









在监控到主库故障之后,standby节点会进行主库的选举切换流程
核心的函数为
do_primary_failover(void)
election_result = do_election(&sibling_nodes, &new_primary_id);
首先看下如何选出新主
选主流程
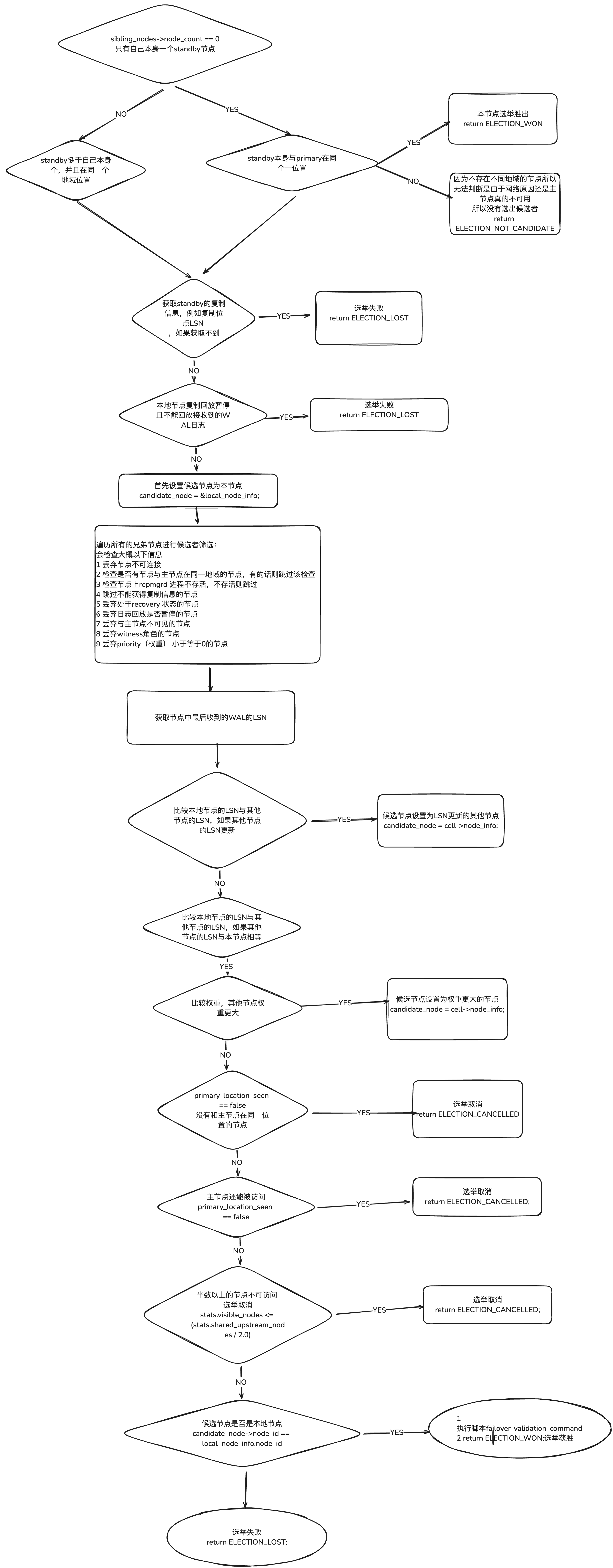
本地的standby 节点 的 选举结果有以下情况
typedef enum
{
ELECTION_NOT_CANDIDATE = -1,// 选举没有候选者
ELECTION_WON, // 选举获胜
ELECTION_LOST, // 选举失败
ELECTION_CANCELLED, // 选举取消
ELECTION_RERUN // 选举重跑
} ElectionResult;选主流程
如果本地节点配置了 切换方式 为 FAILOVER_MANUAL(手动切换) ,return ELECTION_NOT_CANDIDATE;
如果本地节点配置了 权重小于等于 0 ,则该节点不会成为主节点的候选者, return ELECTION_LOST;
获取和主节点连接的所有的活跃的兄弟节点 ,除了本地节点本身
判断上游节点的位置与本地节点的位置是否相同 ,后面只做了打印日志的处理
如果没有其他备用(或见证)节点存在,则走快速路径
如果没有其他备用(或见证)节点存在 ,且和主节点的位置相同 ,- 通常默认本地节点获胜,return ELECTION_WON;
如果和主节点的位置不同 ,return ELECTION_NOT_CANDIDATE;
获取本地节点的LSN信息
如果本地节点设置了 WAL 日志回放暂停 ,return ELECTION_LOST;
指向'获胜'节点的指针,初始化的时候指向自身
遍历所有的兄弟节点进行候选者筛选,会检查大概以下信息
-
1 丢弃节点不可连接
-
2 检查是否有节点与主节点在同一地域的节点,有的话则跳过该检查
-
3 检查节点上repmgrd 进程不存活,不存活则跳过
-
4 跳过不能获得复制信息的节点
-
5 丢弃处于recovery 状态的节点
-
6 丢弃日志回放是否暂停的节点
-
7 丢弃与主节点不可见的节点
-
8 丢弃witness角色的节点
-
9 丢弃priority(权重) 小于等于0的节点
比较LSN
比较权重
比较node id
如果没有和主节点在同一位置的节点 ,全局取消 return ELECTION_CANCELLED;
如果主节点还能被访问 ,选举取消 return ELECTION_CANCELLED;
半数以上的节点不可访问 选举取消 return ELECTION_CANCELLED;
候选节点 和 本地节点相同 ,选举状态 获胜 return ELECTION_WON;
注意
问题1 :源码中如何防止 网络脑裂 ?
如果主服务器和备用服务器设置了不同的位置,那么假设我们不应该采取任何行动,因为我们无法判断是否存在网络中断。
