







提示:作者将用一个系列的博客,总结机器/深度学习算法工程师岗位面试中常见的一些知识点,以帮助小伙伴们更好的应对面试。本系列的内容包括如下:
系列一:机器学习相关基础知识小Tip
系列二:Python基础总结
系列三:CNN相关知识
系列四:Transformer相关知识总结
系列五:经典/热门模型介绍,及深度学习常用知识点
系列六:PyTorch相关知识点及端侧部署基础知识
注:以防再也找不到我,可以收藏博客、关注作者,查看最新内容哦(持续更新中…)
文章目录
系列六:PyTorch相关知识点及端侧部署基础知识
1.PyTorch相较于Tensorflow的优缺点:
1)Pytorch符合命令式编程的特点,实现方便但是效率低;Tensorflow为符号式编程,需要先定义好计算流程再执行,因此效率比较高,但同时实现起来比较复杂。2)Pytorch为动态图,可以随时改变模型,灵活且方便调试,而Tensorflow采用的是静态图,需要定义好之后调用session来执行图。3)Pytorch可以用matplotlib进行数据的可视化化,而Tensorflow可以是用自带的工具TensorBoard可视化,可视化效果很好。4)TensorFlow在GPU的分布式计算上更为出色,在数据量巨大时效率比pytorch要高一些。
2.机器学习建模调参方法总结?
1)贪心调参(坐标下降)是一类优化算法,其最大的优势在于不用计算待优化的目标函数的梯度。与坐标下降法不同的是,不是循环使用各个参数进行调整,而是贪心地选取了对整体模型性能影响最大的参数。参数对整体模型性能的影响力是动态变化的,故每一轮坐标选取的过程中,这种方法在对每个坐标的下降方向进行一次直线搜索。简言之,拿对当前模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时省力。
2)随机搜索:在超参的给定分布中随机采样作为本轮超参数,并进行尝试,然后不断迭代找到最优超参数。随机搜索的好处在于搜索速度快,但是容易错过一些重要的信息。
2)网格调参GridSearchCV就是对网格中每个交点进行遍历,从而找到最好的一个组合。网格的维度就是超参的个数,若有k个超参,每个超参有m个候选,那么需要遍历k^m个组合,因此它的好处是效果不错,适用于需要对整个参数空间进行搜索的情况,缺陷是计算代价非常非常大,面临维度灾难
3)贝叶斯调参:贝叶斯优化通过基于目标函数的过去评估结果建立替代函数(概率模型),来找到最小化目标函数的值。贝叶斯方法与随机或网格搜索的不同之处在于,它在尝试下一组超参数时,会参考之前的评估结果,因此可以省去很多无用功。超参数的评估代价很大,因为它要求使用待评估的超参数训练一遍模型,但在高维参数空间下,贝叶斯优化复杂度较高,效果会近似随机搜索。
——后续将补充怎么使用Ray Tune在pytorch中实现自动调节神经网络参数——
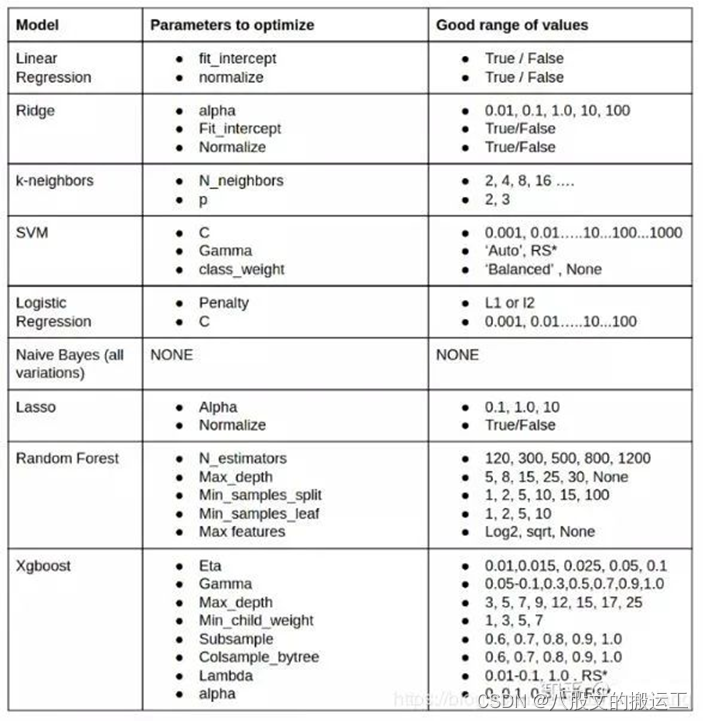
上述表格描述了经典模型可调参数及范围选取的参考
3. 减小模型内存占用有哪些方法?
