






1.理解字符集(字符编码)
在计算机中所有数据都要使用数字来表示。人类书写的英文字母,汉字也要用数字来表示。那么就需要有一个从字符到数字的对应规则。这种规则就叫做字符集。
就比如,我随便定义一个规则(给每个字符上个’身份证号码’):字符0到9分别对应数字0到9,'a’对应数字10,'b’对应数字11等等。这就是可以说定义了一种字符集。
一个字符集都有其对应的编解码方式(字符与二进制的对应关系),一种字符集可以有多种编解码方式。
下面介绍几种最常见的字符集:
1.ASCII字符集–ASCII编解码
ascii码是早期通用的字符集,最早的字符集叫 American Standard Code for Information Interchange(美国信息交换标准代码),简称 ASCII。
ascii码的缺陷
ascii码最大的缺陷就是包含的字符非常少,因为ascii码是美国制定的,当时并没有考虑西文字母之外的字符,比如说它就没有包含中文字符,明显这个字符集是跟不上时代的发展的,是完全不够用的。
包含的字符
ASCII字符集:共定义了128个字符。大写字母26个,小写字母26个,0-9阿拉伯数字〈字符),所有的英文标点符号,数学运算符号,其他特殊符号以及控制码
编解码规则
ASCII编/解码:ASCII字符集中的每个字符与二进割字节流的对应关系。全部都是用1个字节(Byte) /8个比特(bit)标识一个字符,如0100 0001表示字符’A’,或者说,字符’A’被编码为0100 0001。
2.GBK字符集–GBK编码(windows默认编码方式)
包含的字符
GBK字符集︰在ASCII字符集的基础上,增加了简体汉字、繁体汉字、数学符号、罗马字母、希腊字母等。
GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。支持中文繁体字。国家曾规定所有微软的软件进入中国都要默认GBK编码,所以win系统 默认编码也为GBK。
编解码规则
GBK编/解码:GBK字符集中每个字符与二进制字节流的对应关系:
保留了ASCII字符集中的编解码方式,ASCII字符集中的字符用1个字节(Byte)/8个比特(bit)标识,并且对其ASCII编码,如0100 0001还是表示字符’A’,或者说,字符’A’还是被编码为0100 0001;
不在ASCII字符集中的字符,都用2个字节(Byte)/16个比特(bit)来标识,如1101000011101100表示’徐’。
3.Unicode字符集–UTF-8编解码(最通用)
Unicoide 的全称是 Universal Multiple-Octet Coded Character Set(通用多八位字符集,简称 UCS)。Unicode 在一个字符集中包含了世界上所有文字和符号,统一编码。有了unicode之后,大家就基本使用该字符集了。虽然Unicode字符集可以编码世界上所有的字符,但是没有规定多少个字节表示一个字符(没有规定存储),如果按照字符使用的最长的字节数来表示,就会造成存储上的浪费。后面将介绍Unicode字符集的编解码方式是如何解决这个问题的。
包含的字符
Unicode字符集︰为了解决传统的字符编码方案的局限性而产生的,包含了每种语言的每个字符,以满足跨语言、跨平台进行文本转换、处理的需求,适应全球化的发展。
编解码规则
UTF-8编/解码:Unicode字符集中每个字符与二进制字节流的对应关系。《(还有很多其他的编码方式也采用了Unicode字符集,如UTF-32、UTF-16等) 。