通常,主服务器和备用服务器位于不同物理位置的情况,会通过将位置保留为“默认”并在主服务器的位置设置见证服务器来处理。
与主节点在相同位置 或 相同网络环境的节点大于等于1个 ,防止由于是网络中断,网络孤岛 导致的网络脑裂。
另外 这里表明 如果没有与主节点处于相同地域的节点且该节点还能被其他节点访问 ,选举不会成功。
问题2 : 源码中如何避免在选举中 出现架构上的双主 ?
虽然运行在standby 的repmgrd 进程是分别独立 进行主库选举,
首先 会对后选者进行一些系列的筛选,丢弃不复合要求的 standby 候选者
然后 各个standby的选举规则相同,另外node id 是不可重复的整数,即使所有的比较项都相同,也会选择出node id 较小的。
问题3 :没有选举胜出但是还存活的standby, 是如何感知到胜出的新主节点 ,并follow的 ?
standby 会根据选举结果 等待新主提升。
问题4 : 如何避免在选举切换过程中 ,数据丢失 ?
1 在源码中 第一就会比较所有符合条件standby的LSN,选出具有最新日志的standby节点。
2 通过Postgresql中的同步流复制 ,通过 synchronous_commit (enum) 与 参数 synchronous_standby_names (string) 共同控制
3 同时结合 业务方 可用性优先 还是 数据库一致性优先 ,设置数据同步到standby的级别。
以下是同步级别以及WAL同步行为,
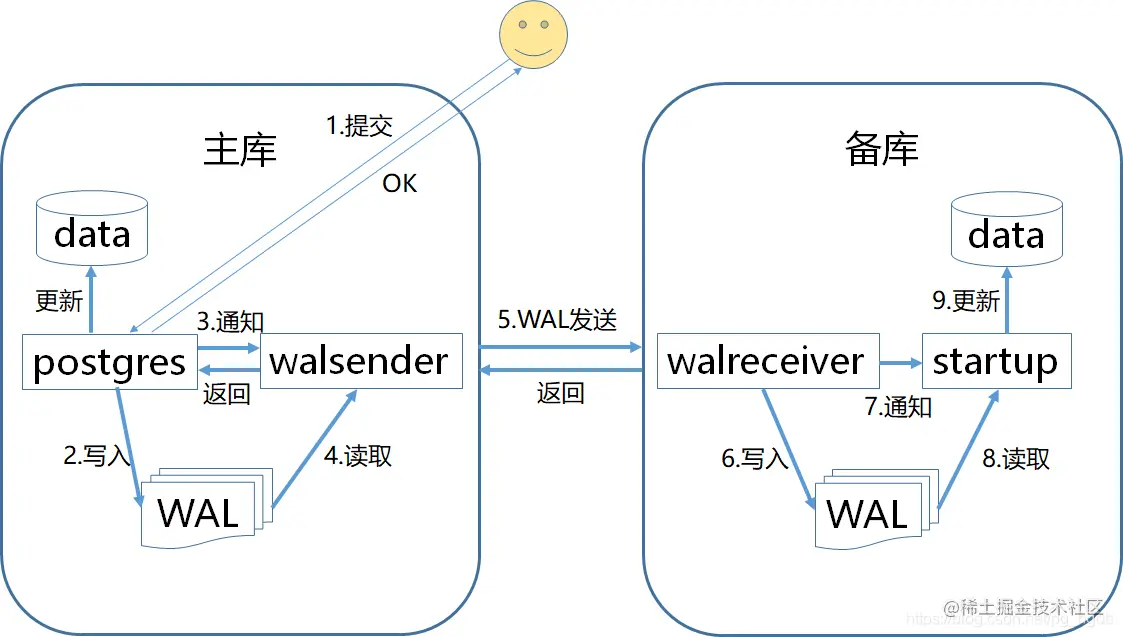
| 同步等级 | 设定值 | 概述 | 保证范围 |
|---|---|---|---|
| 同步 | remote_apply | 应用发起提交后,等到在备库上应用WAL(更新数据)后,它将返回COMMIT响应,并且可以在备库上进行引用。由于完全保证了数据同步,因此它适合需要备库始终保持最新数据的负载分配场景。 | 1-9 |
| 同步 | on(默认) | 应用发起提交后,在备库上写入WAL之后,返回COMMIT响应。该选项是性能和可靠性之间的最佳平衡。 | 1-6 |
| 准同步的 | remote_write | 应用发起提交后,等到WAL已传输到备库后,返回COMMIT响应。 | 1-5 |
| 异步 | local | 应用发起提交后,写入主库WAL之后,返回COMMIT响应。 | 1-2 |
| 异步 | off | 应用发起提交后,直接返回COMMIT响应,而无需等待主库WAL完成写入。 | 1 |
官网相关参数 :
synchronous_commit (enum)
