







简街实时市场数据预测
案例描述
在处理现代金融市场的建模问题时,有很多理由相信你试图解决的问题是不可能的。即使你抛开金融工具价格合理地反映了所有可用信息的信念,你也必须努力解决时间序列和分布,这些时间序列和分布具有您在其他类型的建模问题中没有遇到的属性。分布可能是著名的肥尾,时间序列可能是非静止的,数据通常可能无法满足非常成功的统计方法所依赖的许多基本假设。所有这些事实是,金融市场最终是一项人类努力,涉及大量个人和机构,这些个人和机构随着技术的进步和社会的变化而不断变化,并在出现经济和地缘政治问题时做出反应——你可以开始感受到所涉及的困难!
在这个挑战中,我们要求您使用从我们一些生产系统中提取的现实世界数据构建一个模型。这些数据非常仔细地描绘了我们每天为了在现代金融市场交易中取得成功而必须做的一些事情。我们收集了一系列与我们运行自动交易策略的市场相关的功能和响应器,并关注拥有良好的基础模型。为了平衡制定与我们业务相关的具有挑战性的相关问题,同时尊重我们交易的专有性和高度竞争性,您会注意到,我们已经匿名化并略微模糊了我们在数据中呈现的一些功能和响应者。这些修改不会改变手头问题的本质,但它们确实允许我们给你一个艰巨的任务,有意义地说明了我们在简街所做的工作。
Jane Street花了几十年时间不懈地创新我们交易的各个方面,并构建机器学习模型来帮助我们的决策。这些模型帮助我们每天在全球200多个交易场所积极交易数千种金融产品。
案例目标
使用来自生产系统的真实世界数据构建一个模型,挑战凸显了模拟金融市场的困难,包括肥尾分布、非静止时间序列和市场行为的突然变化。
评估
提交材料在评分函数上进行评估,该函数定义为样本加权零均值R平方得分(R2)responder_6
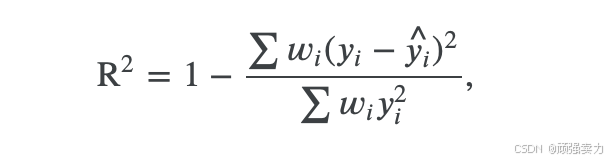
数据集描述
数据集由一组时间序列组成,有79个特征和9个响应者,匿名化,但代表真实的市场数据。目标是预测其中一个响应者,即responder_6,在未来长达六个月,但是本次仅为案例学习,未来的数据不进行提供。
文件和字段信息
训练集:包含历史数据和返回值。为方便起见,将训练集划分为十个部分。
date_id和time_id:按顺序排序的整数值,为数据提供时间顺序结构,尽管time_id值之间的实际时间间隔可能会有所不同。
symbol_id :标识唯一的金融工具。
weight :用于计算评分函数的权重。
feature_{00……78} :匿名市场数据。
responder_{0…8} :匿名响应者在-5到5之间剪切。responder_6字段是您试图预测的内容。
测试集:它表示未见测试集的结构。这个示例集演示了由评估API服务的单个批处理,即来自单个date_id, time_id对的数据。测试集包含的列包括date_id、time_id、symbol_id、weight、is_scoring和feature_{00…78}。
滞后:parquet - responder_{0…8}滞后一个date_id。评估API在date_id的第一个time_id上为date_id的所有滞后响应器提供服务。换句话说,所有前一个日期的应答者都将在后一个日期的第一个时间步得到服务。
sample_submit .csv:该文件说明了模型应该做出的预测的格式。
features.csv:与匿名特性相关的元数据
responders.csv:与匿名应答者相关的元数据
{train/test}中的每一行,Parquet数据集对应于符号(由symbol_id标识)和时间戳(由date_id和time_id表示)的唯一组合。您将获得多个响应器,其中responder_6是唯一用于评分的响应器。date_id列是一个整数,表示事件发生的日期,而time_id表示时间顺序。需要注意的是,不能保证每个time_id之间的实时差异是一致的。
symbol_id列包含加密的标识符。每个symbol_id不保证出现在所有time_id和date_id组合中。此外,新的symbol_id值可能会出现在未来的测试集中。
EDA
import numpy as np # 导入numpy库,用于线性代数运算、数值计算等操作
import pandas as pd # 导入pandas库,用于数据处理及读写常见数据文件格式
import polars as pl # 导入polars库,用于数据处理
import matplotlib.pyplot as plt # 导入matplotlib的绘图模块,用于数据可视化
import seaborn as sns # 导入seaborn库,用于更便捷美观地绘制统计图表
from matplotlib.ticker import MaxNLocator, FormatStrFormatter, PercentFormatter # 导入matplotlib的坐标轴刻度格式化相关类
import os, gc # 导入os模块用于操作系统交互,gc模块用于垃圾回收
from tqdm.auto import tqdm # 导入tqdm用于显示循环等操作的进度条
import pickle # 导入pickle模块,用于对象的序列化与反序列化
import re # 导入re模块,用于正则表达式操作
import tensorflow as tf # 导入tensorflow深度学习框架
from tensorflow.keras import layers, models # 导入tensorflow中构建神经网络层和模型的模块
from tensorflow.keras.optimizers import Adam # 导入tensorflow中的Adam优化器
import torch # 导入torch深度学习框架
import torch.nn as nn # 导入torch中定义神经网络模块的核心模块
import torch.nn.functional as F # 导入torch中包含张量操作函数的模块
from torch.utils.data import Dataset, DataLoader # 导入torch中定义数据集和数据加载器的模块
from pytorch_lightning import (LightningDataModule, LightningModule, Trainer) # 导入pytorch_lightning中管理数据、组织模型逻辑及控制训练过程的相关类
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint, Timer # 导入pytorch_lightning中的训练回调函数类
from sklearn.metrics import r2_score # 导入sklearn中用于评估回归模型性能的指标函数
from sklearn.model_selection import train_test_split # 导入sklearn中划分数据集的函数
from sklearn.ensemble import VotingRegressor # 导入sklearn中集成学习的投票回归器
import lightgbm as lgb # 导入lightgbm库,用于构建LightGBM模型
from lightgbm import LGBMRegressor # 导入LightGBM回归模型类
from xgboost import XGBRegressor # 导入XGBoost回归模型类
from catboost import CatBoostRegressor # 导入CatBoost回归模型类
import warnings
warnings.filterwarnings('ignore') # 忽略所有警告信息
pd.options.display.max_columns = None # 设置pandas显示数据时不限制显示列数
gridColor = (0.8, 0.8, 0.8) # 这里的RGB值表示浅灰色,可根据实际需要微调RGB分量来调整颜色深浅
%%time
path = "/kaggle/input/jane-street-real-time-market-data-forecasting"
