







 本文详细介绍了支持向量机(SVM)的概念,包括硬间隔SVM的二次凸规划问题、对偶问题的转换及求解,以及如何通过引入HingeLoss来实现软间隔SVM,以应对噪声数据。通过对拉格朗日乘子法的应用,展示了从原始问题到对偶形式的转化过程,并解释了KKT条件在SVM中的作用。最后,阐述了软间隔SVM如何缓解过拟合问题。
本文详细介绍了支持向量机(SVM)的概念,包括硬间隔SVM的二次凸规划问题、对偶问题的转换及求解,以及如何通过引入HingeLoss来实现软间隔SVM,以应对噪声数据。通过对拉格朗日乘子法的应用,展示了从原始问题到对偶形式的转化过程,并解释了KKT条件在SVM中的作用。最后,阐述了软间隔SVM如何缓解过拟合问题。
目录
SVM是一种无监督机器学习方法,常用于二分类问题。其相较于逻辑回归,引入了核函数的概念,对非线性关系有更好的分类效果;同时由于对偶问题的引入,使得计算的复杂性由维度的大小转变为样本的数量,避免了维度爆炸。但是由于SVM的本质是二次规划问题,样本数量大的时候,需要占用大量的存储空间和时间,不容易实现;同时SVM解决多分类问题存在一定困难。
一、硬间隔SVM(Hard Margin SVM)
硬间隔SVM是一个二次凸规划问题,其形式为:
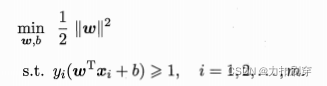
其推导过程为:
(1)列出原始目标函数和约束条件。
目标函数:使间隔最大(间隔指离分隔线最近点到分隔线的距离)
约束条件:分隔线两侧的所有点均属于同一类别
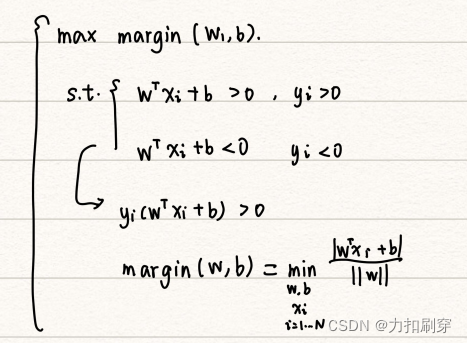
即:
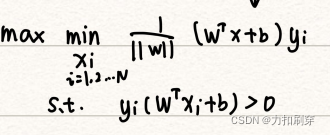
其中,间隔(最小距离)的推导过程如下:

(2)表达式化简
目标函数中,由于w与x无关,所以可以将1/||w||提出来;
由第一步得到的约束条件可知,必定存在一个γ>0,使得所有样本到分隔线的距离>γ,即:
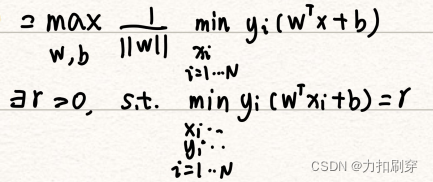
这样,可以将目标函数中的min后所有元素进行替换,即:
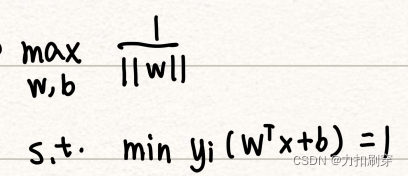
(3)最终形式
目标函数:将max化为min,转化为二次型
约束条件:由于最小距离等于1,所以所有样本的距离大于等于1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5832
5832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









