







入门Go语言,这一篇就Go了
- Go 语言系列1:Let's Go!
- Go 语言系列2:变量
- Go 语言系列3:常量
- Go 语言系列4:整型
- Go 语言系列5:浮点型
- Go 语言系列6:布尔型
- Go 语言系列7:字符串
- Go 语言系列8:复数
- Go 语言系列9:byte 和 rune
- Go 语言系列10:数组
- Go 语言系列11:切片
- Go 语言系列12:Map
- Go 语言系列13:指针
- Go 语言系列14:结构体
- Go 语言系列15:函数
- Go 语言系列16:包
- Go 语言系列17:条件语句
- Go 语言系列18:选择语句
- Go 语言系列19:循环语句
- Go 语言系列20:defer 延迟调用
- Go 语言系列21:goto 无条件跳转
- Go 语言系列22:方法
- Go 语言系列23:接口
- Go 语言系列24:go 协程
- Go 语言系列25:channel 信道
- Go 语言系列26:WaitGroup
- Go 语言系列27:Select
- Go 语言系列28:互斥锁与读写锁
- Go 语言系列29:错误处理
- Go 语言系列30:异常处理
- Go 语言系列31:make 和 new
- Go 语言系列32:头等函数
- Go 语言系列33:静态类型与动态类型
- Go 语言系列34:协程池
- Go 语言系列35:使用 GDB 调试
- Go 语言系列36:反射
- Go 语言系列37:反射三大定律
- Go 语言系列38:结构体里的 Tag 标签
- Go 语言系列39: Go 语言中的 Context
- Go 语言系列40:编码规范
Go 语言系列1:Let’s Go!
Go 语言简介
Go 又称 Golang ,是 Google 的 Robert Griesemer,Rob Pike 及 Ken Thompson 开发的一种静态强类型、编译型语言。Go 语言语法与 C 相近,但功能上有:内存安全,GC(垃圾回收),结构形态及 CSP-style 并发计算。
Go 的安装
Go 支持很多主流平台,例如 Windows 、 Mac 、 Linux 等等。首先需要前往 Go 官网下载相应平台的二进制文件,官网地址为:
但因为众所周知的原因访问不了,可以访问下面的地址:
当然也可以到 Go 语言中文网下载,Go 语言中文网下载地址为:
Windows
在 Go 官网下载 MSI 安装程序。安装安装指引程序安装完成后,会将 Golang 安装到 C:\Program Files\Go 目录下,同时 C:\Program Files\Go\bin 目录也会被添加到 PATH 环境变量中。
我使用的是 Windows 操作系统,所以安装完成后,在 cmd 中使用命令 go version 验证是否安装成功。如果安装成功,会显示 go 的版本信息,例如:
C:\Users>go version
go version go1.17.2 windows/amd64
Mac OS
在 Go 官网下载 pkg 安装程序。安装安装指引程序安装完成后,会将 Golang 安装到 /usr/local/go 目录下,同时 /usr/local/go/bin 文件夹也会被添加到 PATH 环境变量中。
Linux
在 Go 官网下载 tar.gz 文件,并解压到 /usr/local 。添加 /usr/local/go/bin 到 PATH 环境变量中。Go 就已经成功安装在 Linux 上了。
Go IDE 的安装
个人推荐使用 GoLand ,GoLand 是 Jetbrains 家族的 Go 语言 IDE,有 30 天的免费试用期。支持系统环境三大平台 Mac 、 Linux 和 Windows 。 GoLand 下载地址为:
LiteIDE 是一款开源、跨平台的轻量级 Go 语言集成开发环境(IDE)。但只支持 Windows 和 Linux 。 LiteIDE 下载地址为:
http://sourceforge.net/projects/liteide/files/
当然你也可以使用 Visual Studio Code 并安装相应的 Go 扩展来编写 Go 程序。
第一个 Go 程序
接下来,我们就从编写第一个 Go 程序开始,学习 Go 语言。
首先,在任意目录下创建一个目录 hello 。接着在此目录下创建一个 hello.go 文件,打开文件键入下面的代码,保存并退出。
// hello.go
package main
import "fmt"
func main() {
fmt.Println("Let's go!")
}
编译运行 Go 程序
首先打开 cmd 窗口,进入存放 hello.go 目录下(可以直接在文件资源管理器的地址栏输入 cmd 进入),然后使用命令 go build hello.go 编译 hello.go 程序,编译完成后,你能在目录下看到多了一个 hello.exe 可执行文件。接着同样在 cmd 窗口使用命令 hello 运行 hello.exe 程序,你会在 cmd 窗口上看到输出了字符串 Let's go! 。
C:\Users\hello>go build hello.go
C:\Users\hello>hello
Let's go!
当然,你也可以使用 go run hello.go 命令编译链接程序并运行,同样也会输出上面的字符串。但是,使用 go run 命令不会在运行目录下生成任何文件,可执行文件被放在临时文件中被执行,工作目录被设置为当前目录。
C:\Users\hello>go run hello.go
Let's go!
简析第一个 Go 程序
// hello.go
package main
import "fmt"
func main() {
fmt.Println("Let's go!")