ASCII字符集中的字符用1个字节(Byte)/8个比特(bit)标识,并且对其ASCIl编码,如0100 0001还是表示字符’A,或者说,字符’A’还是被编码为0100 0001 ;
部分字符用2个字节(Byte)/16个比特(bit)标识。
中文字符一般用3个字节 (Byte)/24个比特(bit)标识,如1110 01011011111010010000表示’徐’,或者说,'徐’被编码为
1110 0101 1011 1110 1001 0000。
总结
1.在所有的编解码方式中,ASCIl码字符对应的二进制表示都是—样的。
2.编解码要相对应,才能不损失数据原本的意义,才不会误解数据;
数据以编码方式1进行编码得到字节流,那么这段字节流必须以对应的解码方式1进行解码,才可以得到原始的数据;否则这段字节流可能会:
1.解码成别的数据〈按照解码方式2,这一段二进别位对应了别的字符);
2.解码失败〈按照解码方式2,这一段二进制位可能不对应任何字符)。
通过字符集的表示,我们应该知道计算机的底层只是处理0和1,所以计算机存储、网络传输的并不是我们看到的数据的样子,而是一系列的0/1,这一系列的0和1,我们称为字节流。
因此,编码和解码的过程为:
1.编码:将数据转化为字节流,进行存储与网络传输。
2.解码:将字节转化为数据本身,可以阅读、使用和观看。
2.编解码
这里介绍的三种编解码方式都是基于Unicode字符集的。基于GBK字符集的编解码方式就是GBK,在上面已经介绍了。
1.utf-8编码
UTF-8可以说是当前互联网最常用的编码格式了,它基于Unicode字符集进行编码设计。它最大的特点是变长字节的编码设计,一个字符最长4个字节,最少1个字节,大部分的中文字符占3个字节。
2.utf-16编码
UTF-16以2或者4个字节编码表示unicode字符。和utf-8一样都是变长的编码方式,比较节省空间。
3.utf-32编码
UTF-32编码为固定长度4个字节。因为unicode范围为00FFFF-10FFFF,4个字节表示的范围为00000000-FFFFFFFF,能直接表示所有unicode编码,不需要进行转换编码转换。以空间换时间。
3.以txt文件为例,看一看不同类型的编解码的异同
1.GBK文件
首先创建一个txt文件,然后输入四个汉字
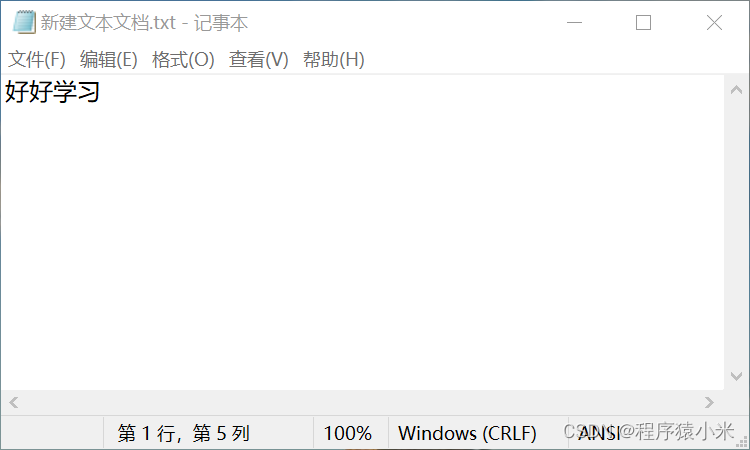
可以看到右下角我设置的txt文件的编码方式为ANSI,这就是GBK的编解码方式,然后我们看一下这个txt文件的大小。
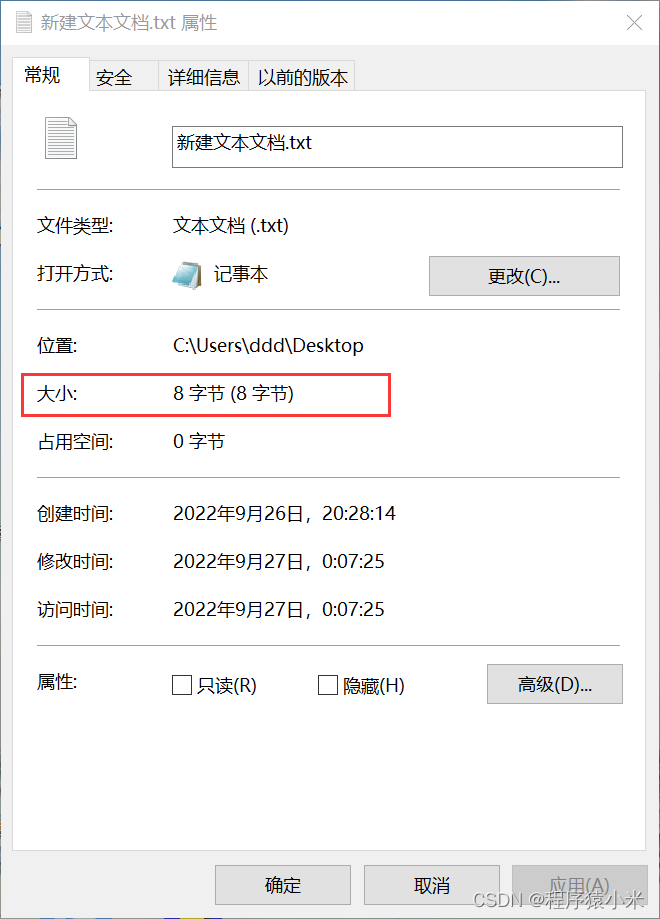
可以看到文件的大小为8字节。因为GBK对汉字的编码即使每个汉字用2个字节来表示。
2.utf-8文件
我将文件以utf-8编码方式保存
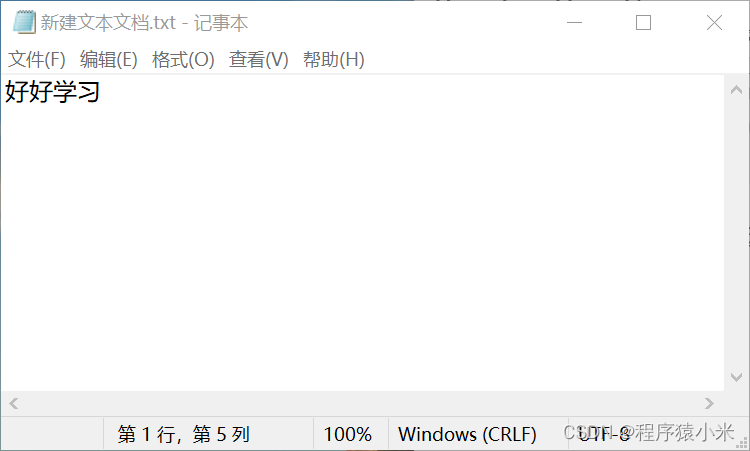
然后查看文件的大小。
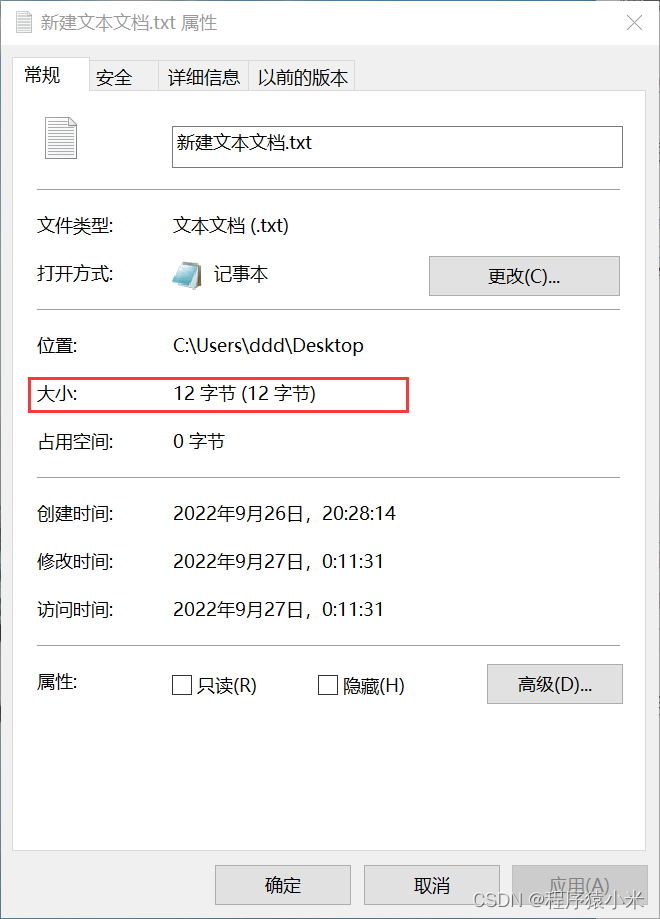
可以看到文件的大小为12字节,因为utf-8的编码方式对汉字的编码就是使用的3个byte。
4.在python中进行实际操作
代码1
a = '哈'
print(a.encode('gbk'))
print(a.encode('utf-8'))
print(a.encode('utf-16'))
输出
b'\xb9\xfe'
b'\xe5\x93\x88'
b'\xff\xfe\xc8T'
代码2
a = '哈'
b = a.encode('gbk')
c = b.decode('utf-8')
print(c)
输出