指定在命令返回“success”指示给客户端之前,一个事务是否需要等待 WAL 记录被写入磁盘。合法的值是on、remote_apply、remote_write、local和off。默认的并且安全的设置是on。当设置为off时,在向客户端报告成功和真正保证事务不会被服务器崩溃威胁之间会有延迟(最大的延迟是wal_writer_delay的三倍)。不同于fsync,将这个参数设置为off不会产生数据库不一致性的风险:一个操作系统或数据库崩溃可能会造成一些最近据说已提交的事务丢失,但数据库状态是一致的,就像这些事务已经被干净地中止。因此,当性能比完全确保事务的持久性更重要时,关闭synchronous_commit可以作为一个有效的代替手段。更多讨论见第 29.3 节。
如果synchronous_standby_names为非空,这个参数也控制事务提交是否将等待它们的 WAL 记录被复制到后备服务器上。当这个参数被设置为on时,直到来自于当前同步的后备服务器的回复指示它们已经收到了事务的提交记录并将其刷入了磁盘,主服务器上的事务才会提交。这保证事务将不会被丢失,除非主服务器和所有同步后备都遭受到了数据库存储损坏的问题。当被设置为remote_apply时,提交将会等待,直到来自当前的同步后备的回复指示它们已经收到了该事务的提交记录并且已经应用了该事务,这样该事务才变得对后备上的查询可见。当这个参数被设置为remote_write时,提交将等待,直到来自当前的同步后备的回复指示它们已经收到了该事务的提交记录并且已经把该记录写出到它们的操作系统,这种设置足以保证数据在后备服务器的PostgreSQL实例崩溃时得以保存,但是不能保证后备服务器遭受操作系统级别崩溃时数据能被保持,因为数据不一定必须要在后备机上达到稳定存储。最后,设置local会导致提交等待本地刷写到磁盘而不是复制完成。在使用同步复制时这通常不是我们想要的效果,但是为了完整性,还是提供了这样一个选项。
如果synchronous_standby_names为空,设置on、remote_apply、remote_write和local都提供了同样的同步级别:事务提交只等待本地刷写磁盘。
这个参数可以随时被修改;任何一个事务的行为由其提交时生效的设置决定。因此,可以同步提交一些事务,同时异步提交其他事务。例如,当默认是相反时,实现一个单一多语句事务的异步提交,在事务中发出SET LOCAL synchronous_commit TO OFF。
synchronous_standby_names (string)
如第 26.2.8 节所述,这个参数指定一个支持同步复制的后备服务器的列表。可能会有一个或者多个活动的同步后备服务器,在这些后备服务器确认收到它们的数据之后,等待提交的事务将被允许继续下去。同步后备服务器是那些名字出现在这个列表前面,并且当前已连接并且正在实时流传输数据(如pg_stat_replication视图中streaming的状态所示)的服务器。指定多于一台同步后备可以得到非常高的可用性并且能防止数据丢失。
用于这一目的的后备服务器的名称是其application_name设置,它在后备服务器的连接信息中设置。 在物理复制后备的情况下,这应该被设置在primary_conninfo设置中,如果设置了,默认是cluster_name的设置,否则为 walreceiver。 对于逻辑复制,可以在订阅的连接信息中设置。对于其他复制流消费者,请参考其文档。