}
首先,第一行是注释语句,跟 C 语言一样,Go 语言也采用 // 和 /* */ 作为注释标记。
其次,在第二行指定了该文件属于 main 包。 Go 代码是使用包来组织的,包类似于其他语言中的库和模块。一个包由一个或多个 .go 源文件组成,放在一个文件夹中,该文件夹的名字描述了包的作用。每一个源文件的开始都用 package 声明,上面的例子里面是 package main ,指明了这个文件属于 main 包。后面跟着它导入的其他包的列表,然后是存储在文件中的程序声明。名为 main 的包比较特殊,它用来定义一个独立的可执行程序,而不是库。在 main 包中,函数 main 也是特殊的,不管在什么程序中, main 做什么事情,它总是程序开始执行的地方。
第四行引入了 fmt 包,因为使用了 fmt 包中的函数来格式化输出和扫描输入,所以要在这里导入此包。 Println 是 fmt 中一个基本的输出函数,它输出一个或多个用空格分隔的值,结尾使用一个换行符,这样看起来这些值是单行输出。 Go 的标准库中有 100 多个包用来完成输入、输出、排序、文本处理等常规任务。在 Go 程序中,我们需要告诉编译器源文件需要哪些包,用 package 声明后面的 import 来导入这些包。我们必须精确地导入需要的包。在缺失导入或存在不需要的包的情况下,编译都会失败,这种严格的要求可以防止程序演化中引用不需要的包。 import 声明必须跟在 package 声明之后。
第六行我们定义了一个 main 函数,该函数是一个特殊的函数,整个程序从 main 函数开始运行。 mian 函数必须放在 main 包中。其中的 { 和 } 分别表示函数的开始和结束部分。特别注意,在 Go 中不需要在语句或声明后面使用分号结尾,除非有多个语句或声明出现在同一行。事实上,跟在特定符号后面的换行符被转换为分号,在什么地方进行换行会影响对 Go 代码的解析。例如, { 符号必须和关键字 func 在同一行,不能独自成行,并且在 x+y 这个表达式中,换行符可以在 + 操作符的后面,但是不能在 + 操作符的前面。Go 对于代码的格式化要求非常严格。我们可以使用 gofmt 工具将代码以标准格式重写, go 工具的 fmt 子命令使用 gofmt 工具来格式化指定包里的所有文件或者当前文件夹中的文件(默认情况下)。
第七行我们使用 fmt 包中的 Println 函数把文本写入标准输出。
Go 语言系列2:变量
变量的命名
变量名 必须以一个 字母或下划线开头 ,后面可以跟任意数量的字母、数字或下划线,在 Go 语言中,变量名区分大小写字母。当然,上述的命名规则在命名 函数名 、 常量名 、 类型名 、 语句标号 和 包名 等都适用。
特别注意的是,在 Go 中有 25 个关键字不能用于定义名字,它们分别是:
| 关键字 | 作用 |
|---|---|
| break | 用于跳出循环 |
| default | 用于选择结构的默认选项(switch、select) |
| func | 定义函数 |
| interface | 定义接口 |
| select | Go语言特有的channel选择结构 |
| case | 选择结构标签 |
| defer | 延迟执行内容(在函数结尾的时候执行) |
| go | 并发执行 |
| map | 定义map类型 |
| struct | 定义结构体 |
| chan | 定义channel |
| else | 选择结构 |
| goto | 跳转语句 |
| package | 包 |
| switch | 选择结构 |
| const | 定义常量 |
| fallthrough | 如果case带有fallthrough,程序会继续执行下一条case,不会再判断下一条case的值 |
| if | 选择结构 |
| range | 从slice、map等结构中取元素 |
| type | 定义类型 |
| continue | 跳过本次循环 |
| for | 循环结构 |
| import | 导入包 |
| return | 返回 |
| var | 定义变量 |
当然,除了上面所说的 25 个关键字之外,还有大约 30 多个预定义的名字,具体如下。
内建常量:
true false iota nil
内建类型:
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
内建函数:
make len cap new append copy close delete
complex real imag
panic recover
这些内部预先定义的名字并不是关键字,你可以在定义中重新使用它们,但在普通情况下并 不推荐 这么做,免得引起语义混乱。在习惯上,Go语言程序员推荐使用 驼峰式 命名。
变量的声明
Go 语言主要有四种类型的声明语句: var(声明变量) 、 const(声明常量) 、 type(声明类型) 和 func(声明函数) 。
接下来我们就详细讲一讲几种声明变量的方法。
第一种声明方法 :一行一个变量
var <name> <type>
其中 var 是关键字, name 是变量名, type 是类型。
当然,你也可以在声明时给定该变量的初始值:
var <name> <type> = <expression>
如果你在声明变量的时候只指定了其类型, Go 会自动给你的变量初始化为默认值。例如 string 类型会初始化为空字符串 "" , int 类型会初始化为 0 , float 会初始化为 0.0 , bool 类型会初始化为 false , 接口 和 引用类型 和 指针类型 就初始化为 nil , 数组 或 结构体 等聚合类型对应的默认值是每个元素或字段都是对应该类型的默认值等。
你在已经给定变量初始值的情况下,可以将类型 type 部分省略, Go 将根据初始化表达式 expression 来推导变量的类型:
var <name> = <expression>
下面演示了一行声明一个变量的例子:
package main
import (
"fmt"
)
func main() {
// var <name> <type>
var name string
fmt.Println("name = ", name)
// var <name> <type> = <expression>
var pi float64 = 3.14
fmt.Println("pi = ", pi)
// var <name> = <expression>
var phone = "123456"
fmt.Println("phone = ", phone)
}
运行该程序输出为:
name =
pi = 3.14
phone = 123456
第二种声明方法 :一组变量一起声明
var (
<name> <type>
<name> <type>
...
)
上面的例子每个变量都要写一行声明,为了简洁,我们可以修改成一组变量一起声明的形式:
package main
import (
"fmt"
)
func main() {
// var (
// <name> <type>
// <name> <type>
// ...
// )
var (
name string
pi float64 = 3.14
phone = "123456"
)
fmt.Println("name = ", name)
fmt.Println("pi = ", pi)
fmt.Println("phone = ", phone)
}
当然,运行该程序会产生同样的输出。
第三种声明方法 :短声明,只能在函数内
在函数内部,有一种称为简短变量声明语句的形式可用于声明和初始化局部变量,变量的类型根据表达式来自动推导。
<name> := <expression>
例如,下面的三条等价的语句:
phone := "123456"
var phone string = "123456"
var phone = "123456"
但要特别注意,短声明 只能 用在函数内部,在包级别的声明不能使用短声明,要使用关键字 var 进行声明。
第四种声明方法 :一行声明和初始化多个变量
var <name1>, <name2> <type> = <expression1>, <expression2>
下面是一行声明和初始化多个变量的例子:
var i, j, k int // int, int, int
var ok, number = true, 1.2 // bool, float64
phone, city := "123456", "Beijing" // string, string
这种方法经常用于变量之间的交换:
var a int = 1
var b int = 2
b, a = a, b
第五种声明方法 :通过 new 创建指针变量
一般变量分为两种,上面说过的那些存放数据本身的 普通变量 和存放数据地址的 指针变量 。
例如,下面的例子,用 var x int 声明语句声明的是一个 x 普通变量,那么 &x 表达式所代表的就是一个指向 x 普通变量的指针变量,即 &x 为存放 x 数据的地址,其对应的数据类型为 *int 。而 *p 表达式所代表的是对应 p 指针指向的变量的值,即 x 的值。
package main
import (
"fmt"
)
func main() {
x := 1
p := &x // p, of type *int, points to x
fmt.Println("p = ", p) // "0xc0000aa058"
fmt.Println("*p = ", *p)// "1"
*p = 2 // equivalent to x = 2
fmt.Println("x = ", x) // "2"
}
运行该程序会输出下面的类似结果,其中第一行输出的是存放普通变量 x 的地址,该值不固定:
p = 0xc0000aa058
*p = 1
x = 2
而这里讲的 new 函数是 Go 里的一个内建函数。
使用表达式 new(Type) 将创建一个 Type 类型的匿名变量,初始化为 Type 类型的零值,然后返回变量地址,返回的指针类型为 *Type 。
package main
import (
"fmt"
)
func main() {
p := new(int) // p, *int 类型, 指向匿名的 int 变量
fmt.Println("*p = ", *p)// 匿名的 int 变量零值为 "0"
*p = 2 // 设置 int 匿名变量的值为 2
fmt.Println("*p = ", *p)// "2"
}
该程序输出如下:
*p = 0
*p = 2
用 new 创建变量除了不需要声明一个临时变量的名字外,和普通变量声明语句方式创建变量没有什么区别。
第六种 :make 函数创建 slice、map 或 chan 类型变量
在 Go 语言中可以使用 make 函数创建 slice、map 或 chan 类型变量:
var mySlice = make([]int, 8)
var myMap = make(map[string]int)
var myChan = make(chan int)
slice、map 和 chan 是 Go 中的引用类型,它们的创建和初始化,一般使用 make。特别的, chan 只能用 make 。slice 和 map 还可以简单的方式:
mySlice := []int{0, 0}
myMap := map[string]int{}
特别注意
变量或者常量都只能声明一次,特别注意短声明,例如下面的示例, a 和 b 都已经使用短声明了,再使用一次短声明就是错误的。但是,如果短声明中仅有一些变量在相同的词法域声明过了,那么短变量声明语句对这些已经声明过的变量就只有赋值行为。
a, b := 1, 2
...
