






你是否对数据科学和机器学习充满好奇,却苦于找不到合适的实战机会?
你是否想提升自己的编程和建模能力,却不知道从哪里开始?
如果你有这些困惑,那么Kaggle就是你最好的选择!作为全球最大的数据科学竞赛平台,Kaggle不仅为你提供了海量的数据集和真实的业务场景,还能让你与全球顶尖的数据科学家同台竞技,快速提升自己的技能。
为什么要参加Kaggle比赛?
1.实战是最好的学习方式
很多人在学习数据科学时,往往停留在理论层面,缺乏实际项目的锻炼。而Kaggle比赛提供了真实的数据集和明确的目标,让你能够将所学知识应用到实际问题中。通过比赛,你可以深入理解数据清洗、特征工程、模型训练和调优的完整流程,真正掌握数据科学的精髓。
2.提升编程和建模能力
Kaggle比赛通常涉及大量的数据处理和模型构建工作,这要求你熟练掌握Python、Pandas、NumPy、Scikit-learn等工具和库。通过不断参与比赛,你的编程能力和建模水平会得到显著提升。此外,你还能学习到许多高级技巧,比如集成学习、深度学习、自动化调参等。
3.积累项目经验,丰富简历
对于求职者来说,Kaggle比赛经历是一个巨大的加分项。很多公司在招聘数据科学家或机器学习工程师时,都会特别关注候选人的Kaggle排名和项目经验。即使你没有拿到很高的名次,参与比赛并提交解决方案的过程本身就能体现你的学习能力和实战经验。
4.与全球高手过招,开阔视野
Kaggle聚集了来自世界各地的数据科学家和机器学习爱好者。通过参与比赛,你可以学习到其他选手的解题思路和技巧,甚至可以直接查看他们的公开代码(Kernels)。这种开放的学习环境能够帮助你快速成长,开阔视野。
5.赢取奖金和荣誉
Kaggle的许多比赛都设有丰厚的奖金,尤其是“Featured”类别的比赛,奖金通常高达数万美元。即使你没有拿到奖金,获得较高的排名也能为你赢得荣誉和认可,甚至可能收到来自企业的橄榄枝。
今天,我们就从注册开始,一步步带你走进Kaggle的世界,手把手教你如何参加比赛、编写代码、提交结果,并最终查询成绩。
一、注册Kaggle账号
1.1 访问Kaggle官网
首先,打开浏览器,输入Kaggle的官网地址:https://www.kaggle.com。如果你还没有账号,点击右上角的“Register”按钮进行注册。
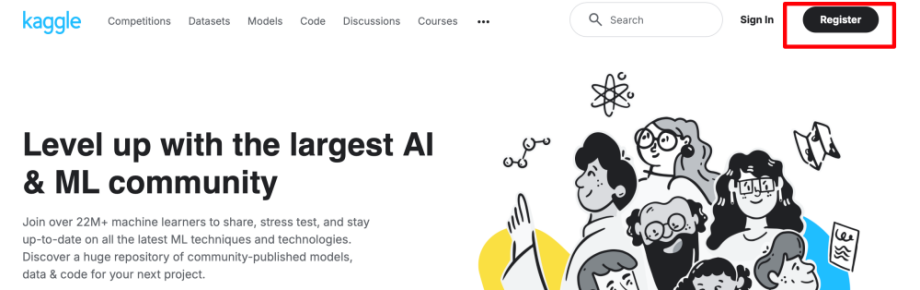
1.2 填写注册信息
Kaggle支持通过Google账号、Facebook账号或邮箱注册。推荐使用Google账号,方便后续的代码提交和社区互动。注册时需要填写用户名、密码等信息,确保记住你的登录凭证。
1.3 验证邮箱
注册完成后,Kaggle会发送一封验证邮件到你的注册邮箱。点击邮件中的链接完成邮箱验证,这样你就可以正式使用Kaggle了。
二、选择并参加比赛
2.1 浏览比赛列表
登录Kaggle后,点击导航栏中的“Competitions”选项,你会看到当前正在进行的比赛列表。Kaggle的比赛种类繁多,从入门级的“Getting Started”到高级的“Featured”比赛,应有尽有。
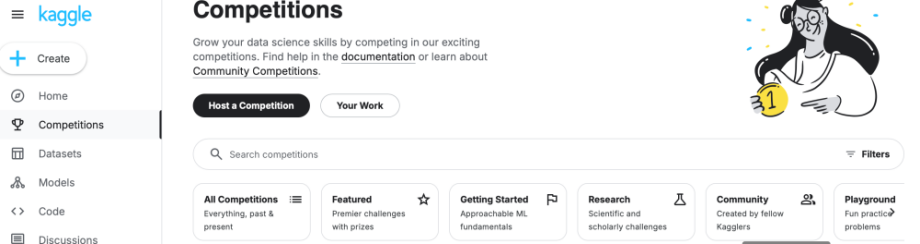
2.2 选择适合新手的比赛
对于新手来说,建议从“Getting Started”类别的比赛开始。这类比赛通常有详细的教程和简单的数据集,适合初学者练手。点击比赛名称进入比赛详情页,阅读比赛说明、数据集介绍和评估标准。