这个参数使用下面的语法之一来指定一个后备服务器列表:
num_sync其中num_sync是事务需要等待其回复的同步后备服务器的数量,standby_name是一个后备服务器的名称。FIRST以及ANY指定从所列服务器中选取同步后备的方法。
关键词FIRST加上num_sync指定一种基于优先的同步复制,并且会让事务提交等待,直到它们的WAL记录被复制到基于优先级选择的num_sync台同步后备上为止。例如,设置FIRST 3 (s1, s2, s3, s4)将导致每次提交都等待来自三台较高优先级的后备机的答复,这三台后备机将从后备服务器s1、s2、s3以及s4中选出。在该列表中出现较早的后备服务器将被给予较高的优先级,并且将被考虑为同步后备。列表中出现的其他后备服务器表示潜在的同步后备。如果当前的任何同步后备因为某种原因断开连接,它将立刻被下一个最高优先级的后备服务器替代。关键词FIRST是可选的。
关键词ANY加上num_sync指定一种基于规定数量的同步复制,并且会让事务提交等待,直到它们的WAL记录被复制到所列出后备服务器中的至少num_sync台上为止。例如,设置ANY 3 (s1, s2, s3, s4)将导致每次提交会在收到s1、s2、s3以及s4中任意三台后备服务器的回答后立刻继续下去。
FIRST和ANY是大小写不敏感的。如果这些关键词被用作后备服务器的名字,其standby_name必须被放在双引号内。
PostgreSQL版本 9.6 之前使用过第三种语法,目前也仍然支持。它和FIRST和num_sync等于1的第一种语法相同。例如,FIRST 1 (s1, s2)和s1, s2具有相同的含义:s1或者s2会被选中作为同步后备服务器。
特殊项*匹配任意后备名称。
没有机制强制后备服务器名称的唯一性。在出现重复的情况下,匹配的后备之一将被认为是较高优先级,不过无法弄清到底是哪一个。
注意
每一个
standby_name都应该具有合法 SQL 标识符的形式,除非它是*。如果必要你可以使用双引号。但是注意在比较standby_name和后备机应用程序名称时是大小写不敏感的(不管有没有双引号)。
如果这里没有指定同步后备机名称,那么同步复制不能被启用并且事务提交将不会等待复制。这是默认的配置。即便当同步复制被启用时,个体事务也可以被配置为不等待复制,做法是将synchronous_commit参数设置为local或off。
这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
问题5:repmgr对 多机房双活/热备的支持?
可实现跨机房的切换。
但当机房完全故障时 ,机房网络孤岛时 无法完成切换

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