a, b := 1, 3 // error
a, b = 1, 3 // ok
a, c := 1, 3 // ok
当然, 匿名变量 (也称作占位符,或者空白标识符,用下划线表示)可以声明多次。匿名变量有三个优点:
- 不分配内存,不占用内存空间
- 不需要你为命名无用的变量名而纠结
- 多次声明不会有任何问题
通常我们用匿名接收 必须接收,但是又不会用到的值 ,例如:
// array of 3 integers
var a [3]int
// Print the elements only.
for _, v := range a {
fmt.Printf("%d\n", v)
}
变量的生命周期
变量的生命周期指的是在程序运行期间变量有效存在的时间段。对于在包一级声明的变量来说,它们的生命周期和整个程序的运行周期是一致的。而相比之下,局部变量的生命周期则是从创建的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收。函数的参数变量和返回值变量都是局部变量。它们在函数每次被调用的时候创建。
一个循环迭代内部的局部变量的生命周期可能超出其局部作用域。同时,局部变量可能在函数返回之后依然存在。
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用 var 还是 new 声明变量的方式决定的。
Go 语言系列3:常量
在 Go 语言中, 常量 表示的是固定的值,常量表达式的值在编译期进行计算,常量的值不可以修改。例如: 3 、 Let's go 、 3.14 等等。常量中的数据类型只可以是 布尔型 、 数字型 (整数型、浮点型和复数)和 字符串型 。
常量的声明
常量的声明使用关键字 const :
const <name> <type> = <expression>
const <name> = <expression>
多个相同类型的声明可以写成:
const <name1>, <name2> = <expression1>, <expression2>
下面是一个声明常量的例子:
package main
import "fmt"
func main() {
const a int = 10
const b = "Let's go"
fmt.Println("a = ", a)
fmt.Println("b = ", b)
// a = 12 // error
}
运行该程序输出如下:
a = 10
b = Let's go
因为常量不能修改,如果把最后一行的注释去掉,编译会出错。
下面的例子,因为函数调用发生在运行时,所以不能将函数的返回值赋值给常量。
package main
import (
"fmt"
"math"
)
func main() {
var a = math.Abs(-1.2)
// const b = math.Abs(-3.1) // error
fmt.Println(a)
}
当然,和变量声明一样,常量也可以一组一起声明,这比较适合声明一组相关的常量:
const (
e = 2.71828182845904523536028747135266249775724709369995957496696763
pi = 3.14159265358979323846264338327950288419716939937510582097494459
)
如果是一次声明一组常量,除了第一个外,其它常量右边的初始化表达式都可以省略,如果省略初始化表达式则表示使用前面常量的初始化表达式写法,对应的常量类型也一样的。例如:
package main
import (
"fmt"
)
const (
num1 = 1
num2
num3 = 2
num4
)
func main() {
fmt.Println("num1 = ", num1)
fmt.Println("num2 = ", num2)
fmt.Println("num3 = ", num3)
fmt.Println("num4 = ", num4)
}
上面的程序输出为:
num1 = 1
num2 = 1
num3 = 2
num4 = 2
同样的,一组常量一起声明可以用作枚举:
const (
Monday = 1
Tuesday = 2
Wednesday = 3
Thursday = 4
Friday = 5
Saturday = 6
Sunday = 7
)
当然,后面还有更好的枚举写法。
常量间的所有算术运算、逻辑运算和比较运算的结果也是常量,对常量的类型转换操作或以下函数调用都是返回常量结果: len() 、 cap() 、 real() 、 imag() 、 complex() 和 unsafe.Sizeof() 。注意在常量表达式中,函数必须是内置函数,否则编译不通过。
package main
import (
"fmt"
"unsafe"
)
func main() {
const (
a = "Let's go"
length = len(a)
size = unsafe.Sizeof(a)
)
fmt.Println("a = ", a)
fmt.Println("length = ", length)
fmt.Println("size = ", size)
}
上面程序的输出结果如下:
a = Let's go
length = 8
size = 16
当然,你可能对最后一行的输出有些疑惑,为什么 size 大小是 16 ,这里解释一下, size 指的是类型的大小,此处为字符串类型大小,字符串类型在 Go 中是一个结构,包含指向底层数组的指针和长度,这两部分每部分都是 8 个字节,所以字符串类型大小为 16 个字节,所以输出为 16 。
无类型常量
Go 中的常量有个不同寻常之处。虽然一个常量可以有任意一个确定的基础类型,但是许多常量并没有一个明确的基础类型。这里有六种未明确类型的常量类型,分别是 无类型的布尔型 、 无类型的整数 、 无类型的字符 、 无类型的浮点数 、 无类型的复数 、 无类型的字符串 。
iota 常量生成器
iota 特殊常量,可以认为是一个可以被编译器修改的常量。常量声明可以使用 iota 常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。在一个 const 声明语句中,在第一个声明的常量所在的行, iota 将会被置为 0 ,然后在每一个有常量声明的行加一。 iota 可以被用作枚举值:
package main
import (
"fmt"
)
const (
Sunday int = iota
Monday
Tuesday
)
func main() {
fmt.Println("Sunday = ", Sunday)
fmt.Println("Monday = ", Monday)
fmt.Println("Tuesday = ", Tuesday)
}
上面的程序输出为:
Sunday = 0
Monday = 1
Tuesday = 2
如果出现另一个 const 声明语句, iota 将会重新置为 0 :
package main
import (
"fmt"
)
const (
a = iota // iota = 0
b // iota = 1
c // iota = 2
d = "go" // go, iota = 3
e // 和上一行一样为 go, iota = 4
f = 100 // 100, iota = 5
g // 和上一行一样为 100, iota = 6
h = iota // iota = 7
i // iota = 8
)
const (
j = iota // iota 重新计数, iota = 0
k // iota = 1
)
func main() {
fmt.Println("a = ", a)
fmt.Println("b = ", b)
fmt.Println("c = ", c)
fmt.Println("d = ", d)
fmt.Println("e = ", e)
fmt.Println("f = ", f)
fmt.Println("g = ", g)
fmt.Println("h = ", h)
fmt.Println("i = ", i)
fmt.Println("j = ", j)
fmt.Println("k = ", k)
}
程序输出如下:
a = 0
b = 1
c = 2
d = go
e = go
f = 100
g = 100
h = 7
i = 8
j = 0
k = 1
Go 语言系列4:整型
在 Go 语言中,整型可以细分成两个种类十个类型。
有符号整型:
int8 :表示 8 位有符号整型;其类型宽度为 8 位,即 1 字节,表示范围: -128 ~ 127 。
int16 :表示 16 位有符号整型;其类型宽度为 16 位,即 2 字节,表示范围: -32768 ~ 32767 。
int32 :表示 32 位有符号整型;其类型宽度为 32 位,即 4 字节,表示范围: -2147483648 ~ 2147483647 。
int64 :表示 64 位有符号整型;其类型宽度为 64 位,即 8 字节,表示范围: -9223372036854775808 ~ 9223372036854775807 。
