







提示:作者将用一个系列的博客,总结机器/深度学习算法工程师岗位面试中常见的一些知识点,以帮助小伙伴们更好的应对面试。本系列的内容包括如下:
系列一:机器学习相关基础知识小Tip
系列二:Python基础总结
系列三:CNN相关知识
系列四:Transformer相关知识总结
系列五:经典/热门模型介绍,及深度学习常用知识点
系列六:PyTorch相关知识点及端侧部署基础知识
注:以防再也找不到我,可以收藏博客、关注作者,查看最新内容哦(持续更新中…)
文章目录
系列一:机器学习相关基础知识小Tip
1.训练集/验证集/测试集划分:
一般来说,如果当数据量不是很大的情况(万级别以下)可以将训练集、验证集和测试集划分为6:2:2;如果是万级别甚至十万级别的数据量,可以将训练集、验证集和测试集比例调整为98:1:1。(注:在数据集划分时要主要类别的平衡)
2. 正则化的本质以及常用正则化手段?
正则化本质是对某一问题加以先验的约束以达到某种特定目的的一种操作。在机器学习中我们通过使用正则化方法,防止其过拟合,降低其泛化误差。常用的正则化手段:数据增强;使用L范数约束(范数主要用来表征高维空间中的距离,故在一些生成任务中也直接用L范数来度量生成图像与原图像之间的差别。);dropout;early stopping;对抗训练。
3.如何找到让F1最高的分类阈值?
一般设0.5作为二分类的默认阈值,但一般不是最优阈值。想要精准率高,一般使用高阈值,而想要召回率高,一般使用低阈值。在这种情况下,我们通常可以通过P-R曲线去寻找最优的阈值点或者阈值范围。
4. sigmoid函数和Softmax函数
在二分类问题中,我们可以使用sigmoid函数将输出映射到[0,1]区间中,从而得到单个类别的概率。当我们将问题推广到多分类问题时,可以使用Softmax函数,对输出的值映射为概率值。
5.交叉熵和均方根误差。
P代表真实值的概率分布,q代表预测值的概率分布。交叉熵从相对熵(KL散度)演变而来,log代表了信息量,q越大说明可能性越大,其信息量越少;反之则信息量越大。通过不断的训练优化,逐步减小交叉熵损失函数的值来达到缩小p和q距离的目的。
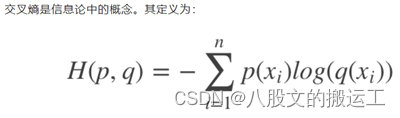
**交叉熵和均方根误差(MSE,差的平方然后平均)的区别?**1)MSE无差别得关注全部类别上预测概率和真实概率的差。交叉熵关注的是正确类别的预测概率。2)MSE梯度收敛更慢,不利于参数更新,因为它求导的结果相比于交叉熵还多乘以一个sigmod函数 。3)均方损失:假设误差是正态分布,适用于线性的输出(如回归问题),特点是对于与真实结果差别越大,则惩罚力度越大,这并不适用于分类问题。交叉熵损失:假设误差是二值分布,可以视为预测概率分布和真实概率分布的相似程度。在分类问题中有良好的应用。
6. 解决过拟合的方法:
1)重新清洗数据。2)增加训练样本数量。比如在图像分类问题上,可以通过图像的平移、旋转、缩放、加噪声等方式扩充数据;也可以用GAN网络来合成大量的新训练数据。3)降低模型复杂程度。适当降低模型复杂度可以避免模型拟合过多的噪声数据。4)加入正则化方法,增大正则项系数。给模型的参数加上一定的正则约束,比如将权值的大小加入到损失函数中。5)采用dropout方法。6)提前截断(early stopping),减少迭代次数。7)增大学习率。8)集成学习方法。集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如Bagging方法。
7.解决欠拟合的方法:
1)可以增加模型复杂度。对于神经网络可以增加网络层数或者神经元数量。2)减小正则化系数。正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要有针对性地减小正则化系数。3)增大数据量4)Boosting。
8.判别模型与生成模型
**判别模型:**由数据直接学习决策函数Y=f(x)或条件概率分布P(Y|X)作为预测模型,判别方法关注的是对于给定的输入x,应该预测什么样的输出Y。有KNN,感知机,决策树,逻辑回归,线性回归,最大熵模型,SVM,提升方法,条件随机场,LDA,条件随机场。
**生成模型:**由数据学习联合概率分布P(X,Y),然后由P(Y|X)=P(X,Y)/P(X)求出概率分布P(Y|X)作为预测的模型。该方法表示了给定输入X与产生输出Y的生成关系。有朴素贝叶斯,隐马尔可夫(HMM)。
**生成模型的特点:**生成方法可以还原出联合概率分布P(X,Y),而判别方法则不能;生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快速的收敛于真实模型;当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
**判别模型的特点:**判别方法直接学习的是条件概率P(Y|X)或决策函数f(X),直接产生预测结果,往往学习的准确率更高;由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象,定义特征并使用特征,因此可以简化学习问题。
注:这些知识点是作者在备战秋招的时候,根据一些零碎的博客做的总结(写作目的:主要用于各位小伙伴们的知识交流,如若侵权,则会及时删除)。
祝愿您能顺利通过每一次面试哈,干就完事了!加油!
*以防再也找不到我,可以收藏博客、关注作者,查看后续系列内容哦(持续更新中…)















 8242
8242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