Traceback (most recent call last):
File "C:/Users/ddd/Desktop/image_processing/encode_decode.py", line 15, in <module>
c = b.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte
因为编码和解码没有统一,所以gbk编码的格式,用utf-8来解释的时候就无法识别,所以就报错了。所以不管使用哪种编码方式,解码方式一定要和编码方式一一对应才行。
代码3
a = '哈'
b = a.encode('gbk')
c = b.decode('gbk')
print(c)
输出
哈
当编码和解码一致的时候,就可以正常解码出来了。
代码4
import sys, locale
s = "小甲"
print(s)
print(type(s))
print(sys.getdefaultencoding())
print(locale.getdefaultlocale())
with open("utf1", "w", encoding="utf-8") as f:
f.write(s)
with open("gbk1", "w", encoding="gbk") as f:
f.write(s)
with open("jis1", "w", encoding="shift-jis") as f:
f.write(s)
输出
小甲
<class 'str'>
utf-8
('zh_CN', 'cp936')
第一个utf-8是指系统的默认编码,这里的系统不是说的操作系统,而是python3的编译器本身。
第二个utf-8是本地默认编码,这个就是操作系统的编码,在win10系统中是gbk,在linux系统中就是utf-8。
然后通过查看保存的三个文件,如果在pycharm中看的话,会发现只有utf-8的不乱码,另外两个都是乱码,这是因为pycharm自己的默认编码方式是utf-8,所以pycharm可以识别出来。
如果在系统中打开的话,在windows系统中用写字板打开这三个文件,不要使用记事本,因为记事本是txt文件类型,txt可以自动转化对应的编码方式,还是可以正常显示的,使用写字板可以默认使用系统的编码方式,这样就可以看到,只有gbk保存的没有乱码,另外两个都是乱码。这是因为windows的默认编解码方式是gbk。
下面解释一下为什么出现这种情况,在计算机内存中,统一使用unicode编码方式,当需要保存到硬盘或者进行传输的时候,一般需要用utf-8的方式来进行变长编码以节约空间和提高传输速度。
以txt文件为例,我们在打开txt文件进行编辑的时候,从文件读取使用utf-8编码的文本数据并转换成unicode的编码方式(解码)加载到内存中(所有的数据在内存中都是使用unicode的方式编码),编辑完成后再把unicode编码的数据转换为utf-8编码(编码)的方式保存为文件到硬盘中。
再以我们浏览网页为例,在浏览网页的时候服务器会把动态生成的unicode编码的内容转换为utf-8的编码方式(编码)通过网络传到自己的电脑上,电脑再将utf-8编码的内容转化为unicode编码的方式(解码)加载到内存中在网页上显示。
经过上面的介绍应该对编解码过程有了比较清晰的认识,再进一步介绍我们编写的python代码。其实我们编写的python代码本质上也是一个文本文件,所以在我们编写完python代码并保存的时候同样也是和上面一样的编码过程,以pycharm为例,pycharm一般默认的文件编码方式就是utf-8,在pycharm右下角可以看到utf-8的标识。在我们在pycharm中编写完代码执行的过程其实是两步,首先把我们写的代码从内存中以unicode编码的方式转化为utf-8的方式保存到硬盘中,然后再从硬盘中读出utf-8编码的代码文件并转为unicode到内存中,并执行代码。
