







- 在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,超市也因此发现了一个规律,在购买婴儿尿布的年轻父亲们中,有30% ~40%的人同时要买一些啤酒。超市随后调整了货架的摆放,把尿布和啤酒放在一起,明显增加了销售额。
- 若两个或多个变量的取值之间存在某种规律性,就称为关联
- 关联规则是寻找在同一个事件中出现的不同项的相关性,比如在一次购买活动中所买不同商品的相关性.
基本概念
-
Def 1 事务集:所有的流水记录构成的集合。如下表,ABCDABCFBDEF…,
-
Def 2 记录( 事务 ) :ABCD 叫做一条记录(事务)
-
Def3 项目(项) :A,B,C …叫做一个项目(项)
-
Def 4 项目集(项集):由项组成的集合,如{A,B,E,F},{A,B.C}就是一个项集
-
Def 5 K项集:项集中元素的个数为K,如{A,B,E,F}就是4项集
-
Def 6 支持度(Support): S u p p o r t ( X → Y ) = C o u n t ( X ∪ Y ) C o u n t ( T o t a l ) Support(X \rightarrow Y) = \frac{Count(X \cup Y)}{Count(Total)} Support(X→Y)=Count(Total)Count(X∪Y)
S u p p o r t ( X ) = 某个项集 X 在事务集中出现的次数 事务集中记录的总个数 Support(X) = \frac{某个项集X在事务集中出现的次数}{事务集中记录的总个数} Support(X)=事务集中记录的总个数某个项集X在事务集中出现的次数
如X={A,C} 则 Sup (X)= 4 7 \frac{4}{7} 74= 0.57 -
Def 7 置信度(Confidence): C o n f i d e n c e ( X → Y ) = S u p p o r t ( X ∪ Y ) S u p p o r t ( X ) Confidence(X \rightarrow Y) = \frac{Support(X \cup Y)}{Support(X)} Confidence(X→Y)=Support(X)Support(X∪Y)
如X={A},Y={C)则 C o n f i d e n c e ( X ⇒ Y ) = S u p p o r t ( X ∪ Y ) S u p p o r t ( X ) = 4 / 7 5 / 7 = 4 5 = 0.8 Confidence(X \Rightarrow Y) = \frac{Support(X \cup Y)}{Support(X)}=\frac{4/7}{5/7}=\frac{4}{5}=0.8 Confidence(X⇒Y)=Support(X)Support(X∪Y)=5/74/7=54=0.8 -
Def 8 提升度: Lift ( A → B ) = C o n f i d e n c e ( A → B ) S u p p o r t ( A → B ) \text{Lift}(A \rightarrow B) = \frac{Confidence(A \rightarrow B)}{Support(A \rightarrow B)} Lift(A→B)=Support(A→B)Confidence(A→B)
理解为B在A发生的基础上再发生的概率与B单独发生概率的比值 -
Def 9 频繁K项( 目)集 : 满足最小支持度的K项集
-
Def 10 候选K项(目)集 : 用来生成频繁K项集的K项集。( 不等价与所有K项集)
| 单号 | 商品 |
|---|---|
| 1 | ABCD |
| 2 | ABCE |
| 3 | BDEF |
| 4 | BCDE |
| 5 | ACDF |
| 6 | ABC |
| 7 | ABE |
两个定理
Theorem 1:如果X是一个频繁K项集,则它的所有子集一定也是频繁的
Theorem 2:如果X不是K-1项频繁,则它一定不是频繁K项集。
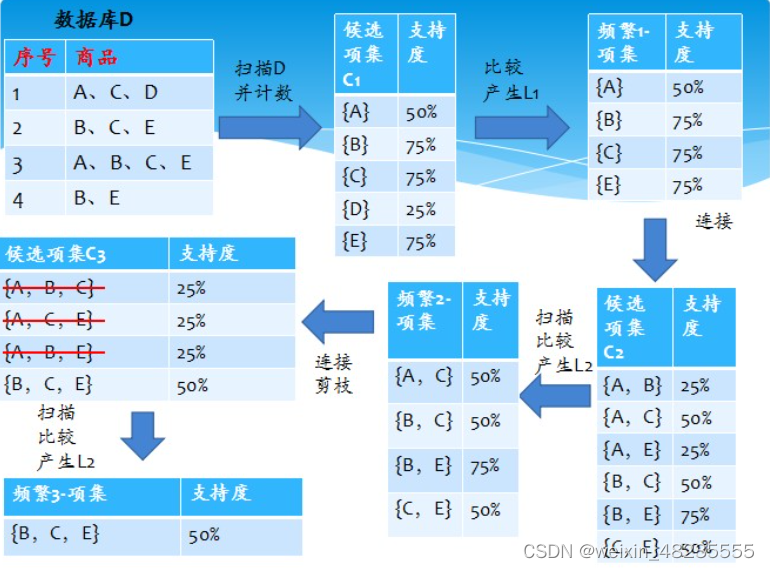
算法流程
- Step1:令K = 1,计算单个商品(项目)的支持度,并筛选出频繁1项集
- Step2:(从K=2开始)根据K-1项的频繁项目集生成候选K项目集,并进行预剪枝
- Step3:由候选K项目集生成频繁K项集( 筛选出满足最小支持度的k项集)
重复步骤2和3,直到无法筛选出满足最小支持度的集合。 (第一阶段结束) - Step4:将获得的最终的频繁K项集,依次取出。同时计算该次取出的这个K项集的所有真子集,然后以排列组合的方式形成关联规则,并计算规则的置信度以及提升度,将符合要求的关联规则生成提出。 (算法结束)















 2047
2047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