samples = []
# 循环读取指定路径下5个分区的数据文件,并存入samples列表
for i in range(5):
file_path = f"{path}/train.parquet/partition_id={i}/part-0.parquet"
part = pd.read_parquet(file_path)
samples.append(part)
# 将读取的各分区数据合并为一个数据框架,忽略原索引并重新生成连续索引
sample_df = pd.concat(samples, ignore_index=True)
# 对合并后的数据框架中的数值型数据四舍五入,保留一位小数(原代码未进一步处理此操作结果)
sample_df.round(1)
# 将sample_df赋值给train,后续基于train操作
train = sample_df
# 在train数据框中新增两列,值都取数据框的索引值
train['N'] = train.index.values
train['id'] = train.index.values
# 从sample_df中筛选出symbol_id等于1的数据行,提取其中的'id'列数据赋值给xx
xx = sample_df[sample_df.symbol_id == 1]['id']
# 从sample_df中筛选出symbol_id等于1的数据行,提取其中的'responder_6'列数据赋值给yy
yy = sample_df[sample_df.symbol_id == 1]['responder_6']
# 创建新图形对象,设置图形尺寸
plt.figure(figsize=(16, 5))
# 绘制折线图,横坐标为xx数据,纵坐标为yy数据,设置线条颜色和线宽
plt.plot(xx, yy, color='black', linewidth=0.05)
# 为图形添加主标题,设置字体加粗、字号
plt.suptitle('Returns, responder_6', weight='bold', fontsize=16)
# 给横坐标添加标签,说明含义并设置字号
plt.xlabel('Time', fontsize=12)
# 给纵坐标添加标签,说明含义并设置字号
plt.ylabel('Returns', fontsize=12)
# 添加网格线,颜色由外部变量gridColor指定,设置线宽
plt.grid(color=gridColor, linewidth=0.8)
# 在纵坐标0值位置绘制水平直线,设置颜色、线型和线宽
plt.axhline(0, color='red', linestyle='-', linewidth=1.2)
# 显示绘制好的图形
plt.show()
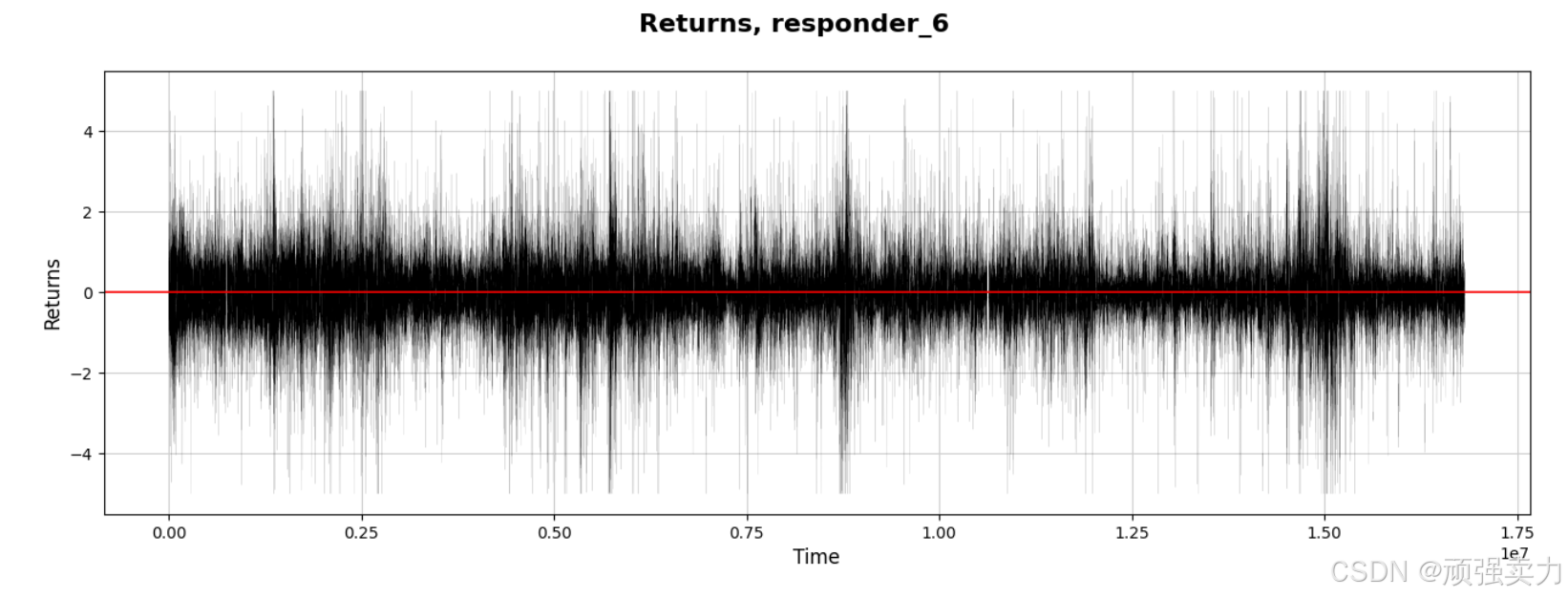
图中的折线代表了 “responder_6” 在不同时间点的回报率(Returns)。从图中可以看到,回报率在大部分时间内都在 0 附近波动,但波动幅度较大,有时会达到 4,有时会低至 -4。折线的波动频率较高,显示出回报率的变化非常频繁。
# 创建新图形对象,设置图形尺寸为宽14单位、高4单位
plt.figure(figsize=(14, 4))
# 绘制折线图,横坐标为xx数据,纵坐标为yy数据的累积和,设置线条颜色和线宽
plt.plot(xx, yy.cumsum(), color='black', linewidth=0.6)
# 为图形添加主标题,设置字体加粗、字号为16
plt.suptitle('Cumulative responder_6', weight='bold', fontsize=16)
# 给横坐标添加标签,说明代表时间,设置字号为12
plt.xlabel('Time', fontsize=12)
# 给纵坐标添加标签,说明代表累积的响应值,设置字号为12
plt.ylabel('Cumulative res', fontsize=12)
# 设置纵坐标刻度,刻度值从-500到1000,间隔为250
plt.yticks(np.arange(-500, 1000, 250))
# 按照gridColor变量指定的颜色添加网格线(gridColor需外部定义)
plt.grid(color=gridColor)
# 在纵坐标0值位置绘制水平直线,设置颜色、线型和线宽
plt.axhline(0, color='red', linestyle='-', linewidth=0.7)
# 显示绘制好的图形
plt.show()
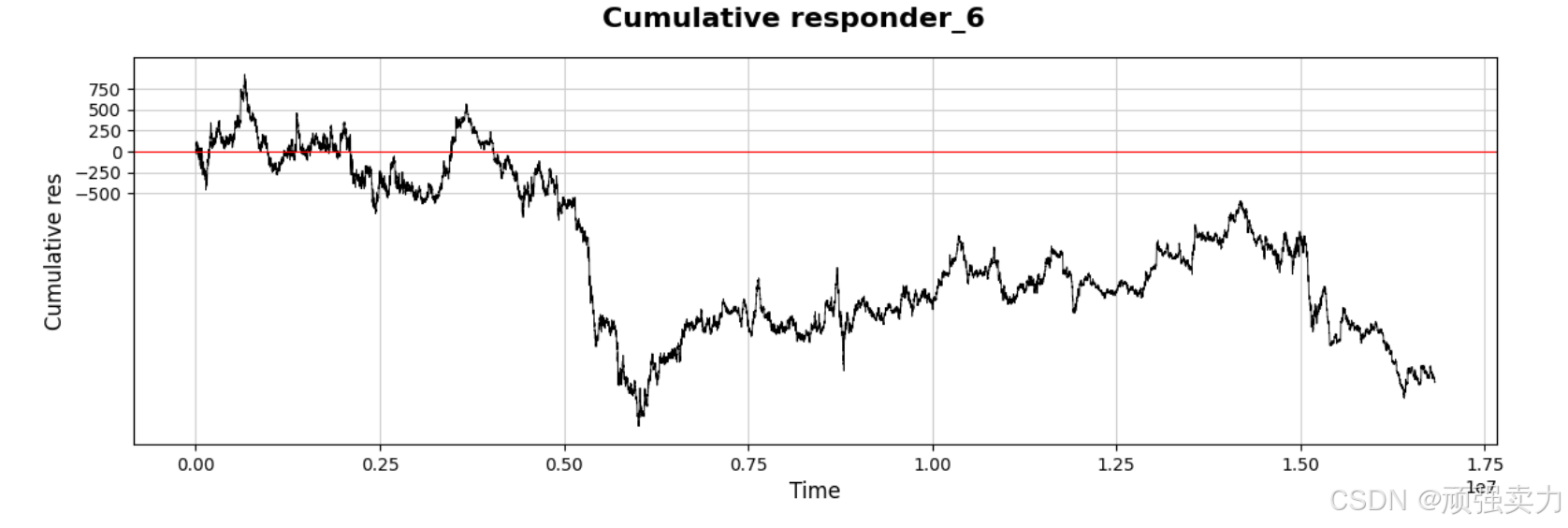
图中的折线代表了 “responder_6” 在不同时间点的累积结果。从图中可以看到,累积结果在整个时间段内波动较大,呈现出多次上下起伏的形态。折线在某些时间段内迅速上升或下降,显示出数据变化的剧烈程度。
# 创建一个新的图形,设置图形大小为宽18、高7
plt.figure(figsize=(18, 7))
# 从sample_df的列名中筛选出包含'responder'的列名,存储在predictor_cols列表中
predictor_cols = [col for col in sample_df.columns if 'responder' in col]
for i in predictor_cols:
# 如果列名是'responder_6'
if i == 'responder_6':
# 设置线条颜色为红色,线宽为2.5
c = 'red'
lw = 2.5
# 对sample_df中symbol_id等于0的数据按'date_id'分组,对每组中的i列求平均,再求累积和后绘制折线图,使用设置好的线宽和颜色
plt.plot((sample_df[sample_df.symbol_id == 0].groupby(['date_id'])[i].mean()).cumsum(), linewidth=lw, color=c)
else:
# 设置线宽为1
lw = 1
# 对sample_df中symbol_id等于0的数据按'date_id'分组,对每组中的i列求平均,再求累积和后绘制折线图,使用设置好的线宽
plt.plot((sample_df[sample_df.symbol_id == 0].groupby(['date_id'])[i].mean()).cumsum(), linewidth=lw)
# 给横轴添加标签“Trade days”
plt.xlabel('Trade days')
# 给纵轴添加标签“Cumulative response”
plt.ylabel('Cumulative response')
# 为图形添加标题,标题内容为“Response time series over trade days”,并且说明Responder 6(红色)和其他响应器,标题字体加粗
plt.title('Response time series over trade days \n Responder 6 (red) and other responders', weight='bold')
# 添加网格线,网格线可见,颜色由gridColor变量决定,线宽为0.7
plt.grid(visible=True, color=gridColor, linewidth=0.7)
# 在纵轴0位置绘制一条蓝色的水平直线,线宽为1,线型为实线
plt.axhline(0, color='blue', linestyle='-', linewidth=1)
# 添加图例,图例内容为predictor_cols中的列名
plt.legend(predictor_cols)
# 去除图形的边框
sns.despine()
# 显示图形
plt.show()
图中展示了多个应答者(responder)在交易日(trade days)内的累积响应(Cumulative responses)变化情况。
-
横轴和纵轴
- 横轴表示交易日(Trade days),范围从0到800。
- 纵轴表示累积响应(Cumulative responses),范围从 -10到10。