int :根据不同的底层平台(Underlying Platform),表示 32 或 64 位整型。除非对整型的大小有特定的需求,否则你通常应该使用 int 表示整型。其类型宽度在 32 位系统下是 32 位,而在 64 位系统下是 64 位。表示范围:在 32 位系统下是 -2147483648 ~ 2147483647 ,而在 64 位系统是 -9223372036854775808 ~ 9223372036854775807 。
package main
import (
"fmt"
"math"
"unsafe"
)
func main() {
var num8 int8 = 127
var num16 int16 = 32767
var num32 int32 = math.MaxInt32
var num64 int64 = math.MaxInt64
var num int = math.MaxInt
fmt.Printf("type of num8 is %T, size of num8 is %d, num8 = %d\n",
num8, unsafe.Sizeof(num8), num8)
fmt.Printf("type of num16 is %T, size of num16 is %d, num16 = %d\n",
num16, unsafe.Sizeof(num16), num16)
fmt.Printf("type of num32 is %T, size of num32 is %d, num32 = %d\n",
num32, unsafe.Sizeof(num32), num32)
fmt.Printf("type of num64 is %T, size of num64 is %d, num64 = %d\n",
num64, unsafe.Sizeof(num64), num64)
fmt.Printf("type of num is %T, size of num is %d, num = %d\n",
num, unsafe.Sizeof(num), num)
}
其中,程序中的 Printf 方法,可以使用 %T 格式说明符(Format Specifier)打印出变量的类型。而 unsafe 包的 Sizeof 函数接收变量并返回它的字节大小。使用 unsafe 包可能会带来可移植性问题,这里只是作为演示使用。如果你将 num8 的值改为 128 运行后就会报错,因为 int8 类型的最大值为 127 。该程序运行后输出如下:
type of num8 is int8, size of num8 is 1, num8 = 127
type of num16 is int16, size of num16 is 2, num16 = 32767
type of num32 is int32, size of num32 is 4, num32 = 2147483647
type of num64 is int64, size of num64 is 8, num64 = 9223372036854775807
type of num is int, size of num is 8, num = 9223372036854775807
无符号整型:
uint8 :表示 8 位无符号整型;其类型宽度为 8 位,即 1 字节,表示范围: 0 ~ 255 。
uint16 :表示 16 位无符号整型;其类型宽度为 16 位,即 2 字节,表示范围: 0 ~ 65535 。
uint32 :表示 32 位无符号整型;其类型宽度为 32 位,即 4 字节,表示范围: 0 ~ 4294967295 。
uint64 :表示 64 位无符号整型;其类型宽度为 64 位,即 8 字节,表示范围: 0 ~ 18446744073709551615 。
uint :根据不同的底层平台,表示 32 或 64 位无符号整型。其类型宽度在 32 位系统下是 32 位,而在 64 位系统下是 64 位。表示范围在 32 位系统下是 0 ~ 4294967295 ,而在 64 位系统是 0 ~ 18446744073709551615 。
package main
import (
"fmt"
"math"
"unsafe"
)
func main() {
var num8 uint8 = 128
var num16 uint16 = 32768
var num32 uint32 = math.MaxUint32
var num64 uint64 = math.MaxUint64
var num uint = math.MaxUint
fmt.Printf("type of num8 is %T, size of num8 is %d, num8 = %d\n",
num8, unsafe.Sizeof(num8), num8)
fmt.Printf("type of num16 is %T, size of num16 is %d, num16 = %d\n",
num16, unsafe.Sizeof(num16), num16)
fmt.Printf("type of num32 is %T, size of num32 is %d, num32 = %d\n",
num32, unsafe.Sizeof(num32), num32)
fmt.Printf("type of num64 is %T, size of num64 is %d, num64 = %d\n",
num64, unsafe.Sizeof(num64), num64)
fmt.Printf("type of num is %T, size of num is %d, num = %d\n",
num, unsafe.Sizeof(num), num)
}
该程序运行结果如下:
type of num8 is uint8, size of num8 is 1, num8 = 128
type of num16 is uint16, size of num16 is 2, num16 = 32768
type of num32 is uint32, size of num32 is 4, num32 = 4294967295
type of num64 is uint64, size of num64 is 8, num64 = 18446744073709551615
type of num is uint, size of num is 8, num = 18446744073709551615
uint 无符号整型和 int 有符号整型的区别就在于一个 u ,有 u 的就表示无符号,没有 u 的就表示有符号。
接下来讲讲它们表示范围的差别,例如 int8 和 uint8 ,它们的类型宽度都为 8 位,能表示的数值个数为
2
8
=
256
2^{8} = 256
28=256 ,对于无符号整数来说,表示的都是正数,所以表示范围为 0 ~ 255 ,一共 256 个数。而对于有符号整数来说,就得借一位来表示符号,所以表示范围为 -128 ~ 127 ,刚好也是 256 个数。
对于 int8 , int16 等这些类型后面有跟一个数值的类型来说,它们能表示的数值个数是固定的。而对于 int , uint 这两个没有指定其大小的类型,在 32 位系统和 64 位系统下的大小是不同的。所以,在有的时候例如在二进制传输、读写文件的结构描述(为了保持文件的结构不会受到不同编译目标平台字节长度的影响)等情况下,使用更加精确的 int32 和 int64 是更好的。
不同进制的表示方法
一般我们习惯使用十进制表示法,当然,有时候我们也会使用其他进制表示一个整数。在 Go 中,以 0b 或 0B 开头的数表示 二进制 ,以 0o 或 0O 开头的数表示 八进制 ,以 0x 或 0X 开头的数表示 十六进制 。
package main
import (
"fmt"
)
func main() {
var num2 int = 0b1100011
var num8 int = 0o143
var num10 int = 99
var num16 int = 0X63
fmt.Println("num2 = ", num2)
fmt.Println("num8 = ", num8)
fmt.Println("num10 = ", num10)
fmt.Println("num16 = ", num16)
}
该程序的四个数都表示十进制的 99 ,程序运行后输出如下:
num2 = 99
num8 = 99
num10 = 99
num16 = 99
当然,你也可以使用 fmt 包的格式化输出相应的进制数。
package main
import (
"fmt"
)
func main() {
var num2 int = 0b1100011
var num8 int = 0o143
var num10 int = 99
var num16 int = 0X63
fmt.Printf("2进制数 num2 = %b\n", num2)
fmt.Printf("8进制数 num8 = %o\n", num8)
fmt.Printf("10进制数 num10 = %d\n", num10)
fmt.Printf("16进制数 num16 = %x\n", num16)
}
该程序运行后输出如下:
2进制数 num2 = 1100011
8进制数 num8 = 143
10进制数 num10 = 99
16进制数 num16 = 63
Go 语言系列5:浮点型