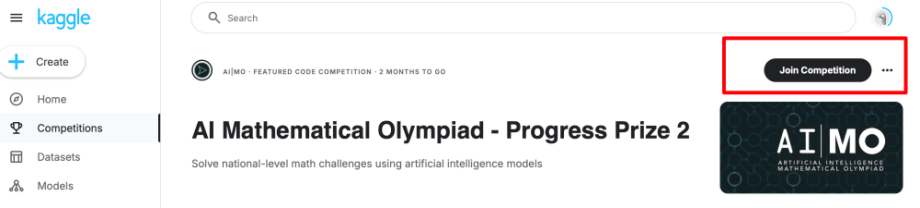
2.3 加入比赛
在比赛详情页的右侧,点击“Join Competition”按钮,确认加入比赛。加入后,你就可以下载数据集、提交代码和查看排行榜了。
三、下载数据集并配置环境
3.1 下载数据集
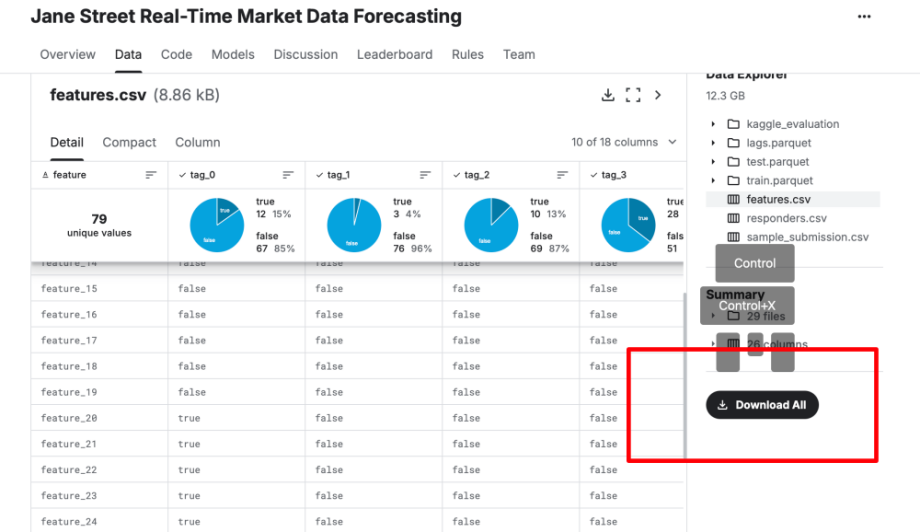
在比赛详情页的“Data”选项卡中,你可以找到比赛所需的数据集。点击“Download All”按钮,将数据集下载到本地。数据集通常以CSV格式提供,包含训练集和测试集。
3.2 配置Python环境
Kaggle比赛通常使用Python进行数据处理和模型训练。如果你还没有安装Python,可以从Python官网下载并安装最新版本。推荐使用Anaconda来管理Python环境,它集成了常用的数据科学库,如NumPy、Pandas、Scikit-learn等。
3.3 安装第三方库
在开始编写代码之前,你可能需要安装一些第三方库。常见的库包括:
1️⃣Pandas:用于数据处理和分析。
2️⃣NumPy:用于数值计算。
3️⃣Scikit-learn:用于机器学习模型的构建和评估。
4️⃣XGBoost/LightGBM:用于高效的梯度提升算法。
你可以通过以下命令安装这些库:
pip install pandas numpy scikit-learn xgboost lightgbm
四、编写代码并训练模型
4.1 导入必要的库
在编写代码之前,首先导入所需的Python库。以下是一个常见的导入示例:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
4.2 加载数据集
使用Pandas加载下载的数据集:
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
4.3 数据预处理
数据预处理是机器学习中非常重要的一步。常见的预处理操作包括处理缺失值、特征编码、数据标准化等。以下是一个简单的预处理示例:
处理缺失值
train_data.fillna(0, inplace=True)
test_data.fillna(0, inplace=True)
将分类变量转换为数值变量
train_data = pd.get_dummies(train_data)
test_data = pd.get_dummies(test_data)
4.4 划分训练集和验证集
为了评估模型的性能,通常会将训练集划分为训练集和验证集:
X = train_data.drop('target', axis=1)
y = train_data['target']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
4.5 训练模型
选择一个简单的模型进行训练,例如随机森林:
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
4.6 验证模型
使用验证集评估模型的性能:
y_pred = model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