-
线条颜色和图例
- 图中有九条不同颜色的折线,分别代表不同的应答者。
- 图例位于图表的左下角,列出了每种颜色对应的应答者编号:
- 蓝色(responder_0)
- 橙色(responder_1)
- 绿色(responder_2)
- 红色(responder_3)
- 紫色(responder_4)
- 黄色(responder_5)
- 深红色(responder_6)
- 粉色(responder_7)
- 灰色(responder_8)
-
主要趋势和特征
- 所有的折线都在纵轴 -10到10之间波动。
- 深红色(responder_6)的折线在图中较为显眼,波动幅度较大。
- 大多数折线在某些时间段内呈现出相似的波动趋势,但在其他时间段内则有较大差异。
- 图中有两条水平的虚线,分别位于累积响应为0和 -5的位置,作为参考线。
-
背景和应用
- 展示不同交易者或策略在多个交易日内的累积收益或响应情况。
- 通过比较不同折线的波动和趋势,可以分析不同交易者的表现和策略的有效性。
# 创建新图形对象,设置图形尺寸为宽6单位、高6单位
plt.figure(figsize=(6, 6))
# 读取指定路径下的responders.csv文件,将数据存储在responders变量中
responders = pd.read_csv(f"{path}/responders.csv")
# 从responders数据框中选取特定列(tag_0到tag_4)的数据,转置后计算相关性矩阵
matrix = responders[[ f"tag_{no}" for no in range(0, 5, 1) ] ].T.corr()
# 绘制热力图,传入相关参数设置热力图样式、颜色映射、数值显示等情况
sns.heatmap(matrix, square=True, cmap="coolwarm", alpha=0.9, vmin=-1, vmax=1, center=0, linewidths=0.5,
linecolor='white', annot=True, fmt='.2f')
# 给横坐标添加标签,大致表示与响应器相关
plt.xlabel("Responder_0 - Responder_8")
# 给纵坐标添加标签,大致表示与响应器相关
plt.ylabel("Responder_0 - Responder_8")
# 显示绘制好的图形
plt.show()
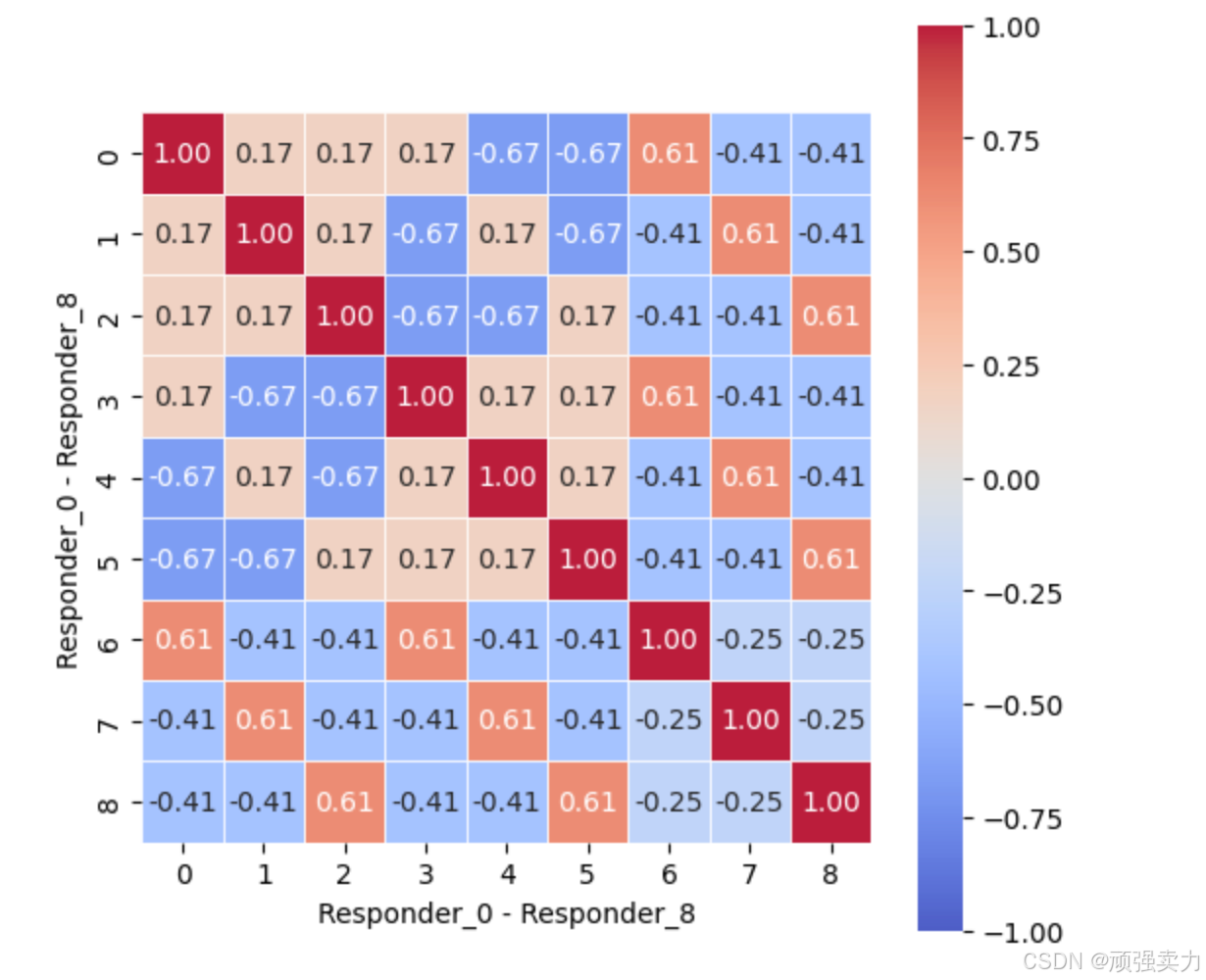
热力图展示了9个响应者(Responder_0 - Responder_8)之间的相关性。
-
结构和布局
- 图表是一个9×9的矩阵,横轴和纵轴都标记为Responder_0 - Responder_8。
- 每个方格代表两个响应者之间的相关性。
- 颜色编码用于表示相关性的强度和方向:
- 红色表示正相关,颜色越深,正相关性越强,最红的方格相关性为1.00。
- 蓝色表示负相关,颜色越深,负相关性越强,最蓝的方格相关性为 - 1.00。
- 白色表示相关性为0。
-
主要特征
- 对角线上的方格(例如,Responder_0与Responder_0、Responder_1与Responder_1等)都是红色,且颜色最深,表示自身与自身的相关性为1.00。
- 非对角线上的方格颜色各异:
- 例如,Responder_0与Responder_1之间是浅红色,相关性为0.17。
- Responder_0与Responder_4之间是深蓝色,相关性为 - 0.67。
- Responder_4与Responder_5之间是红色,相关性为0.17。
# 将sample_df赋值给df_train
df_train = sample_df
# 设置符号标识为0,可修改此值查看其他符号的数据
s_id = 0
# 筛选出df_train中列名以'responder_'开头的列名
res_columns = [col for col in df_train.columns if re.match("responder_", col)]
# 初始化行和列索引
row = 9
j = 0
# 创建包含多个子图的图形,设置图形大小
fig, axs = plt.subplots(figsize=(18, 4 * row))
# 循环绘制每个响应器的三个子图
for i in range(1, 3 * len(res_columns) + 1, 3):
# 从sample_df中筛选出symbol_id等于s_id的数据,提取'N'列和'responder_'列数据
xx = sample_df[(sample_df.symbol_id == s_id)]['N']
yy = sample_df[(sample_df.symbol_id == s_id)][f'responder_{j}']
# 根据列名是否为'responder_6'设置线条颜色
if j == 6:
color = 'red'
else:
color = 'black'
# 绘制第一个子图(累积和图)
ax1 = plt.subplot(9, 3, i)
ax1.plot(xx, yy.cumsum(), color=color, linewidth=0.8)
ax1.axhline(0, color='blue', linestyle='-', linewidth=0.9)
ax1.grid(color=gridColor)
# 绘制第二个子图(原始数据图)
ax2 = plt.subplot(9, 3, i + 1)
ax2.plot(xx, yy, color=color, linewidth=0.05)
ax2.axhline(0, color='blue', linestyle='-', linewidth=1.2)
ax2.set_title(f"responder_{j}", fontsize=14)
ax2.grid(color=gridColor)
# 绘制第三个子图(直方图)
ax3 = plt.subplot(9, 3, i + 2)
b = 1000
ax3.hist(yy, bins=b, color=color, density=True, histtype="step")
ax3.hist(yy, bins=b, color='lightgrey', density=True)
ax3.grid(color=gridColor)
ax3.set_ylim([0, 3.5])
ax3.set_xlim([-2.5, 2.5])
# 列索引自增1,用于下一次循环选择下一个'responder'列名
j += 1
# 设置图形的边框线宽、颜色和背景颜色
fig.patch.set_linewidth(3)
fig.patch.set_edgecolor('#000000')
fig.patch.set_facecolor('#eeeeee')
# 显示图形
plt.show()
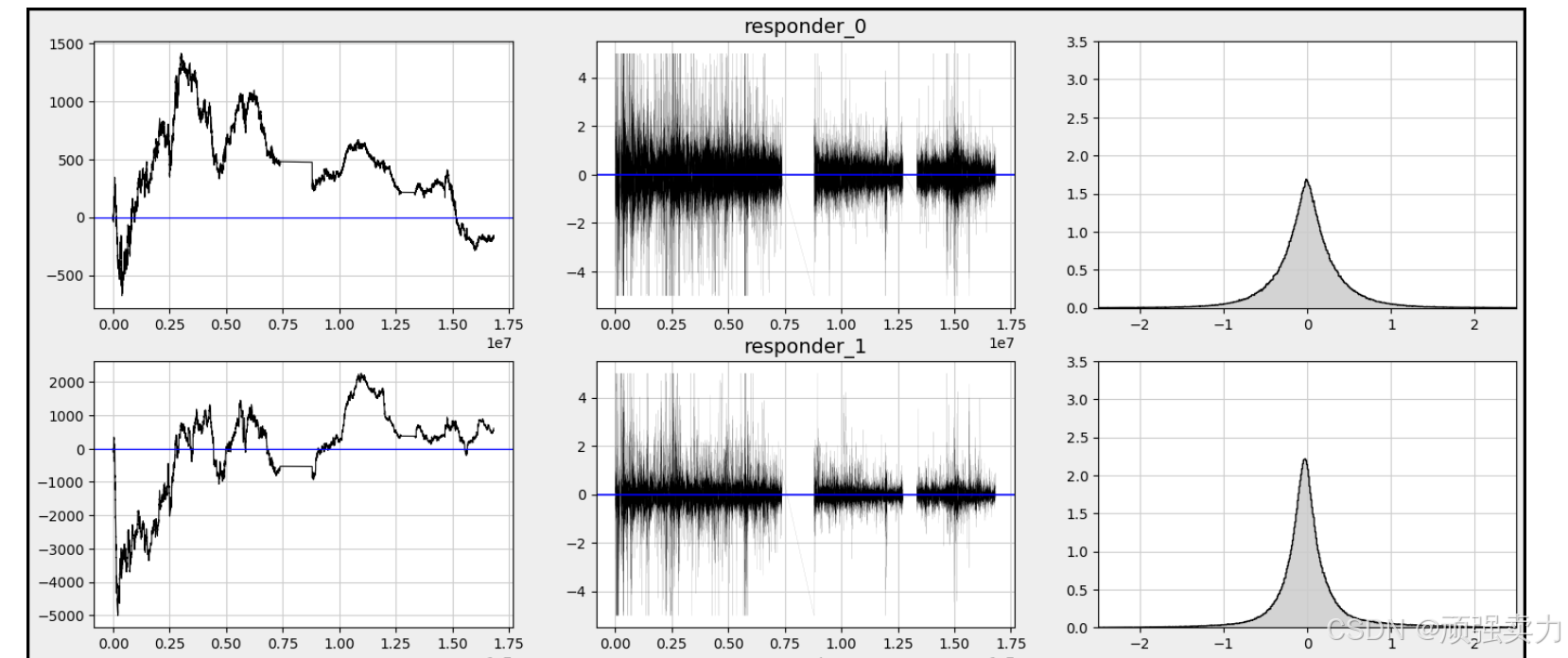
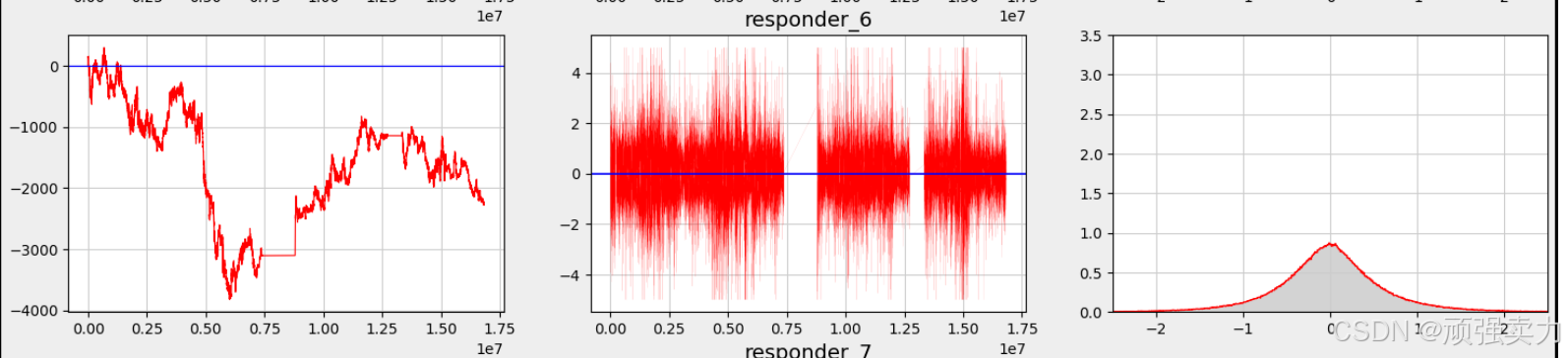
左侧是时间序列图,右侧是概率密度函数图。
res_columns = [col for col in df_train.columns if re.match("responder_", col)]
row = 10
fig, axs = plt.subplots(figsize=(18, 5 * row))
b = 300
j = 0
for i in range(1, 3 * row + 1, 3):
# 从sample_df中筛选出symbol_id等于当前j值的数据,获取其中名为'N'的列数据
xx = sample_df[(sample_df.symbol_id == j)]['N']
# 从sample_df中筛选出symbol_id等于当前j值的数据,获取其中名为'responder_6'的列数据
yy = sample_df[(sample_df.symbol_id == j)]['responder_6']
c = 'black'