Go 语言提供了两种精度的浮点数: float32 和 float64 ,它们的算术规范由 IEEE754 浮点数国际标准定义。
浮点数类型的值一般由 整数 部分、小数点 . 和 小数 部分组成。其中,整数部分和小数部分均由十进制表示法表示。
不过还可以用科学计数法表示。指数部分由 E 或 e 以及一个带正负号的十进制数组成。例如 6.2E-2 表示浮点数 0.062 , 6.2E+1 表示浮点数 62 。
有时候,浮点数类型值的表示也可以被简化。例如, 66.0 可以被简化为 66 。又比如, 0.066 可以被简化为 .066 。
package main
import (
"fmt"
)
func main() {
var num1 = 6.2E-2
var num2 = 6.2E+1
var num3 float64 = 66
var num4 float64 = .066
fmt.Printf("type of num1 is %T, num1 = %f\n", num1, num1)
fmt.Printf("type of num2 is %T, num2 = %f\n", num2, num2)
fmt.Printf("type of num3 is %T, num3 = %f\n", num3, num3)
fmt.Printf("type of num4 is %T, num4 = %f\n", num4, num4)
}
该程序运行后输出如下:
type of num1 is float64, num1 = 0.062000
type of num2 is float64, num2 = 62.000000
type of num3 is float64, num3 = 66.000000
type of num4 is float64, num4 = 0.066000
float32 :即常说的单精度,存储占用 4 个字节,即 32 位,其中 1 位用来表示符号, 8 位用来表示指数,剩下的 23 位用来表示尾数。
float64 :即常说的双精度,存储占用 8 个字节,即 64 位,其中 1 位用来表示符号, 11 位用来表示指数,剩下的 52 位用来表示尾数。
精度主要取决于尾数部分的位数。
对于 float32 (单精度)来说,表示尾数部分为 23 位,除去全部为 0 的情况以外,最小为
2
−
23
2^{-23}
2−23 ,约为
1.19
∗
1
0
−
7
1.19 * 10^{-7}
1.19∗10−7 ,所以 float32 小数部分能精确到后面 6 位,加上小数点前的一位,即有效数字为 7 位。
对于 float64 (双精度)来说,表示尾数部分为 52 位,最小为
2
−
52
2^{-52}
2−52 ,约为
2.22
∗
1
0
−
16
2.22 * 10^{-16}
2.22∗10−16 ,所以 float64 小数部分能精确到后面 15 位,加上小数点前的一位,有效位数为 16 位。
常量 math.MaxFloat32 表示 float32 能取到的最大数值,大约是 3.4e38 ; float32 能表示的最小值近似为 1.4e-45 。
常量 math.MaxFloat64 表示 float64 能取到的最大数值,大约是 1.8e308 ; float64 能表示的最小值近似为 4.9e-324 。
package main
import (
"fmt"
"math"
)
func main() {
var num1 float32= math.MaxFloat32
var num2 float64 = math.MaxFloat64
fmt.Printf("type of num1 is %T, num1 = %g\n", num1, num1)
fmt.Printf("type of num2 is %T, num2 = %g\n", num2, num2)
}
该程序运行后输出如下:
type of num1 is float32, num1 = 3.4028235e+38
type of num2 is float64, num2 = 1.7976931348623157e+308
通过上面的程序,我们知道浮点数能表示的数值很大,但是浮点数的精度却没有那么大。
float32 的精度只能提供大约 6 个十进制数(表示后科学计数法后,小数点后 6 位)的精度。
float64 的精度能提供大约 15 个十进制数(表示后科学计数法后,小数点后 15 位)的精度。
例如 10000011 这个数,用 float32 的类型来表示的话,由于其有效位是 7 位,将 10000011 表示成科学计数法,就是
1.0000011
∗
1
0
7
1.0000011 * 10^{7}
1.0000011∗107 ,能精确到小数点后面 6 位。此时用科学计数法表示后,小数点后有 7 位,刚刚满足我们的精度要求,对这个数进行 +1 或者 -1 等数学运算,都能保证计算结果是精确的。
package main
import (
"fmt"
)
func main() {
var num float32= 10000011
fmt.Printf("type of num is %T\n", num)
fmt.Printf("num = %g\n", num)
fmt.Printf("num + 1 = %g\n", num + 1)
}
该程序运行后输出结果如下:
type of num is float32
num = 1.0000011e+07
num + 1 = 1.0000012e+07
可以看到结果精确,没有错误。接下来对这个数进行修改,扩展一位,即 100000111 用 float32 的类型来表示,对这个数进行 +1 运算,看看这里的结果是否正确。
package main
import (
"fmt"
)
func main() {
var num float32= 100000111
fmt.Printf("type of num is %T\n", num)
fmt.Printf("num = %f\n", num)
fmt.Printf("num + 1 = %f\n", num + 1)
fmt.Println(num == num + 1)
}
该程序运行后输出结果如下:
type of num is float32
num = 100000112.000000
num + 1 = 100000112.000000
true
你会发现,结果居然一样!而且 num == num + 1 居然为 true 。这也正是由于其类型是 float32 精度不足,导致产生的结果不精确。
在 math 包中除了提供大量常用的数学函数外,还提供了 IEEE754 浮点数标准中定义的特殊值的创建和测试: 正无穷大 和 负无穷大 ,分别用于表示太大溢出的数字和除零的结果;还有 NaN 非数,一般用于表示无效的除法操作结果 0/0 或 Sqrt(-1) 。
package main
import (
"fmt"
)
func main() {
var num float64
fmt.Printf("num = %f\n", num)
fmt.Printf("-num = %f\n", -num)
fmt.Printf("1/num = %f\n", 1/num)
fmt.Printf("-1/num = %f\n", -1/num)
fmt.Printf("num/num = %f\n", num/num)
}
该程序运行后输出如下:
num = 0.000000
-num = -0.000000
1/num = +Inf
-1/num = -Inf
num/num = NaN
函数 math.IsNaN 用于测试一个数是否为非数 NaN , math.NaN 则返回非数对应的值。虽然可以用 math.NaN 来表示一个非法的结果,但是测试一个结果是否是非数 NaN 则是充满风险的,因为 NaN 和任何数都是不相等的,因为在浮点数中, NaN 、 正无穷大 和 负无穷大 都不是唯一的,每个都有非常多种的 bit 模式表示:
package main
import (
"fmt"
"math"
)
func main() {
nan := math.NaN()
fmt.Println("nan == nan ? ", nan == nan)
fmt.Println("nan < nan ? ", nan < nan)
fmt.Println("nan > nan ? ", nan > nan)
}
所以,该程序运行后输出结果都为 false :
nan == nan ? false
nan < nan ? false
nan > nan ? false
Go 语言系列6:布尔型
关于 布尔(bool) 类型,无非就是两个值: true 或者 false 。
如果你学过 Python 就会知道真值用 True 表示,并且与 1 是相等的;而假值用 False 表示,并且与 0 相等。但是在 Go 中,真值是用 true 表示,并且 不与 1 相等;同样的,假值是用 false 表示,并且 不与 0 相等。从而在 Go 中不能像在 Python 中一样用布尔值和 0 或 1 进行比较。
所以,如果你像在 Go 中实现和 Python 类似的布尔值与 0 或 1 进行比较的功能,需要自己去实现相应的函数。下面提供了相应的两个函数供你参考。
// bool to int
func btoi(b bool) int {
if b {
return 1
}
return 0