print(f'Validation Accuracy: {accuracy:.4f}')
五、提交比赛结果
5.1 生成预测结果
在训练好模型后,使用测试集生成预测结果:
test_pred = model.predict(test_data)
5.2 保存提交文件
Kaggle要求提交的文件格式通常为CSV,包含两列:ID和预测结果。以下是一个保存提交文件的示例:
submission = pd.DataFrame({'Id': test_data['Id'], 'Predicted': test_pred})
submission.to_csv('submission.csv', index=False)
5.3 提交结果
回到Kaggle比赛页面,点击“Submit Predictions”按钮,上传你生成的submission.csv文件。提交后,Kaggle会自动计算你的模型在测试集上的得分,并更新你的排行榜排名。
六、比赛过程中的代码修改与优化
6.1 分析模型表现
如果你的模型表现不佳,可以通过分析验证集的表现来找出问题。常见的改进方法包括:
1️⃣调整模型超参数。
2️⃣增加更多的特征工程。
3️⃣尝试不同的模型算法。
6.2 使用交叉验证
为了更稳定地评估模型性能,可以使用交叉验证(Cross-Validation):
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)
print(f'Cross-Validation Accuracy: {np.mean(scores):.4f}')
6.3 集成学习
集成学习(Ensemble Learning)是提高模型性能的有效方法。你可以尝试将多个模型的预测结果进行组合:
from sklearn.ensemble import VotingClassifier
model1 = RandomForestClassifier(n_estimators=100, random_state=42)
model2 = XGBClassifier()
ensemble_model = VotingClassifier(estimators=[('rf', model1), ('xgb', model2)], voting='soft')
ensemble_model.fit(X_train, y_train)
七、查询比赛成绩
7.1 查看排行榜
在比赛页面,点击“Leaderboard”选项卡,你可以看到所有参赛者的排名和得分。你的成绩会根据提交的结果实时更新。
7.2 分析成绩
如果你的成绩不理想,可以尝试分析其他高分选手的公开代码(Kernels),学习他们的思路和方法。Kaggle社区非常开放,很多选手会分享他们的解决方案。
八、总结
通过以上步骤,相信你已经掌握了如何从零开始参加Kaggle比赛。Kaggle不仅是一个竞赛平台,更是一个学习和成长的好地方。无论你是数据科学的新手,还是有一定经验的从业者,Kaggle都能为你提供丰富的资源和挑战。
如果你对数据科学和机器学习感兴趣,欢迎关注我的V❤公主号【海水三千】,我会定期分享更多实用的教程和技巧,帮助你快速提升技能!


















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