# 创建位于第row行、第3列、第i个位置的子图对象ax1
ax1 = plt.subplot(row, 3, i)
# 在ax1子图上绘制以xx为横坐标、yy数据累积和为纵坐标的折线图,设置线条颜色为c(黑色),线宽为0.8
ax1.plot(xx, yy.cumsum(), color=c, linewidth=0.8)
# 在ax1子图纵坐标为0的位置绘制一条红色、线宽为0.7、线型为实线的水平直线
plt.axhline(0, color='red', linestyle='-', linewidth=0.7)
# 在ax1子图上添加网格线,网格线颜色由gridColor变量指定
plt.grid(color=gridColor)
# 给ax1子图的横坐标添加标签,标签内容为“Time”
plt.xlabel('Time')
# 创建位于第row行、第3列、第i + 1个位置的子图对象ax2
ax2 = plt.subplot(row, 3, i + 1)
# 在ax2子图上绘制以xx为横坐标、yy数据为纵坐标的折线图,设置线条颜色为c(黑色),线宽为0.05
ax2.plot(xx, yy, color=c, linewidth=0.05)
# 在ax2子图纵坐标为0的位置绘制一条红色、线宽为0.7、线型为实线的水平直线
plt.axhline(0, color='red', linestyle='-', linewidth=0.7)
# 为ax2子图设置标题,标题内容为当前的symbol_id的值,设置字号为14
ax2.set_title(f"symbol_id={j}", fontsize='14')
# 在ax2子图上添加网格线,网格线颜色由gridColor变量指定
plt.grid(color=gridColor)
# 给ax2子图的横坐标添加标签,标签内容为“Time”
plt.xlabel('Time')
# 创建位于第row行、第3列、第i + 2个位置的子图对象ax3
ax3 = plt.subplot(row, 3, i + 2)
# 在ax3子图上绘制yy数据的直方图,设置直方图的区间数量为b(300),颜色为c(黑色),绘制为概率密度直方图且直方图类型为阶梯状
ax3.hist(yy, bins=b, color=c, density=True, histtype="step")
# 在ax3子图上绘制yy数据的填充式直方图,设置直方图的区间数量为b(300),颜色为'lightgrey'(浅灰色),绘制为概率密度直方图
ax3.hist(yy, bins=b, color='lightgrey', density=True)
# 在ax3子图上添加网格线,网格线颜色由gridColor变量指定
plt.grid(color=gridColor)
# 设置ax3子图横坐标的显示范围,最小值为 -2.5,最大值为2.5
ax3.set_xlim([-2.5, 2.5])
# 设置ax3子图纵坐标的显示范围,最小值为0,最大值为1.5
ax3.set_ylim([0, 1.5])
# 给ax3子图的横坐标添加标签,标签内容为“Time”
plt.xlabel('Time')
j += 1
# 设置整个图形的边框线宽为3
fig.patch.set_linewidth(3)
# 设置整个图形的边框颜色为黑色
fig.patch.set_edgecolor('#000000')
# 设置整个图形的背景颜色为十六进制颜色码#eeeeee对应的浅灰色
fig.patch.set_facecolor('#eeeeee')
# 显示绘制好的图形
plt.show()
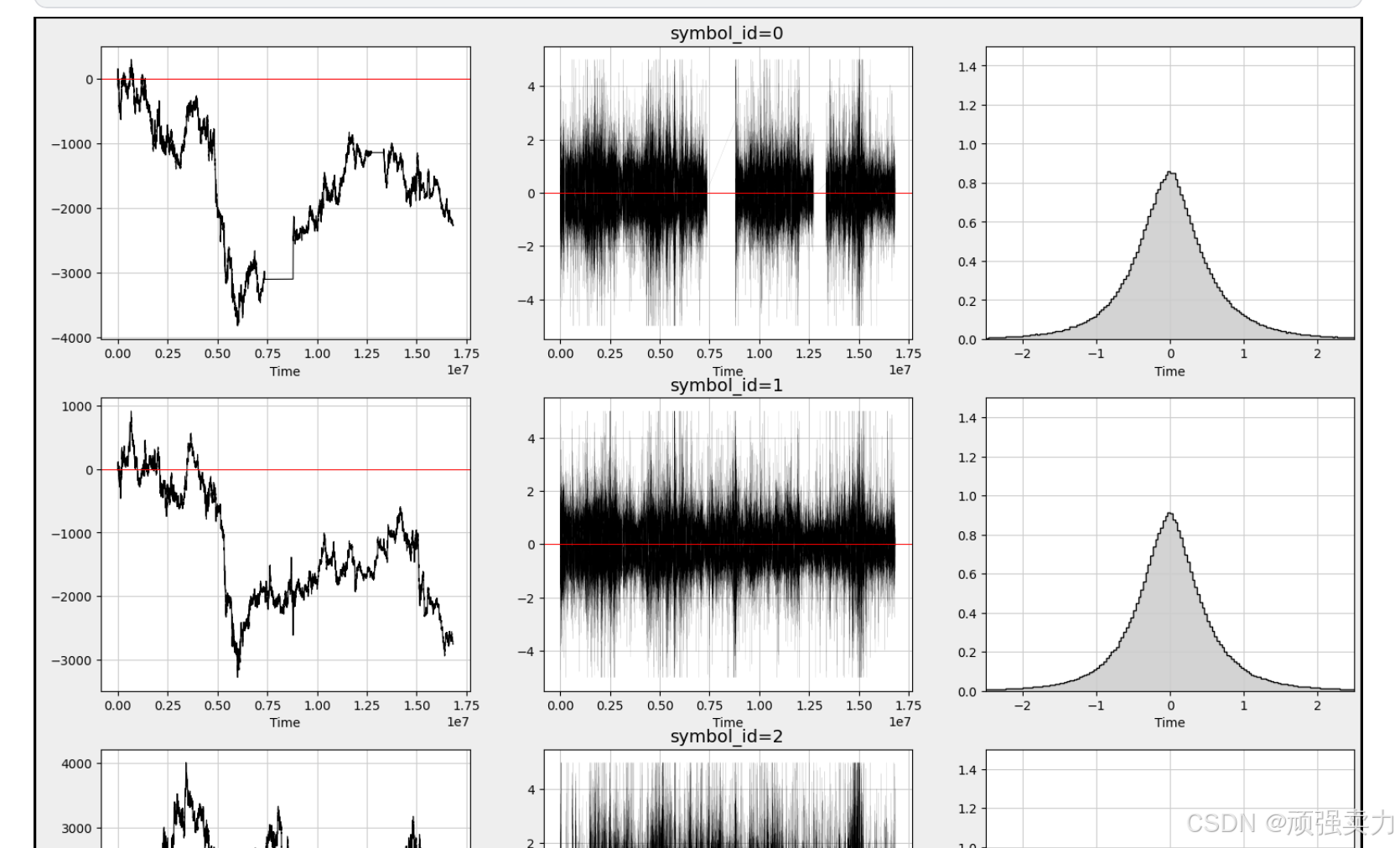
# 将sample_df赋值给df_train,方便后续操作
df_train = sample_df
# 创建一个图形,设置图形大小为宽20单位、高3单位,目的是用于绘制缺失值情况
plt.figure(figsize=(20, 3))
# 绘制柱状图,横坐标为df_train中每列缺失值数量的索引(也就是列名),纵坐标为每列缺失值的数量,设置柱子颜色为红色,并添加标签为'missing',这里类似于使用missingno库来展示缺失值情况
plt.bar(x=df_train.isna().sum().index, height=df_train.isna().sum().values, color="red", label='missing')
# 将横坐标的刻度标签旋转90度,使其更便于查看和展示,避免文字重叠等情况
plt.xticks(rotation=90)
# 为图形添加标题,标题内容展示在具有目标值的样本数量(由len(df_train)获取)中缺失值的情况
plt.title(f'Missing values over the {len(df_train)} samples which have a target')
# 在图形上添加网格线,使图形看起来更清晰,便于查看数据对应的位置等信息
plt.grid()
# 在图形上添加图例,图例展示之前设置的'missing'对应的内容,用于标识图形中元素的含义
plt.legend()
# 显示绘制好的图形,呈现可视化的效果,方便查看数据中各列缺失值的数量情况
plt.show()
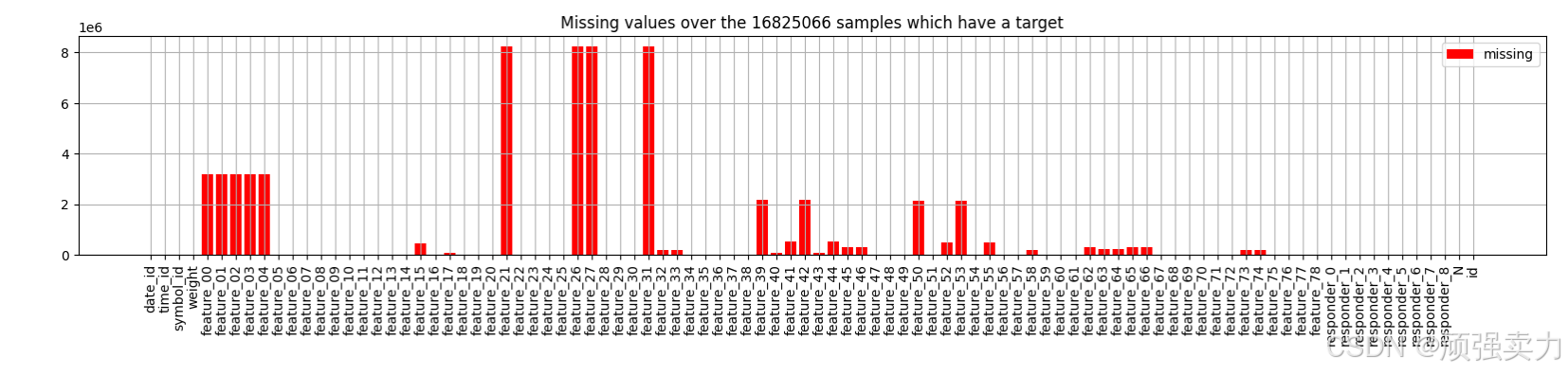
图表结构
- 横轴
- 横轴上标注了多个类别,从左到右依次为“date”、“time”、“id”、“weight”、“feature_0”、“feature_1”等,一直到“responder_0”、“responder_1”等,最后是“g”。
- 这些类别代表了不同的样本特征或响应者。
- 纵轴
- 纵轴表示缺失值(missing values)的数量,范围从0到8。
主要特征
- 柱状图颜色
- 图中的柱子为红色,代表缺失值。
- 数据分布
- 大部分类别对应的缺失值数量为0或1,但有几个类别有较多的缺失值:
- “feature_3”、“feature_4”、“feature_5”、“feature_8”、“feature_9”、“feature_10”、“feature_12”、“feature_18”、“feature_23”、“feature_24”、“feature_25”、“feature_33”等特征的缺失值数量较多,达到了4到8个。
- “responder_0”、“responder_1”、“responder_2”、“responder_3”等响应者也有一定数量的缺失值。
- 大部分类别对应的缺失值数量为0或1,但有几个类别有较多的缺失值:
背景和意义
- 数据处理背景
- 帮助识别数据集中哪些特征或样本存在较多的缺失值。
- 对于有缺失值的特征或样本,我们可能需要采取填充、删除或其他处理方法来确保数据的完整性和可用性。
- 实际应用
- 通过这种图表,可以快速直观地发现数据集中的缺失值问题,并采取相应措施。
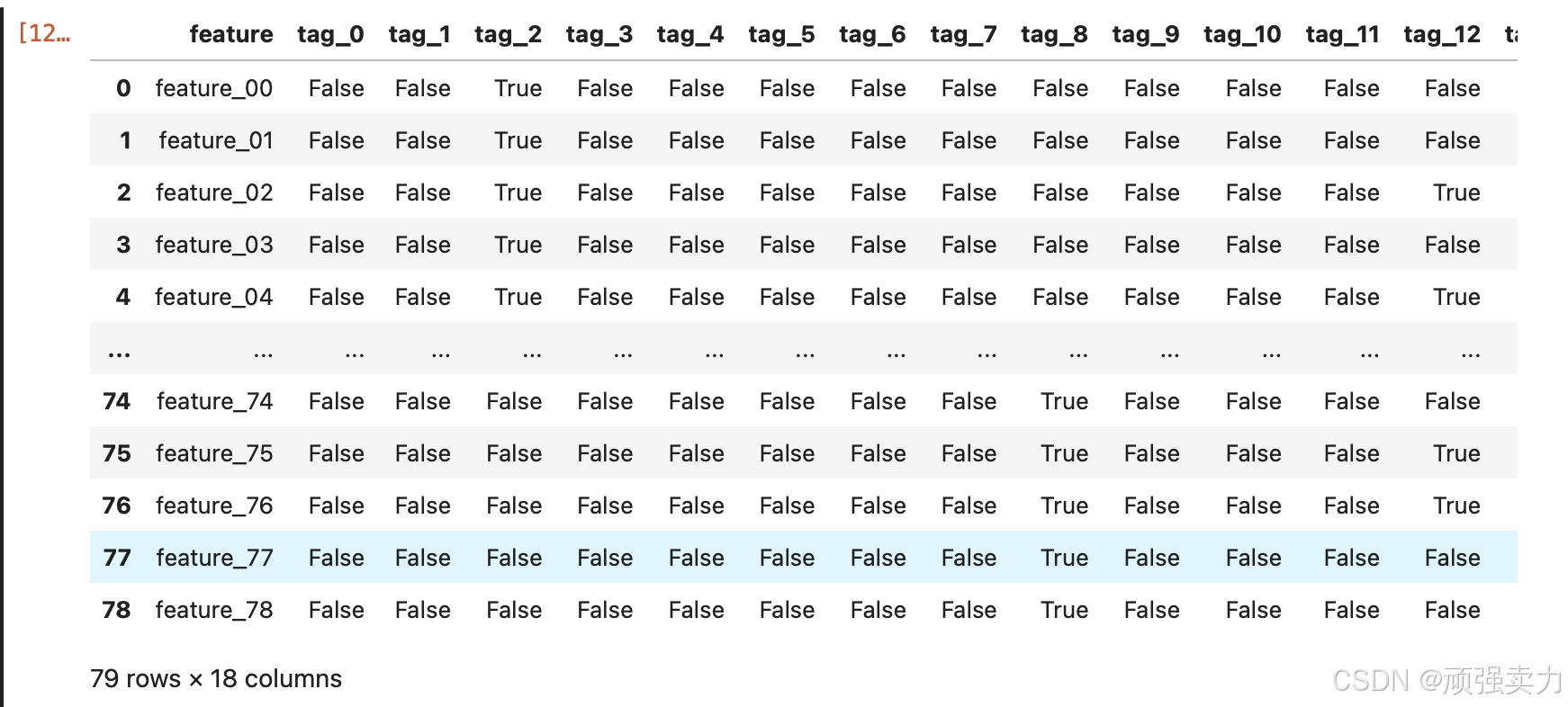
# 使用pandas库的read_csv函数读取指定路径(path变量应该在外部已定义好,指向存有features.csv文件的位置)下的features.csv文件,并将读取到的数据存储在features变量中
features = pd.read_csv(f"{path}/features.csv")
features
# 创建一个新的图形,设置图形的大小为宽18单位、高6单位
plt.figure(figsize=(18, 6))
# 使用imshow函数绘制图像,以features数据框中从第2列(索引为1)开始的所有列的数据(进行转置后的值)作为图像的数据来源,颜色映射采用'gray_r'(灰度反转的颜色映射,通常黑色会显示为白色,白色显示为黑色)
plt.imshow(features.iloc[:, 1:].T.values, cmap="gray_r")
# 给图形的横坐标添加标签,标签内容表示从'feature_00'到'feature_78',大致说明横坐标对应的特征相关信息
plt.xlabel("feature_00 - feature_78")
