更安全的地方
19、DAG有向无环图
DAG就是RDD的运算流程
有方向无闭环
20、Stage划分
按照RDD流程划分DAG有向无环图,划分好后,采用回溯方法,从后向前,遇到窄依赖包含到当前stage中,遇到宽依赖,断开,形成一个stage。
21、lineage(血统)
22、宽窄依赖
窄依赖:父Rdd的一个分区被子Rdd的一个分区所依赖。“独生”
宽依赖: 父Rdd的一个分区被子Rdd的多个分区所依赖。“超生”
groupByKey和reduceByKey哪个效率更高,为什么?
reduceByKey更高
原因:前期进行了预聚合
map和mapPartition的区别,哪个效率高?
Map:针对每一个元素进行操作,mapPartition针对每个分区中的元素进行操作。
mapPartition效率更高
Map:每来一条数据都将开启关闭一次数据库,给数据库造成的压力非常大
mapPartition:没一个分区当中的元素需要开启关闭一次数据库,相对给数据库造成的压力小很多。
SparkCore程序入口
val conf: SparkConf = new SparkConf().setAppName(“wordcount”).setMaster(“local[*]”)
val sc = new SparkContext(conf)
打包注意
.setMaster(“local[*]”)需要注释掉
路径改成arg[0]等
拷贝主类路径
转换算子
aggregateByKey:第一个参数是一个初始值,参与运算;第二个参数,是分区之内进行操作;第三个参数是分区之间进行操作
//aggregateByKey:第一个参数是一个初始值,参与运算;第二个参数,是分区之内进行操作;第三个参数是分区之间进行操作
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8),("a",33),("c",6)),3)
rdd.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
// val result: RDD[(String, Int)] = rdd.aggregateByKey(10)(math.max(_,_),_+_)
//变形
val result: RDD[(String, Int)] = rdd.aggregateByKey(10)(_+_,_+_)
result.foreach(println)
/*结果
1:(c,4),(b,3),(c,6)
0:(a,3),(a,2)
2:(c,8),(a,33),(c,6)
(c,44)
(b,13)
(a,58)
*/
combineByKey:第一个参数,初始化;第二个参数,分区之内进行操作,第三个参数,分区之间进行操作 初始化只针对每个partition中,每个相同key下的第一个数据进行操作
val rdd1 = sc.parallelize(List(1,2,2,3,3,3,3,4,4,4,4,4), 2)
val rdd2: RDD[(Int, Int)] = rdd1.map((_,1))
rdd2.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
val result: RDD[(Int, Int)] = rdd2.combineByKey(-_,(a:Int,b:Int)=>a+b,(a:Int,b:Int)=>a+b)
result.foreach(println)
/*结果
0:(1,1),(2,1),(2,1),(3,1),(3,1),(3,1)
1:(3,1),(4,1),(4,1),(4,1),(4,1),(4,1)
(1,-1)
(3,0)
(4,3)
(2,0)
*/
缓存和检查点的区别
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志),也不能丢掉, 当某个点某个 executor 宕了,上面cache 的RDD就会丢掉, 需要通过依赖链重放计算出来,不同的是checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