代码5
#coding=gbk
import sys, locale
s = "小甲"
#coding=gbk
import sys, locale
s = "小甲"
print(s)
print(type(s))
print(sys.getdefaultencoding())
print(locale.getdefaultlocale())
with open("utf2","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk2","w",encoding = "gbk") as f:
f.write(s)
with open("jis2","w",encoding = "shift-jis") as f:
f.write(s)
在这里,和代码4基本一样,就是在头部加了一个编码声明,在这里我们使用txt文件编写代码并且使用命令行的方式执行代码。注意我使用txt默认的文件编码方式utf-8保存代码文件。
输出

可以看到我在代码中添加了
coding=gbk之后就报错了,这是因为头部声明的编码方式gbk是在解码的时候用的,python解释器在要执行这个代码文件的时候,首先要将这个文件从硬盘加载到内存中,而coding=gbk就是指明的这个解码方式,而我保存的时候使用的是utf-8的方式进行编码保存到硬盘的,现在用gbk的方式进行解码所以报错了。
大家一定到注意所有文件(也包括代码文件)的保存和打开都是两个过程,即编码和解码,而’编码’和‘解码’一定要一一对应上才能正确的解码打开文件。
最后再来强调一下,系统默认编码sys.getdefaultencoding()和本地默认编码locale.getdefaultlocale()的区别。
1.系统默认sys.getdefaultencoding()
在python3编译器读取.py文件时若没有头文件编码声明,则默认使用utf-8来对.py文件进行解码。并且在调用encode()这个函数时,不传参的话默认是utf-8。
2.本地默认编码locale.getdefaultlocale()
指的是操作系统本身的编码方式,windows10是gbk,linux是utf-8。
在编写python3的代码时,若使用open()函数,而不给它传入encoding参数,则会自动使用本地的默认编码。使用Python的 open( ) 函数时,是内存中的进程与磁盘的交互,而这个交互过程中的编码格式则是使用操作系统的默认编码(Linux为utf-8,windows为gbk)。进程在内存中的表现是“ unicode ”的编码;当python3编译器读取磁盘上的.py文件时,是默认使用“utf-8”的;当进程中出现open(), write() 这样的存储代码时,需要与磁盘进行存储交互时,则是默认使用操作系统的默认编码。
补充:Unicode本身的编码方式其实是唯一的,对于任意一个字符,其都被编码成了2个字节的长度,即16位。Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。

















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