模型剪枝;模型蒸馏;模型量化;模型结构调整
4.有哪些经典的轻量化网络?
1)SqueezeNet 2)MobileNet 3)ShuffleNet 4)Xception 5)GhostNet
3. 影响模型inference速度的因素?1)FLOPs(意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。)2)MAC(内存访问成本)3)并行度(模型inference时操作的并行度越高,速度越快)4)计算平台(GPU,AI协处理器,CPU等)。
5. GPU显存占用和GPU利用率的定义?
GPU在训练时有两个重要指标可以查看,即显存占用和GPU利用率。显存指的是GPU的空间,即内存大小。显存可以用来放模型,数据等。GPU 利用率主要的统计方式为:在采样周期内,GPU 上有 kernel 执行的时间百分比。可以简单理解为GPU计算单元的使用率。
6. 神经网络的显存占用分析?
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。在整个神经网络训练周期中,在GPU上的显存占用主要包括:数据,模型参数,模型输出等。数据侧:举例,一个323128128的四维矩阵,其占用的显存 = 323128128*4 /1000 / 1000 = 6.3M
模型侧:占用显存的层包括卷积层,全连接层,BN层,梯度,优化器的参数等。输出侧:占用的显存包括网络每一层计算出来的feature map以及对应的梯度等。
7. X86和ARM架构在深度学习侧的区别?
AI服务器与PC端一般都是使用X86架构,因为其高性能;AI端侧设备(手机/端侧盒子等)一般使用ARM架构,因为需要低功耗。X86指令集的指令是复杂的,一条很长指令就可以很多功能;而ARM指令集的指令是很精简的,需要几条精简的短指令完成很多功能。X86的方向是高性能方向,因为它追求一条指令完成很多功能;而ARM的方向是面向低功耗,要求指令尽可能精简。
8. FP32,FP16以及Int8的区别?
常规精度一般使用FP32(32位浮点,单精度)占用4个字节,共32位;低精度则使用FP16(半精度浮点)占用2个字节,共16位,INT8是八位整型,占用1个字节等。混合精度(Mixed precision)指使用FP32和FP16。 使用FP16 可以减少模型一半内存,但有些参数必须采用FP32才能保持模型性能。虽然INT8精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。不同精度进行量化的归程中,量化误差不可避免。在模型训练阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的阶段,精度要求没有那么高,一般F16或者INT8就足够了,精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在端侧设备中。
9. 为何在AI端侧设备一般不使用传统图像算法?
AI端侧设备多聚焦于深度学习算法模型的加速与赋能,而传统图像算法在没有加速算子赋能的情况下,在AI端侧设备无法发挥最优的性能。
10.模型压缩的必要性与可行性?
模型压缩是指对算法模型进行精简,进而得到一个轻量且性能相当的小模型,压缩后的模型具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在端侧设备中。AI模型的参数在一定程度上能够表达其复杂性,但并不是所有的参数都在模型中发挥作用,部分参数作用有限,表达冗余,甚至会降低模型的性能,模型压缩能用于解决这个问题。
注:这些知识点是作者在备战秋招的时候,根据一些零碎的博客做的总结(写作目的:主要用于各位小伙伴们的知识交流,如若侵权,则会及时删除)。
祝愿您能顺利通过每一次面试哈,干就完事了!加油!
*以防再也找不到我,可以收藏博客、关注作者,查看后续系列内容哦!这一系列内容就到这里了,后续我会将《百面机器学习》书中的重点知识总结,以供大家参考(持续更新中…)















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