}
// int to bool
func itob(i int) bool {
return i != 0
}
if 和 for 语句的条件部分都是布尔类型的值,并且 == 和 < 以及 > 等比较操作也会产生布尔型的值。一元操作符 ! 对应逻辑非操作,二元操作符 && 和 || 分别对应逻辑与和逻辑或操作。其中 && 的优先级比 || 高。下面是一个例子:
package main
import (
"fmt"
)
func main() {
a := true
b := false
fmt.Println("a = ", a)
fmt.Println("b = ", b)
fmt.Println("true && false = ", a && b)
fmt.Println("true || false = ", a || b)
}
该程序输出如下:
a = true
b = false
true && false = false
true || false = true
其中 a 赋值为 true , b 赋值为 false 。 a && b 仅当 a 和 b 都为 true 时,操作符 && 才返回 true 。 a || b 仅当 a 或者 b 为 true 时,操作符 || 返回 true 。
Go 语言系列7:字符串
在 Go 语言中, 字符串(string) 是一个不可改变的字节序列。 Go 中的字符串是兼容 Unicode 编码的,并且使用 UTF-8 进行编码。文本字符串通常被解释为采用 UTF8 编码的 Unicode 码点(rune)序列。字符串的定义使用下面的语句:
var str string = "Let's Go"
获取字符串字节数目
内置的 len 函数可以返回一个字符串中的字节数目,索引操作 str[i] 返回第 i 个字节的字节值, i 必须满足 0 ≤ i< len(str) 条件约束。如果试图访问超出字符串索引范围的字节将会导致 panic 异常。
package main
import "fmt"
func main() {
str := "Let's go"
fmt.Println("len(str) = ", len(str))
fmt.Println("s[0] = ", str[0])
fmt.Println("s[1] = ", str[1])
}
运行后输出如下:
len(str) = 8
s[0] = 76
s[1] = 101
其中 ASCII 码值 76 对应的字符为 L , ASCII 码值 101 对应的字符为 e 。
获取字符串的长度
unicode/utf8 包中的 RuneCountInString 方法用来获取字符串的长度。这个方法传入一个字符串参数然后返回字符串中的 rune 的数量。
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
str1 := "Let's go"
str2 := "你好世界"
fmt.Printf("length of %s is %d\n", str1, utf8.RuneCountInString(str1))
fmt.Printf("length of %s is %d\n", str2, utf8.RuneCountInString(str2))
}
上面程序的输出结果是:
length of Let's go is 8
length of 你好世界 is 4
获取字符串的每一个字节
我们可以通过循环的方式获取字符串中的每一个字节。
package main
import "fmt"
func main() {
str1 := "Let's go"
for i := 0; i < len(str1); i++ {
fmt.Printf("str1[%d] = %c\n", i, str1[i])
}
str2 := "你"
for i := 0; i < len(str2); i++ {
fmt.Printf("str2[%d] = %c\n", i, str2[i])
}
}
运行上面的程序你会看到字符串 str1 正常输出了每个字符。但是字符串 str2 虽然只有一个中文字符,却输出了三行。如下:
str1[0] = L
str1[1] = e
str1[2] = t
str1[3] = '
str1[4] = s
str1[5] =
str1[6] = g
str1[7] = o
str2[0] = ä
str2[1] = ½
str2[2] =
这是为什么呢?其实,一个中文字符是用 UTF-8 进行编码的,一个中文字符占用了三个字节,所以在打印输出时会打印三行。那么我们应该如何解决这个问题呢?答案是使用 rune 。
rune
rune 是 Go 中的内建类型,也是 int32 的别称。其代表一个 代码点 ,代码点无论占用多少个字节,都可以用一个 rune 来表示。下面我们就通过 rune 来打印字符。
package main
import "fmt"
func main() {
str2 := "你好,世界"
runes := []rune(str2)
for i := 0; i < len(runes); i++ {
fmt.Printf("runes[%d] = %c\n", i, runes[i])
}
}
程序运行后输出如下:
runes[0] = 你
runes[1] = 好
runes[2] = ,
runes[3] = 世
runes[4] = 界
字符串的 for range 循环
上面的例子可以用一种更加简单的方法来做到字符串的遍历。那就是使用 for range 循环。
package main
import "fmt"
func main() {
str2 := "你好,世界"
for index, word := range str2{
fmt.Printf("%c starts at byte %d\n", word, index)
}
}
该程序运行后输出如下,从中我们可以看到每个中文字符占了三个字节。
你 starts at byte 0
好 starts at byte 3
, starts at byte 6
世 starts at byte 9
界 starts at byte 12
用字节切片构造字符串
package main
import "fmt"
func main() {
byteSlice := []byte{0x4c, 0x65, 0x74, 0x27, 0x73, 0x20, 0x67, 0x6f}
str := string(byteSlice)
fmt.Println(str)
}
该程序中的 byteSlice 包含字符串 Let's go 编码后的十六进制字节,程序输出如下:
Let's go
子字符串操作
子字符串操作 str[i:j] 基于原始的 str 字符串的第 i 个字节开始到第 j 个字节(并不包含 j 本身)生成一个新字符串。生成的新字符串将包含 j-i 个字节。同样,如果索引超出字符串范围或者 j 小于 i 的话将导致 panic 异常。不管 i 还是 j 都可能被忽略,当它们被忽略时将采用 0 作为开始位置,采用 len(s) 作为结束的位置。上面的这些机制其实都和 Python 中的字符串切片一致。
str := "Let's go"
fmt.Println(str[:]) // Let's go
fmt.Println(str[0:3]) // Let
fmt.Println(str[:5]) // Let's
fmt.Println(str[6:]) // go
Go 语言系列8:复数
在 Go 语言中提供了两种精度的 复数 类型: complex64 和 complex128 ,分别对应 float32 和 float64 两种浮点数精度。内置的 complex 函数用于构建复数,内建的 real 和 imag 函数分别返回复数的实部和虚部:
package main
import "fmt"
func main() {
var x complex64 = complex(1, 2)
var y complex128 = complex(3, 4)
var z complex128 = complex(5, 6)
fmt.Println("x = ", x)
fmt.Println("y = ", y)
fmt.Println("z = ", z)
fmt.Println("real(x) = ", real(x))
fmt.Println("imag(x) = ", imag(x))
fmt.Println("y * z = ", y * z)
}
该程序运行后输出如下:
x = (1+2i)
y = (3+4i)
z = (5+6i)
real(x) = 1
imag(x) = 2
y * z = (-9+38i)
当然,我们可以对声明进行简化,使用自然的方式书写复数:
x := 1 + 2i
y := 3 + 4i
z := 5 + 6i
如果一个浮点数面值或一个十进制整数面值后面跟着一个 i ( 1i 的 1 不能省略),它将构成一个复数的虚部,复数的实部是 0 :
fmt.Println(5i) // (0+5i)
math/cmplx 包提供了复数处理的许多函数,例如:
x := -1 + 0i
fmt.Println(cmplx.Abs(x)) // 1
fmt.Println(cmplx.Asin(x)) // (-1.5707963267948966+0i)