# 给图形的纵坐标添加标签,标签内容表示从'tag_0'到'tag_16',大致说明纵坐标对应的标签相关信息
plt.ylabel("tag_0 - tag_16")
# 设置纵坐标的刻度位置,刻度范围为从0到16,共17个刻度,用于更规范地显示纵坐标的取值范围
plt.yticks(np.arange(17))
# 设置横坐标的刻度位置,刻度范围为从0到78,共79个刻度,用于更规范地显示横坐标的取值范围
plt.xticks(np.arange(79))
# 在图形上添加网格线,设置网格线的颜色为浅灰色,使图形看起来更清晰、有条理
plt.grid(color = 'lightgrey')
# 显示绘制好的图形,呈现可视化的效果,便于查看和分析图像展示的相关内容
plt.show()
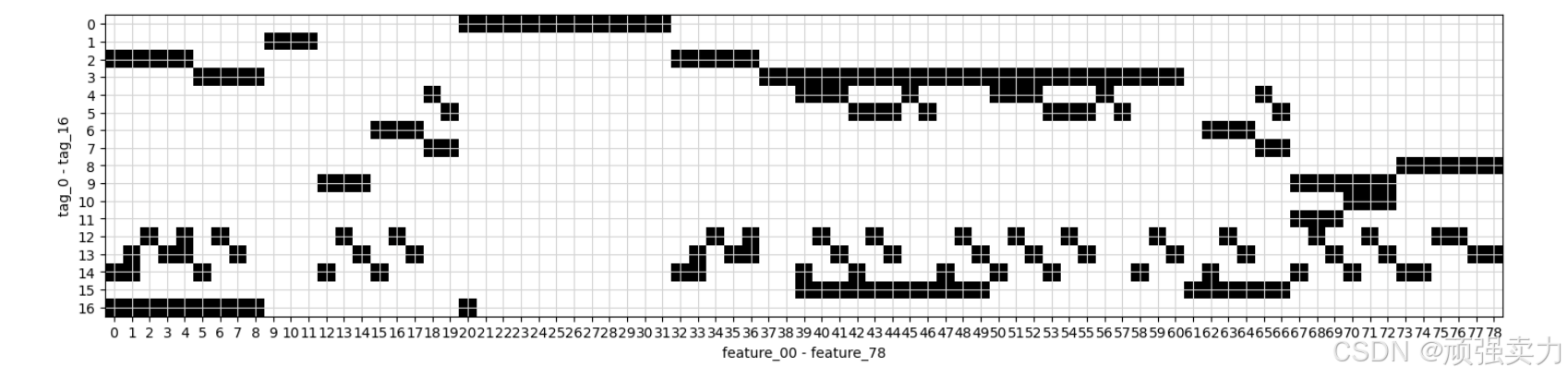
1. 坐标轴
- 横轴:标注为“feature_00 - feature_78”,表示从feature_00到feature_78的特征范围。
- 纵轴:标注为“tag_0 - tag_16”,表示从tag_0到tag_16的标签范围。
2. 数据分布
- 图中的黑色方块代表数据点,它们在网格中不规则地分布。
- 从图中可以看到,黑色方块在横轴和纵轴上都有不同的分布密度。例如,在横轴上,某些特征区间(如feature_10到feature_20)有较多的数据点,而在纵轴上,tag_5到tag_10之间的数据点相对较多。
3. 背景知识
- 图中的每个黑色方块可能代表一个样本,其在横轴和纵轴上的位置表示该样本在不同特征和标签下的取值。
- 通过观察数据点的分布,可以帮助我们了解特征和标签之间的关系,例如是否存在某些特征与特定标签有较强的相关性。
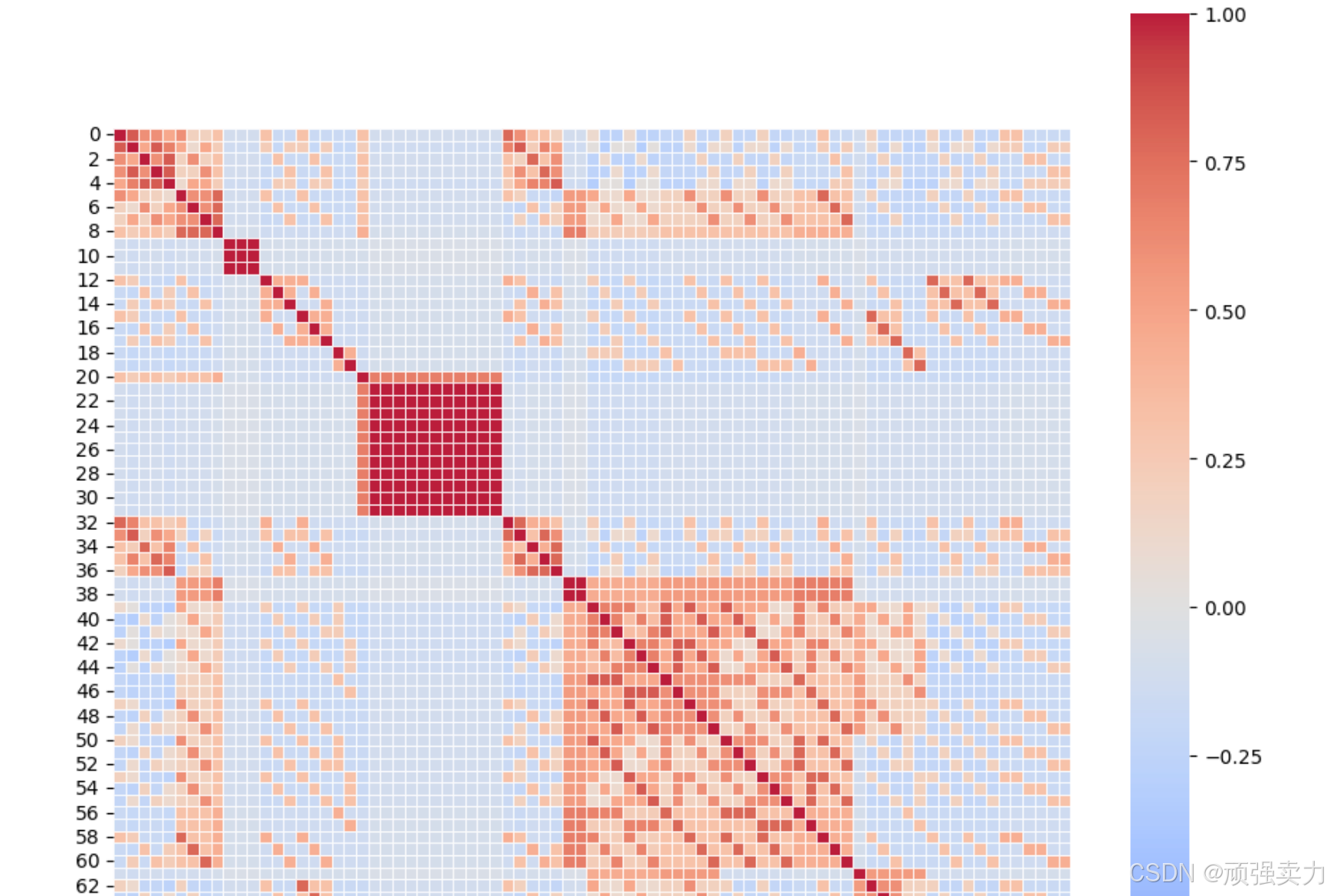
# 创建一个新的图形,设置图形的大小为宽11单位、高11单位
plt.figure(figsize=(11, 11))
# 从features数据框中选取列名为'tag_0'到'tag_16'(通过列表推导式生成列名列表来选取)的数据,然后对选取的数据进行转置,再计算其相关性矩阵,将得到的相关性矩阵赋值给matrix变量
matrix = features[[ f"tag_{no}" for no in range(0, 17, 1) ] ].T.corr()
# 使用seaborn库的heatmap函数绘制热力图,以matrix作为数据来源(即前面计算得到的相关性矩阵),设置热力图方格为正方形,使用'coolwarm'颜色映射(用冷色调表示负相关,暖色调表示正相关),设置透明度为0.9,颜色映射的最小值为 -1、最大值为1(因为相关系数范围在 -1到1之间),颜色映射的中心值为0(用于区分正负相关),方格间隔线的线宽为0.5,方格间隔线的颜色为白色
sns.heatmap(matrix, square=True, cmap="coolwarm", alpha =0.9, vmin=-1, vmax=1, center= 0, linewidths=0.5, linecolor='white')
# 显示绘制好的图形,呈现出可视化的热力图,便于直观查看各'tag'之间的相关性情况
plt.show()
responders = pd.read_csv(f"{path}/responders.csv")
responders
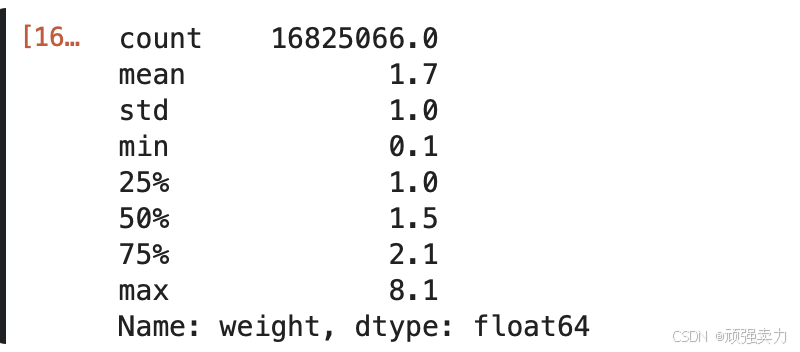
sample_df['weight'].describe().round(1)
# 创建一个新的图形,设置图形的大小为宽8单位、高3单位
plt.figure(figsize=(8, 3))
# 绘制直方图,以sample_df数据框中'weight'列的数据作为数据源,设置直方图的区间数量为30,柱子颜色为灰色,柱子边缘颜色为白色,并且将直方图设置为概率密度直方图(纵轴表示概率密度)
plt.hist(sample_df['weight'], bins=30, color='grey', edgecolor = 'white',density=True )
# 为图形添加标题,标题内容为“权重的分布”,用于说明该直方图所展示的内容主题
plt.title('Distribution of weights')
# 在图形上添加网格线,设置网格线颜色为浅灰色,线宽为0.5,使图形更清晰,便于查看数据分布情况
plt.grid(color = 'lightgrey', linewidth=0.5)
# 在横坐标值为1.7的位置绘制一条垂直的直线,设置直线颜色为红色,线型为实线,线宽为0.7,用于作为参考线辅助查看数据分布特点等情况
plt.axvline(1.7, color='red', linestyle='-', linewidth=0.7)
# 显示绘制好的图形,呈现可视化的效果,方便查看权重数据的分布情况以及参考线对应的情况
plt.show()
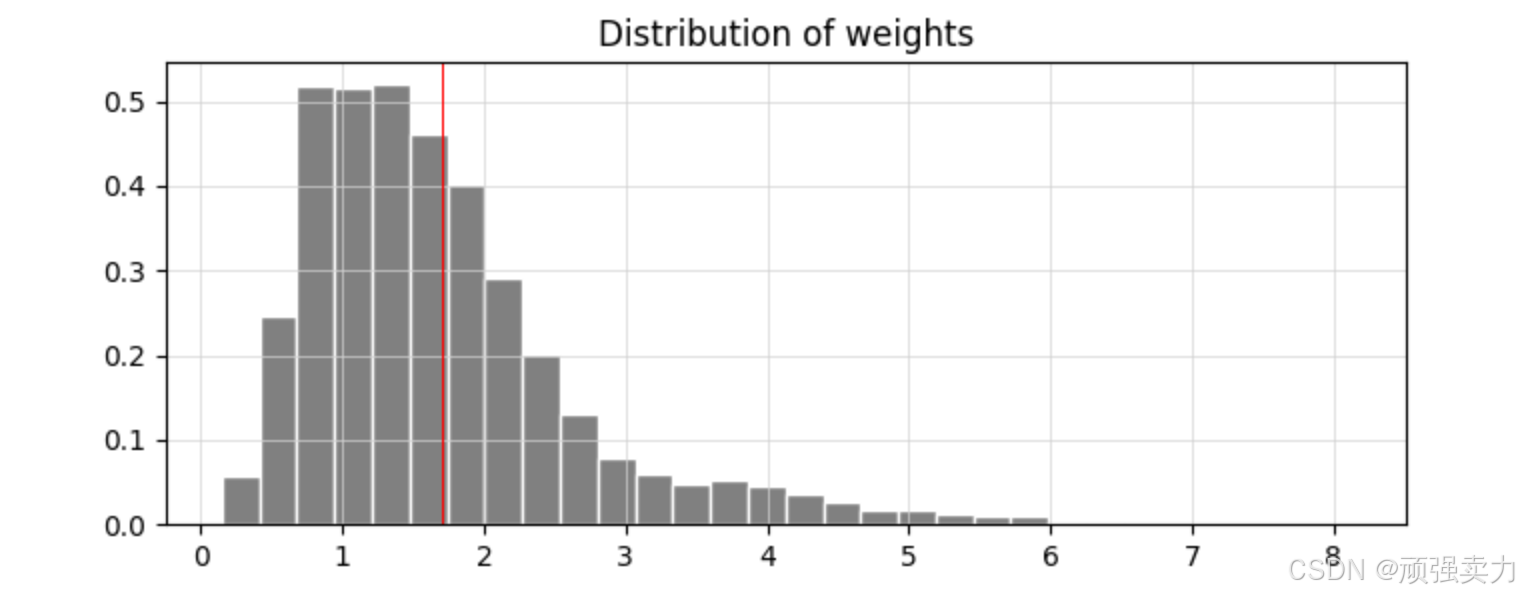
1. 坐标轴
- 横轴:表示权重值,范围从0到8。
- 纵轴:表示频率,范围从0.0到0.5。
2. 柱状图内容
- 每个柱子代表一个权重值出现的频率。
- 权重值为0的频率较低,大约在0.1左右。
- 权重值为1和2的频率最高,接近0.5。
- 权重值从3到8,频率逐渐降低。
3. 红色竖线
- 在权重值为2的位置有一条红色竖线,用于突出显示这个权重值,或者表示某种特定的参考值。
4. 背景知识
- 在机器学习和数据挖掘中,权重值的分布可以帮助分析模型的参数分布,了解模型的复杂性和训练效果。
- 红色竖线用于标记一个重要的阈值或参考值,帮助我们快速识别特定权重值的重要性。
# 使用pandas库的read_csv函数读取指定路径(path变量应该在外部已定义好,指向存有sample_submission.csv文件的位置)下的sample_submission.csv文件,并将读取到的数据存储在sub变量中
sub = pd.read_csv(f"{path}/sample_submission.csv")
# 打印sub变量中数据的形状(即行数和列数),格式为"shape = (行数, 列数)"
print( f"shape = {sub.shape}" )
# 显示sub变量中数据的前10行,用于快速查看数据的大致结构和内容
sub.head(10)

# 创建一个空列表
col = []
# 通过循环9次,每次生成一个形如"responder_i"(i从0到8)的字符串,并将其添加到col列表中
for i in range(9):
col.append(f"responder_{i}")
# 从sample_df数据框中选取col列表中的列,对这些列进行描述性统计(如计算计数、均值、标准差、最小值、四分位数、最大值等),然后将结果保留1位小数
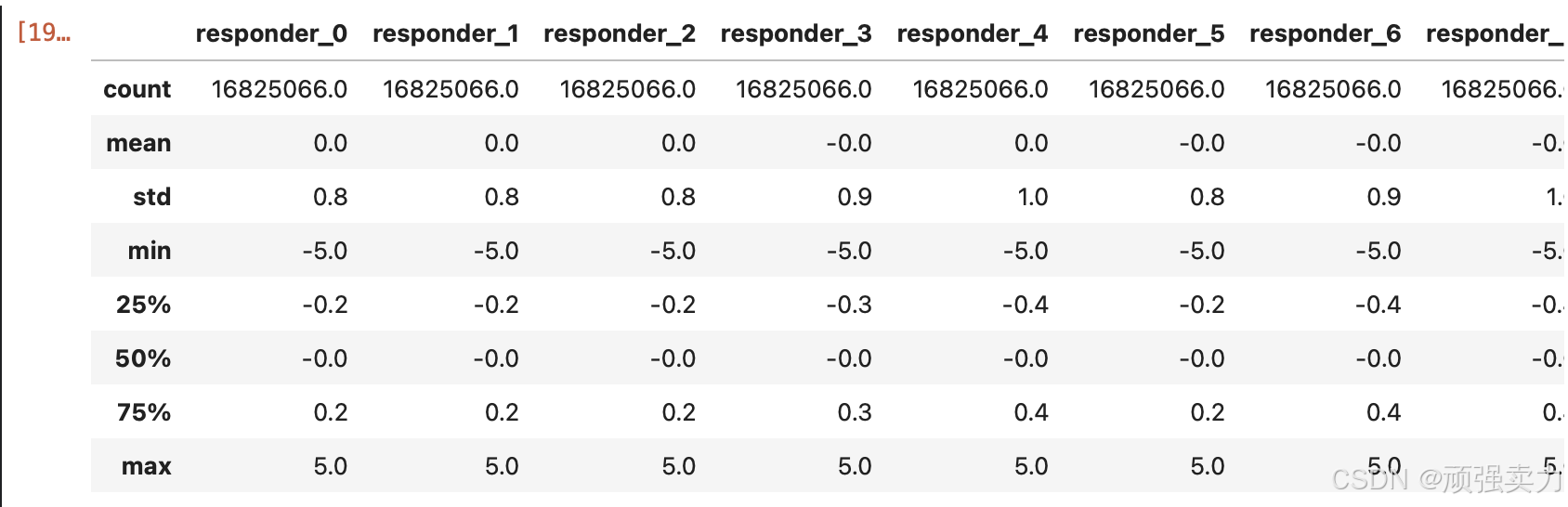
sample_df[col].describe().round(1)
# 创建一个空列表,用于存储数值型特征的列名
numerical_features = []
# 从sample_df数据框中筛选出列名以'responder_'开头的列名,并转换为列表形式,将这些列名作为数值型特征(目的是分离出响应器相关的列),然后赋值给numerical_features列表
numerical_features = sample_df.filter(regex='^responder_').columns.tolist()
# 从numerical_features列表中移除'responder_6'这一列名,因为后续可能对它特殊处理或者不想它参与当前部分的操作等
numerical_features.remove('responder_6')
# 设置六边形分箱图的网格大小为600,这里的网格大小会影响六边形分箱图的划分精细程度等显示效果
gs = 600
# 初始化一个计数器变量为1,用于后续循环中确定子图的位置等操作
k = 1
# 设置子图布局的列数为3,用于确定每行显示的子图数量
col = 3
# 设置子图布局的行数为3,用于确定一共显示几行子图
row = 3