fmt.Println(cmplx.Sqrt(x)) // (0+1i)
fmt.Println(cmplx.Phase(x)) // 3.141592653589793
fmt.Println(cmplx.Polar(x)) // 1 3.141592653589793
Go 语言系列9:byte 和 rune
byte ,只占用 1 个字节,即 8 位,其别名为 uint8 ,表示的是 ASCII 码表中的一个字符。下面的例子分别用 byte 和 uint8 定义了变量 x 和 y 。
package main
import "fmt"
func main() {
var x byte = 65
var y uint8 = 65
fmt.Printf("x = %c\n", x) // x = A
fmt.Printf("y = %c\n", y) // y = A
}
在 ASCII 码表中,ASCII 码值 65 所对应的字符为 A 。所以上面的程序运行后都会输出字符 A 。当然,你也可以直接写成下面的形式,结果是一样的。
var x byte = 'A'
var y uint8 = 'A'
rune ,占用 4 个字节,即 32 位,其别名为 uint32 ,表示的是一个 Unicode 字符。
package main
import (
"fmt"
"unsafe"
)
func main() {
var x byte = 65
fmt.Printf("x = %c\n", x)
fmt.Printf("x 占用 %d 个字节\n", unsafe.Sizeof(x))
var y rune = 'A'
fmt.Printf("y = %c\n", y)
fmt.Printf("y 占用 %d 个字节\n", unsafe.Sizeof(y))
}
该程序运行后输出如下:
x = A
x 占用 1 个字节
y = A
y 占用 4 个字节
由此我们知道, byte 类型只能表示 2 8 = 256 2^{8} = 256 28=256 个值,所以你想表示其他一些值,例如中文的话,就得使用 rune 类型。
var y rune = '我'
这里也许你不会注意到一个问题,那就是上面定义使用的都是 单引号 。在 Go 中,单引号和双引号是不同的, 单引号 只是用来表示 字符 ,而 双引号 表示 字符串 ,所以平时在使用的时候一定要注意定义的是字符还是字符串。
Go 语言系列10:数组
数组 是一个由 固定长度 的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。因为数组的长度是固定的,因此在 Go 语言中很少直接使用数组。和数组对应的类型是 slice(切片) ,它是可以增长和收缩的动态序列, slice 功能也更灵活,下一期我们再讨论 slice 。
声明数组
可以使用 [n]Type 来声明一个数组。其中 n 表示数组中元素的数量, Type 表示每个元素的类型。
var arr [5]int
上面的语句声明了一个长度为 5 的整型数组,因为声明时没有指定数组元素的值,所以数组中的每个元素都会被自动初始化对应类型的零值,对应整型数组来说,零值为 0 ,因此数组 arr 中所有元素的值都为 0 。我们可以通过索引对数组中的元素赋值。
var arr [5]int
arr[0] = 15
arr[1] = 20
arr[2] = 25
arr[3] = 30
arr[4] = 35
fmt.Println(arr)
运行该程序会输出 [15 20 25 30 35] 。
当然,也可以直接在声明时对数组进行初始化。
var arr = [5]int{15, 20, 25, 30, 35}
或者直接用短声明:
arr := [5]int{15, 20, 25, 30, 35}
当然,如果你只想给数组前面的某几个元素赋值也是可以的,其他没被赋值的元素会被自动赋值为类型对应的零值。例如:
arr := [5]int{15, 20} // [15 20 0 0 0]
有时要初始化数组的元素个数太多,我们可以不计算数组元素的个数,直接使用 ... 让编译器为我们计算该数组的长度。
arr := [...]int{15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70}
我们也可以通过指定索引,方便地对数组某几个元素赋值:
arr := [5]int{1:100, 4:200}
fmt.Println(arr) // [0 100 0 0 200]
特别注意数组的长度是类型的一部分,所以 [3]int 和 [5]int 是不同的类型。
package main
import "fmt"
func main() {
arr1 := [3]int{15, 20, 25}
arr2 := [5]int{15, 20, 25, 30, 35}
fmt.Printf("type of arr1 is %T\n", arr1)
fmt.Printf("type of arr2 is %T\n", arr2)
}
运行该程序输出如下:
type of arr1 is [3]int
type of arr2 is [5]int
获取数组的长度
使用内置的 len 函数将返回数组中元素的个数,即数组的长度。
arr := [...]int{15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70}
fmt.Println(len(arr)) // 12
数组是值类型
Go 中的数组是值类型而不是引用类型。当数组赋值给一个新的变量时,该变量会得到一个原始数组的一个副本。如果对新变量进行更改,不会影响原始数组。
arr := [3]int{15, 20, 25}
copy := arr
copy[0] = 10
fmt.Println(arr) // [15 20 25]
fmt.Println(copy) // [10 20 25]
同理,当数组作为参数传递给函数时,它们是按值传递,原始数组保持不变。
package main
import "fmt"
func change(array [3]int) {
array[0] = 0
fmt.Println("array in func = ", array)
}
func main() {
arr := [3]int{15, 20, 25}
change(arr)
fmt.Println("arr in main = ", arr)
}
运行该程序会输出:
array in func = [0 20 25]
arr in main = [15 20 25]
获取数组元素
使用 for range 循环可以获取数组每个索引以及索引上对应的元素。
package main
import "fmt"
func main() {
arr := [3]int{15, 20, 25}
for index, value := range arr {
fmt.Printf("arr[%d] = %d\n", index, value)
}
}
运行该程序输出如下:
arr[0] = 15
arr[1] = 20
arr[2] = 25
当然,如果你只想获得元素的值而忽略索引值,可以采用我们之前讲过的空白标识符来代替索引:
for _, value := range arr {...}
多维数组
和你见过的其他语言一样,在 Go 中也可以定义多维数组。
arr := [3][2]string{
{"15", "20"},
{"25", "22"},
{"25", "22"}}
fmt.Println(arr) // [[15 20] [25 22] [25 22]]
Go 语言系列11:切片
Slice(切片) 代表变长的序列,序列中每个元素都有相同的类型。一个 slice 类型一般写作 []Type ,其中 Type 代表 slice 中元素的类型; slice 的语法和数组很像,只是没有固定长度而已。 slice 本身不拥有任何数据,它们只是对现有数组的引用,每个切片值都会将数组作为其底层数据结构。
切片是对数组的一个连续片段的引用,所以切片是一个引用类型,这个片段可以是整个数组,也可以是由起始和终止索引标识的一些项的子集。
创建切片
使用 []Type 可以创建一个带有 Type 类型元素的切片。
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
当然,我们可以通过对数组进行片段截取创建一个切片。
arr := [5]int{10, 20, 30, 40, 50}
var numList = arr[1:4]
fmt.Println(arr) // [10 20 30 40 50]
fmt.Println(numList) // [20 30 40]
注意,使用语法 arr[start:end] 是创建一个从 arr 数组索引 start 开始到 end - 1 结束的切片,区间左闭右开。因此,在上面的例子中, arr[1:4] 从索引 1 到 3 创建了 arr 数组的一个切片。因此,切片 numList 的值为 [20 30 40] 。
你也可以使用 make 函数构造一个切片,格式为 make([]Type, size, cap) 。
numList := make([]int, 3, 5)
上面的例子创建了一个长度为 3 ,容量为 5 的切片,其中的每个元素都为整型。
切片的长度和容量