# 创建包含多个子图的图形,设置图形的大小为宽(5乘以列数)单位、高(5乘以行数)单位,方便后续在这些子图上进行绘图展示
fig, axs = plt.subplots(row, col, figsize=(5 * col, 5 * row))
# 对numerical_features列表中的每一个列名(也就是每个响应器相关的列,除了'responder_6')进行循环操作
for i in numerical_features:
# 在图形中按照列数、行数以及当前计数器k的值确定子图位置,创建对应的子图
plt.subplot(col, row, k)
# 在当前子图上绘制六边形分箱图,以sample_df数据框中当前循环的列(i代表的列)的数据作为横坐标,以'responder_6'列的数据作为纵坐标,设置六边形分箱图的网格大小为gs(600),使用'CMRmap'颜色映射来填充六边形,设置分箱方式为对数分箱(bins='log'),并设置透明度为0.2,通过这样的六边形分箱图来展示两列数据之间的分布关系等情况
plt.hexbin(sample_df[i], sample_df['responder_6'], gridsize=gs, cmap='CMRmap', bins='log', alpha = 0.2)
# 给当前子图的横坐标添加标签,标签内容为当前循环的列名(也就是当前展示分布关系对应的另一个响应器相关列名),设置标签字体大小为12
plt.xlabel(f'{i}', fontsize = 12)
# 给当前子图的纵坐标添加标签为'responder_6',设置标签字体大小为12
plt.ylabel('responder_6', fontsize = 12)
# 设置横坐标刻度标签的字体大小为6,使刻度标签显示更合适,避免字体过大或过小影响图形美观和可读性
plt.tick_params(axis='x', labelsize=6)
# 设置纵坐标刻度标签的字体大小为6,同样是为了优化刻度标签显示效果
plt.tick_params(axis='x', labelsize=6)
# 将计数器k的值增加1,用于下一次循环确定下一个子图的位置
k = k + 1
# 设置整个图形的边框线宽为3,使图形边框更明显,起到一定装饰和区分作用
fig.patch.set_linewidth(3)
# 设置整个图形的边框颜色为黑色,指定图形边框的颜色样式
fig.patch.set_edgecolor('#000000')
# 设置整个图形的背景颜色为十六进制颜色码#eeeeee对应的浅灰色,美化图形的整体外观
fig.patch.set_facecolor('#eeeeee')
# 显示绘制好的包含多个子图的图形,呈现可视化的效果,便于直观查看不同响应器(除'responder_6'外)与'responder_6'之间的分布关系情况
plt.show()
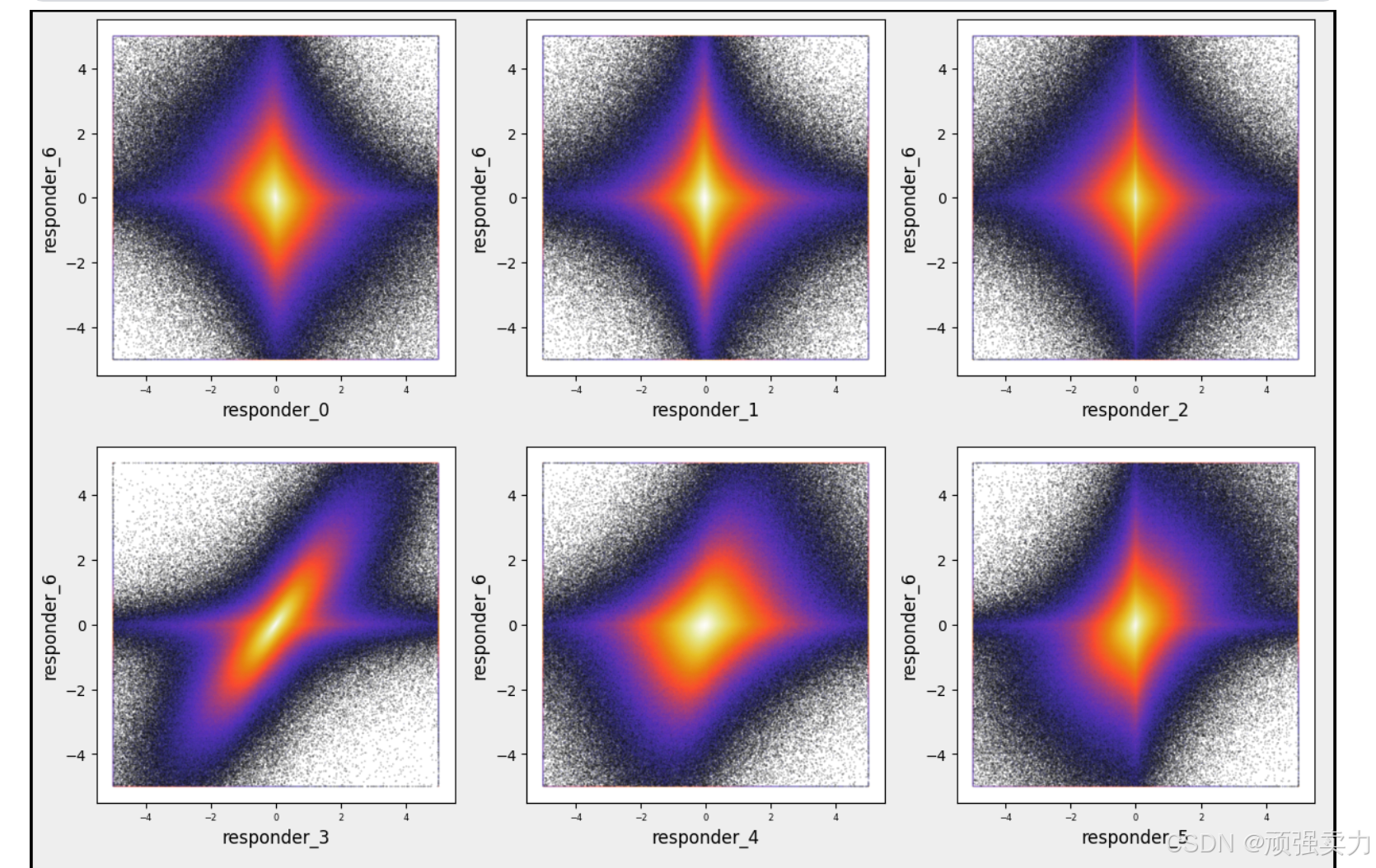
- 这种类型的图通常用于可视化多变量数据,可能是在数据分析、信号处理或机器学习领域。 “responder”
- 图中展示了不同响应者之间的关系或数据分布情况。
# 创建一个空列表,用于存放数值型特征的名称
numerical_features = []
# 通过循环,将列表['05', '06', '07', '08', '12', '15', '19', '32', '38', '39', '50', '51', '65', '66', '67']中的每个元素
# 按照'feature_{元素}'的格式生成字符串,并添加到numerical_features列表中,以此来收集特定的特征列名
for i in ['05', '06', '07', '08', '12', '15', '19', '32', '38', '39', '50', '51', '65', '66', '67']:
numerical_features.append(f'feature_{i}')
# 设置六边形分箱图的网格大小为600,这个参数会影响分箱图中六边形划分的精细程度等显示效果
gs = 600
# 初始化一个计数器变量为1,用于后续循环中确定子图的位置等操作
k = 1
# 设置子图布局的列数为3,即每行打算展示3个子图
col = 3
# 根据numerical_features列表的长度来计算子图布局需要的行数,通过向上取整确保能容纳所有子图,
# 这里是用特征数量除以3向上取整,来确定一共需要几行来展示所有子图
row = int(np.ceil(len(numerical_features) / 3))
# 设置图形展示相关的一个基础尺寸大小为5,后续的宽高尺寸会基于此和行列数进行计算
sz = 5
# 根据设置的基础尺寸和列数计算整个图形的宽度,即基础尺寸乘以列数
w = sz * col
# 根据宽度、列数和行数计算整个图形的高度,确保图形的宽高比例合适,能合理展示所有子图
h = w / col * row
# 创建一个新的图形,设置其大小为前面计算好的宽w单位、高h单位,为后续绘图做准备
plt.figure(figsize=(w, h))
# 在当前图形基础上创建包含多个子图的布局,同样设置图形大小为宽w单位、高h单位,方便后续在这些子图上进行绘图展示
fig, axs = plt.subplots(figsize=(w, h))
# 对numerical_features列表中的每一个特征列名进行循环操作
for i in numerical_features:
# 在图形中按照行数、列数以及当前计数器k的值确定子图位置,创建对应的子图
plt.subplot(row, col, k)
# 在当前子图上绘制六边形分箱图,以sample_df数据框中'responder_6'列的数据作为横坐标,以当前循环的特征列(i代表的列)的数据作为纵坐标,
# 设置六边形分箱图的网格大小为gs(600),使用'CMRmap'颜色映射来填充六边形,设置分箱方式为对数分箱(bins='log'),并设置透明度为0.3,
# 通过这样的六边形分箱图来展示'responder_6'与各特征列之间的数据分布关系等情况
plt.hexbin(sample_df['responder_6'], sample_df[i], gridsize=gs, cmap='CMRmap', bins='log', alpha = 0.3)
# 给当前子图的横坐标添加标签,标签内容为当前循环的特征列名,用于表明横坐标对应的是什么数据
plt.xlabel(f'{i}')
# 给当前子图的纵坐标添加标签为'responder_6',表明纵坐标对应的是'responder_6'列的数据
plt.ylabel('responder_6')
# 设置横坐标刻度标签的字体大小为6,使刻度标签显示更合适,避免字体过大或过小影响图形美观和可读性
plt.tick_params(axis='x', labelsize=6)
# 设置纵坐标刻度标签的字体大小为6,同样是为了优化刻度标签显示效果
plt.tick_params(axis='y', labelsize=6)
# 将计数器k的值增加1,用于下一次循环确定下一个子图的位置
k = k + 1
# 设置整个图形的边框线宽为3,使图形边框更明显,起到一定装饰和区分作用
fig.patch.set_linewidth(3)
# 设置整个图形的边框颜色为黑色,指定图形边框的颜色样式
fig.patch.set_edgecolor('#000000')
# 设置整个图形的背景颜色为十六进制颜色码#eeeeee对应的浅灰色,美化图形的整体外观
fig.patch.set_facecolor('#eeeeee')
# 显示绘制好的包含多个子图的图形,呈现可视化的效果,便于直观查看'responder_6'与各选定特征之间的分布关系情况
plt.show()
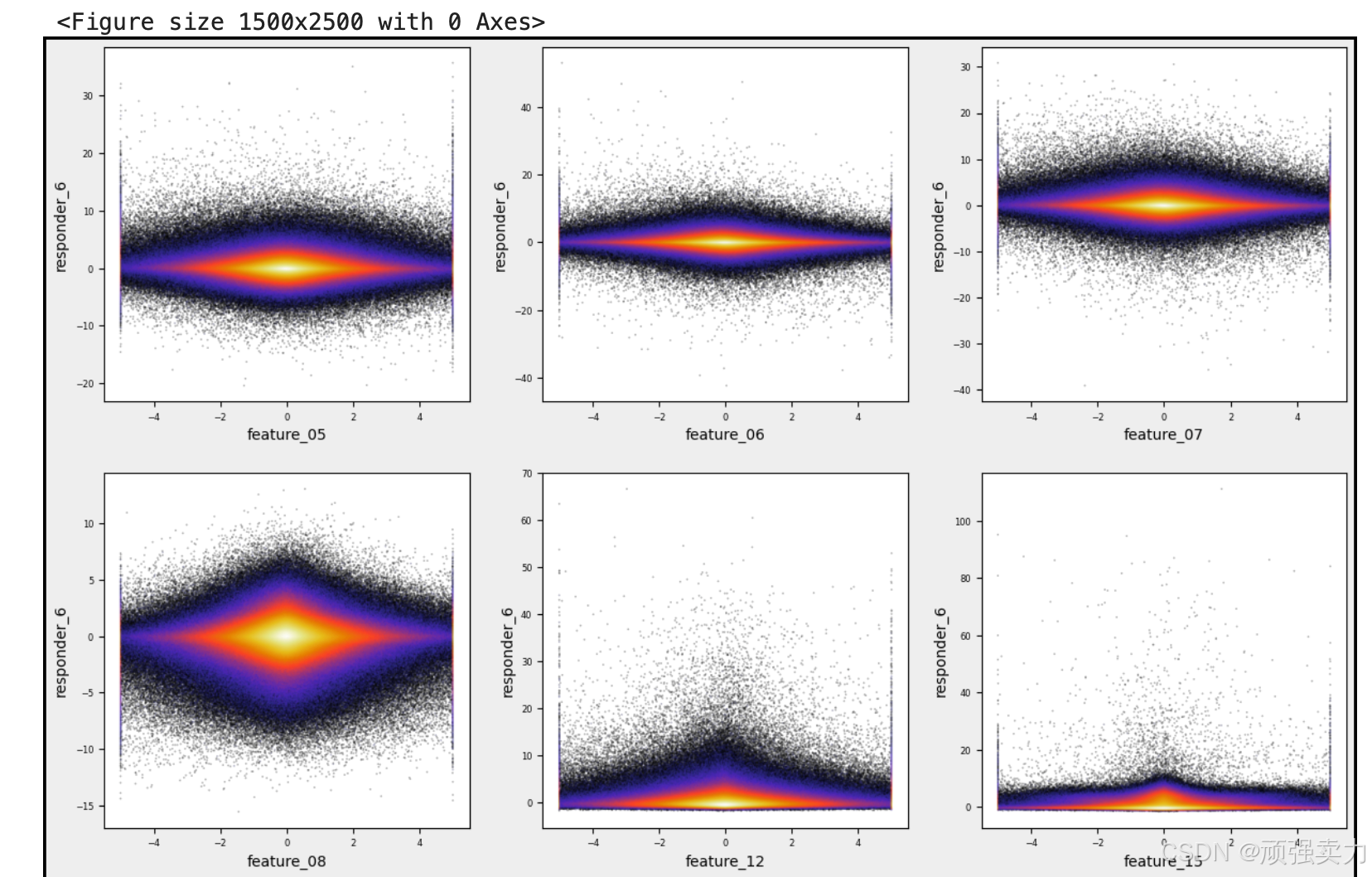
# 创建一个空列表,用于存放数值型特征的名称
numerical_features = []
# 通过循环,生成以'feature_0'开头且后面数字从5到8的特征名称字符串,并添加到numerical_features列表中
for i in range(5, 9):
numerical_features.append(f'feature_0{i}')
# 通过循环,生成以'feature_'开头且后面数字从15到19的特征名称字符串,并添加到numerical_features列表中
for i in range(15, 20):
numerical_features.append(f'feature_{i}')
# 初始化两个变量,a用于记录循环的位置,初始化为0;k用于确定子图的位置,初始化为1
a = 0
k = 1
# 设置每行显示的子图数量为3,用于后续子图布局的规划
n = 3
# 创建包含多个子图的图形,设置图形大小为宽15单位、高4单位,为后续绘图做准备
fig, axs = plt.subplots(figsize=(15, 4))
# 对numerical_features列表中除最后一个元素之外的每个特征名称进行循环(外层循环)
for i in numerical_features[:-1]:
# 每次循环将a的值增加1,用于标记当前外层循环所处的位置,后续内层循环会从这个位置往后开始
a = a + 1
# 内层循环,从当前外层循环对应的位置a开始,遍历剩余的特征名称,目的是两两组合进行操作
for j in numerical_features[a:]:
# 根据设定的每行子图数量n以及当前计数器k的值确定子图位置,创建对应的子图
plt.subplot(1, n, k)
# 在当前子图上绘制六边形分箱图,以sample_df数据框中当前外层循环的特征列(i代表的列)的数据作为横坐标,
# 以内层循环的特征列(j代表的列)的数据作为纵坐标,设置六边形分箱图的网格大小为200,使用'CMRmap'颜色映射来填充六边形,
# 设置分箱方式为对数分箱(bins='log'),并设置透明度为1,通过这样的六边形分箱图来展示两个特征列之间的数据分布关系等情况
plt.hexbin(sample_df[i], sample_df[j], gridsize=200, cmap='CMRmap', bins='log', alpha = 1)
# 在当前子图上添加网格线,使图形看起来更清晰,便于查看数据分布情况
plt.grid()
# 给当前子图的横坐标添加标签,标签内容为当前外层循环的特征列名(i代表的列),设置标签字体大小为14
plt.xlabel(f'{i}', fontsize = 14)
# 给当前子图的纵坐标添加标签,标签内容为当前内层循环的特征列名(j代表的列),设置标签字体大小为14
plt.ylabel(f'{j}', fontsize = 14)
# 设置横坐标刻度标签的字体大小为6,使刻度标签显示更合适,避免字体过大或过小影响图形美观和可读性
plt.tick_params(axis='x', labelsize=6)
# 设置纵坐标刻度标签的字体大小为6,同样是为了优化刻度标签显示效果
plt.tick_params(axis='y', labelsize=6)
# 将计数器k的值增加1,用于下一次循环确定下一个子图的位置
k = k + 1
# 当计数器k的值等于每行子图数量n加1时(意味着当前行的子图绘制完了)
if k == (n + 1):
# 将计数器k重置为1,用于下一行子图的绘制时确定子图位置
k = 1
# 显示当前已经绘制好的一行子图,呈现可视化的效果
plt.show()
# 创建一个新的图形,同样设置图形大小为宽15单位、高4单位,用于继续绘制下一行的子图
plt.figure(figsize=(15, 4))
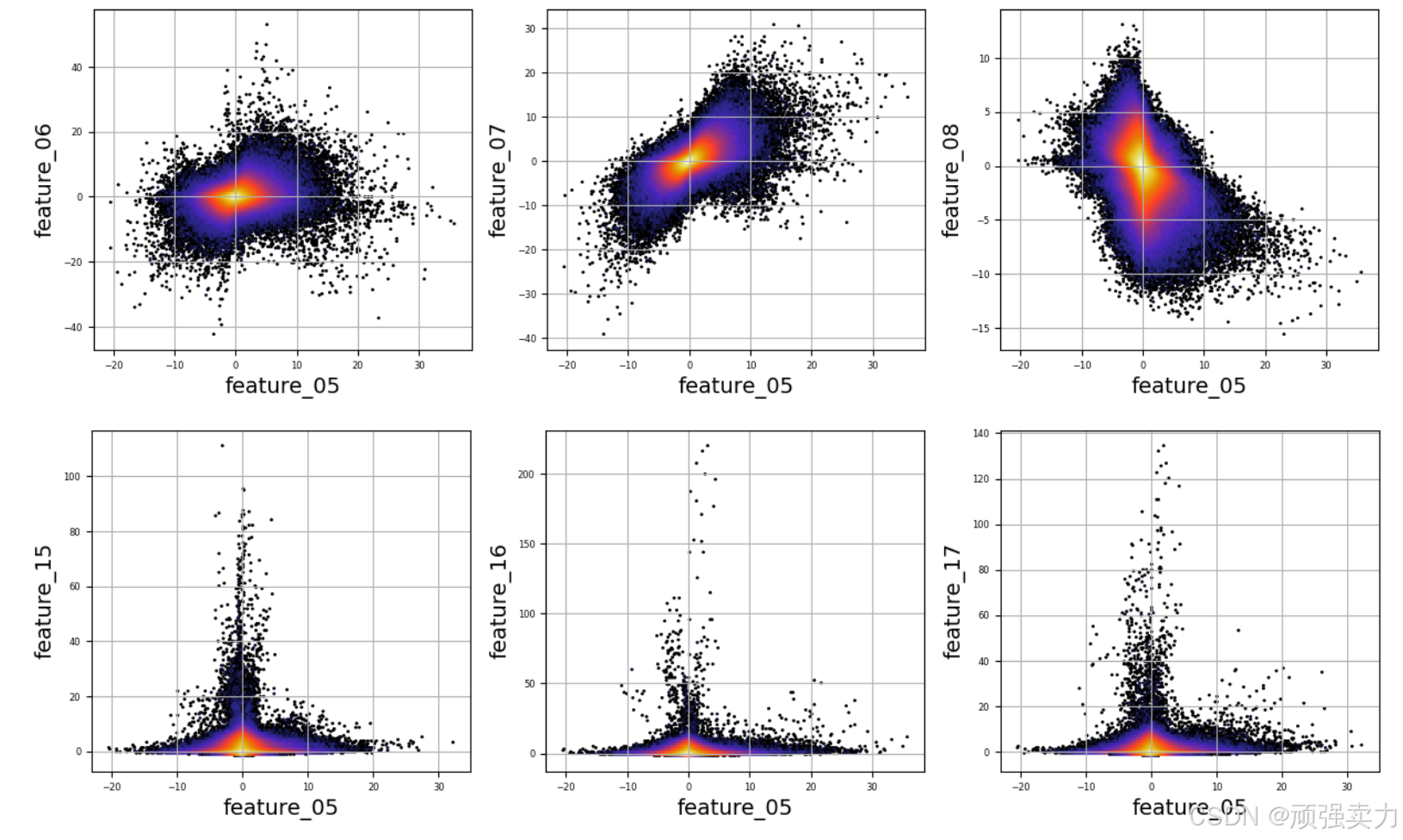
# 创建一个列表,其中包含两个字符串元素'SOLUTION_14'和'SOLUTION_5',这个列表可能用于存储集成解决方案相关的名称或者标识等,具体取决于后续代码逻辑
ENSEMBLE_SOLUTIONS = ['SOLUTION_14', 'SOLUTION_5']
# 定义两个变量,OPTION变量赋值为字符串'option 91',__WTS变量赋值为一个包含两个浮点数0.899和0.28的列表,这两个变量可能在后续涉及到某种选项配置以及权重设置相关的操作中使用,同样具体作用取决于整体代码上下文
OPTION, __WTS = 'option 91', [0.899, 0.28]
# 定义一个名为predict的函数,该函数接收两个参数,test参数要求是一个Polars的DataFrame类型的数据,lags参数可以是Polars的DataFrame类型或者为None(即可以不传该参数),函数最终返回值可以是Polars的DataFrame类型或者是pandas的DataFrame类型
def predict(test: pl.DataFrame, lags: pl.DataFrame | None) -> pl.DataFrame | pd.DataFrame:
# 调用名为predict_14的函数(应该是在外部已定义好的函数),传入test和lags参数,得到的结果调用to_pandas方法转换为pandas的DataFrame类型,并赋值给pdB变量
pdB = predict_14(test, lags).to_pandas()
# 调用名为predict_5的函数(同样应该是外部定义好的函数),传入test和lags参数,得到的结果调用to_pandas方法转换为pandas的DataFrame类型,并赋值给pdC变量
pdC = predict_5(test, lags).to_pandas()
# 对pdB这个pandas的DataFrame进行列名重命名操作,将原来名为'responder_6'的列名修改为'responder_B'
pdB = pdB.rename(columns={'responder_6': 'responder_B'})
# 对pdC这个pandas的DataFrame进行列名重命名操作,将原来名为'responder_6'的列名修改为'responder_C'
pdC = pdC.rename(columns={'responder_6': 'responder_C'})
# 使用pandas的merge函数,按照['row_id']列进行合并操作,将pdB和pdC这两个DataFrame合并成一个新的DataFrame,并赋值给pds变量
pds = pd.merge(pdB, pdC, on=['row_id'])
# 在pds这个DataFrame中新增一列'responder_6',其值通过将'responder_B'列的值乘以__WTS列表中的第一个元素(前面代码中定义的权重列表中的第一个权重值),再加上'responder_C'列的值乘以__WTS列表中的第二个元素(第二个权重值)来计算得到
pds['responder_6'] = \
pds['responder_B'] * __WTS[0] + \
pds['responder_C'] * __WTS[1]
# 调用display函数(可能是用于展示数据的,比如在一些交互式环境中展示DataFrame的内容)展示pds这个DataFrame的数据内容
display(pds)
# 从test这个Polars的DataFrame中选择'row_id'列以及新增一个名为'responder_6'且值全为0.0的列(通过pl.lit(0.0).alias('responder_6')创建这个新列),并将结果赋值给predictions变量,此时的'responder_6'列的值后续应该是要被替换掉的
predictions = test.select('row_id', pl.lit(0.0).alias('responder_6'))
# 将pds这个DataFrame中'responder_6'列的数据转换为numpy数组,并赋值给pred变量
pred = pds['responder_6'].to_numpy()
# 在predictions这个Polars的DataFrame上进行列操作,使用with_columns方法将前面得到的pred数组(转换为一维的形式,通过ravel方法)作为数据创建一个名为'responder_6'的新列,替换掉原来值全为0.0的'responder_6'列
predictions = predictions.with_columns(pl.Series('responder_6', pred.ravel()))
# 返回最终处理好的predictions这个Polars的DataFrame作为函数的返回结果
return predictions
模型训练
import pandas as pd
import polars as pl # 导入polars库,用于数据处理,它是一个高性能的数据框库,类似pandas
import numpy as np # 导入numpy库,用于数值计算,提供了多维数组等数据结构及相关操作函数
import os # 导入os库,用于操作系统相关的操作,比如文件和目录操作等
from glob import glob # 从glob模块中导入glob函数,常用于文件路径的通配符匹配查找文件
%matplotlib inline # 在Jupyter Notebook等环境中,设置matplotlib绘图以内联方式显示,绘图结果直接展示在代码单元格下方
import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块,用于绘制各种类型的图表
import seaborn as sns # 导入seaborn库,它基于matplotlib进行了更高层次的封装,方便绘制更美观、更专业的数据可视化图形
import time # 导入time库,用于处理时间相关的操作,比如计时等
from sklearn.model_selection import train_test_split # 从sklearn的model_selection模块中导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.metrics import confusion_matrix, classification_report, roc_curve,auc, roc_auc_score, r2_score
# 从sklearn的metrics模块中导入多个评估指标相关的函数,
# confusion_matrix用于计算混淆矩阵,classification_report用于生成分类报告,
# roc_curve用于绘制ROC曲线,auc用于计算曲线下面积,roc_auc_score用于计算ROC AUC分数,r2_score用于计算回归模型的决定系数
from sklearn.linear_model import ElasticNet # 从sklearn的linear_model模块中导入ElasticNet类,它是一种线性回归模型,带有L1和L2正则化
from xgboost import XGBRegressor # 导入xgboost库中的XGBRegressor类,用于构建XGBoost回归模型
from lightgbm import LGBMRegressor # 导入lightgbm库中的LGBMRegressor类,用于构建LightGBM回归模型
class CNG:
"""
定义了一个名为CNG的类,从代码结构推测这个类可能用于处理与特定数据集路径相关的操作,
"""
train_path = "/kaggle/input/jane-street-real-time-market-data-forecasting/train.parquet"
"""
类属性train_path,定义了训练数据集的文件路径,数据格式为parquet。
这里路径指向的应该是存放训练数据的具体位置,路径中的 'jane-street-real-time-market-data-forecasting'
"""
test_path = "/kaggle/input/jane-street-real-time-market-data-forecasting/test.parquet"
"""
类属性test_path,定义了测试数据集的文件路径,同样是parquet格式。
该路径用于定位测试数据所在的位置,方便后续代码从该位置读取测试数据进行相应的模型测试等操作。
"""
lagged_path = "/kaggle/input/jane-street-real-time-market-data-forecasting/lags.parquet"
"""
类属性lagged_path,定义了一个名为'lags.parquet'文件的路径,从文件名推测可能是包含滞后相关数据的数据集,
同样为后续读取该数据做准备,方便在数据分析或者模型构建等过程中使用这些带有滞后特征的数据。
"""
responders_path = "/kaggle/input/jane-street-real-time-market-data-forecasting/responders.csv"
"""
类属性responders_path,指定了一个CSV格式文件的路径,文件名'responders.csv'暗示该文件可能包含了与响应者相关的数据信息,
比如不同响应主体对应的一些属性等,后续可通过该路径读取相应的数据进行处理。
"""
features_path = "/kaggle/input/jane-street-real-time-market-data-forecasting/features.csv"
"""
类属性features_path,设定了另一个CSV格式文件的路径,此文件名为'features.csv',大概率存放了各种特征数据,
这些特征数据可能会在数据分析、特征工程以及构建预测模型等操作中被使用。
"""
def parquet_sorting(path):
"""
定义一个名为parquet_sorting的函数,其功能是对给定的Parquet文件路径进行解析,
提取出特定的标识信息用于后续的排序或比较等操作。
参数:
- path:表示Parquet文件的路径,类型应为字符串,格式需要符合函数内解析逻辑所预期的形式。
"""
parts = path.split('/')
"""
将传入的文件路径(以'/'作为分隔符)进行分割,得到一个包含路径各部分的列表。
例如路径 "/a/b/c=123/file-456.parquet" 经过分割后,parts 列表会包含 ["", "a", "b", "c=123", "file-456.parquet"] 这样的元素。
"""
partition_id = int(parts[-2].split('=')[1])
"""
取分割后的列表中倒数第二个元素(假设路径格式符合预期,该元素包含分区相关的标识信息),
再以'='作为分隔符进行分割,取分割后的第二个元素(索引为1),并将其转换为整数类型,
这个整数就代表了分区的标识(partition_id)。例如对于 "c=123",经过处理后 partition_id 会得到 123。
"""
parquet_num = int(parts[-1].split('-')[1].split('.')[0])
"""
取分割后的列表中最后一个元素(即文件名部分,假设文件名格式符合预期),
先以'-'作为分隔符进行分割,取分割后的第二个元素,然后再以'.'作为分隔符分割该元素,取其第一个部分(索引为0),
最后将其转换为整数类型,这个整数代表了Parquet文件的编号(parquet_num)。
例如对于文件名 "file-456.parquet",经过处理后 parquet_num 会得到 456。
"""
return (partition_id, parquet_num)
"""
将提取并转换后的分区标识(partition_id)和Parquet文件编号(parquet_num)组成一个元组并返回,
这样外部调用该函数时就能获取到这两个用于排序或比较等操作的关键信息。
"""
以上就是本次案例部分内容,如果大家感兴趣,可以在公主号【海水三千】对完整案例进行学习,会提供完整的项目代码以及数据。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