一个 slice 由三个部分构成: 指针 、 长度 和 容量 。指针指向第一个 slice 元素对应的底层数组元素的地址,要注意的是 slice 的第一个元素并不一定就是数组的第一个元素。长度对应 slice 中元素的数目;长度不能超过容量,容量一般是从 slice 的开始位置到底层数据的结尾位置。简单的讲,容量就是从创建切片索引开始的底层数组中的元素个数,而长度是切片中的元素个数。
内置的 len 和 cap 函数分别返回 slice 的长度和容量。
numList := make([]int, 3, 5)
fmt.Println(len(numList)) // 3
fmt.Println(cap(numList)) // 5
如果切片操作超出 cap(numList) 的上限将导致一个 panic 异常,但是超出 len(numList) 则是意味着扩展了 slice ,因为新 slice 的长度会变大。
numList := make([]int, 3, 5)
numListEx := numList[:5]
fmt.Println(numList) // [0 0 0]
fmt.Println(numListEx) // [0 0 0 0 0]
由于 slice 是引用类型,所以你不对它进行赋值的话,它的默认值是 nil 。
var numList []int
fmt.Println(numList == nil) // true
切片之间不能比较,因此我们不能使用 == 操作符来判断两个 slice 是否含有全部相等元素。不过标准库提供了高度优化的 bytes.Equal 函数来判断两个字节型 slice 是否相等([]byte),但是对于其他类型的 slice ,我们必须自己展开每个元素进行比较。特别注意,如果你需要测试一个 slice 是否是空的,使用 len(s) == 0 来判断,而不应该用 s == nil 来判断。
切片元素的修改
切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
var arr = [...]int{10, 20, 30}
numList := arr[:]
fmt.Println(arr) // [10 20 30]
fmt.Println(numList) // [10 20 30]
numList[0] = 55
fmt.Println(arr) // [55 20 30]
fmt.Println(numList) // [55 20 30]
这里的 arr[:] 没有填入起始值和结束值,默认就是 0 和 len(arr) 。
追加切片元素
使用 append 可以将新元素追加到切片上。 append 函数的定义是 func append(slice []Type, elems ...Type) []Type 。其中 elems ...Type 在函数定义中表示该函数接受参数 elems 的个数是可变的。这些类型的函数被称为可变函数。
numList := []int{1, 2}
// 追加一个元素 3
numList = append(numList, 3)
// 追加两个元素 4 5
numList = append(numList, 4, 5)
// 追加一个切片 ... 表示解包不能省略
numList = append(numList, []int{6, 7}...)
// 在第一个位置插入一个元素 0
numList = append([]int{0}, numList...)
fmt.Println(numList) // [0 1 2 3 4 5 6 7]
当新的元素被添加到切片时,会创建一个新的数组。现有数组的元素被复制到这个新数组中,并返回这个新数组的新切片引用。现在新切片的容量是旧切片的两倍。
多维切片
类似于数组,切片也可以有多个维度。
numList := [][]string {
{"1", "10"},
{"2", "20"},
{"3", "30"}}
Go 语言系列12:Map
Map 是在 Go 中将 键(key) 与 值(value) 关联的内置类型。通过相应的键可以获取到值。它是哈希表的一个实现,这就要求它的每个映射里的 key ,都是唯一的。可以使用 == 和 != 来进行判等操作。所有可比较的类型,如 boolean , interger , float , complex , string 等,都可以作为 key 。
创建 Map
使用 make 函数传入键和值的类型,可以创建 map 。具体语法为 make(map[KeyType]ValueType) 。
scores := make(map[string]int)
上面的例子使用了 make 函数创建了一个键类型为 string 值类型为 int 名为 scores 的 map 。
我们也可以用 map 字面值的语法创建 map ,同时还可以指定一些最初的 key/value :
var scores map[string]int = map[string]int{
"chinese": 80,
"english": 90,
}
或者
scores := map[string]int{
"chinese": 80,
"english": 90,
}
添加元素
可以使用 map[key] = value 向 map 添加元素。
scores["math"] = 100
更新元素
若 key 已存在,使用 map[key] = value 可以直接更新对应 key 的 value 值。
scores["math"] = 90
获取元素
直接使用 map[key] 即可获取对应 key 的 value 值 ,如果 key 不存在,会返回其 value 类型的零值。
fmt.Println(scores["math"])
删除元素
使用 delete(map, key) 可以删除 map 中的对应 key 键值对,如果 key 不存在, delete 函数会静默处理,不会报错。
delete(scores, "math")
判断 key 是否存在
如果我们想知道 map 中的某个 key 是否存在,可以使用下面的语法:
value, ok := map[key]
这个语句说明 map 的下标读取可以返回两个值,第一个值为当前 key 的 value 值,第二个值表示对应的 key 是否存在,若存在 ok 为 true ,若不存在,则 ok 为 false 。
遍历 map
遍历 map 中所有的元素需要用 for range 循环。
如果要获取 map 中的 key 和 value :
for key, value := range scores {
fmt.Printf("key: %s, value: %d\n", key, value)
}
如果只要获取 key :
for key := range scores {
fmt.Printf("key: %s\n", key)
}
如果只要获取 value :
for _, value := range scores {
fmt.Printf("value: %d\n", value)
}
获取 map 长度
使用 len 函数可以获取 map 长度。
package main
import "fmt"
func main() {
scores := map[string]int{
"chinese": 80,
"english": 90,
"math": 100,
}
fmt.Println(len(scores)) // 3
}
map 是引用类型
当 map 被赋值为一个新变量的时候,它们指向同一个内部数据结构。因此,改变其中一个变量,就会影响到另一变量。
package main
import "fmt"
func main() {
scores := map[string]int{
"chinese": 80,
"english": 90,
"math": 100,
}
fmt.Println("scores: ", scores)
// scores: map[chinese:80 english:90 math:100]
newScores := scores
newScores["chinese"] = 10
newScores["english"] = 55
newScores["math"] = 50
fmt.Println("scores: ", scores)
// scores: map[chinese:10 english:55 math:50]
fmt.Println("newScores: ", newScores)
// newScores: map[chinese:10 english:55 math:50]
}
当 map 作为函数参数传递时也会发生同样的情况。
检查 map 是否为 nil
map 之间不能用 == 操作符判断是否相等,但能使用它来判断 map 是否为 nil 。要判断两个 map 是否包含相同的 key 和 value ,我们必须通过一个循环实现。
package main
import "fmt"
func main() {
var scores map[string]int
if scores == nil {
fmt.Println("nil")
}
}
运行上面的程序会输出 nil 。
Go 语言系列13:指针
指针 是一种存储变量内存地址的变量,简单点讲就是地址变量,地址变量存放的是地址,通过该地址我们能获取该地址存放的数据。例如,下图所示。
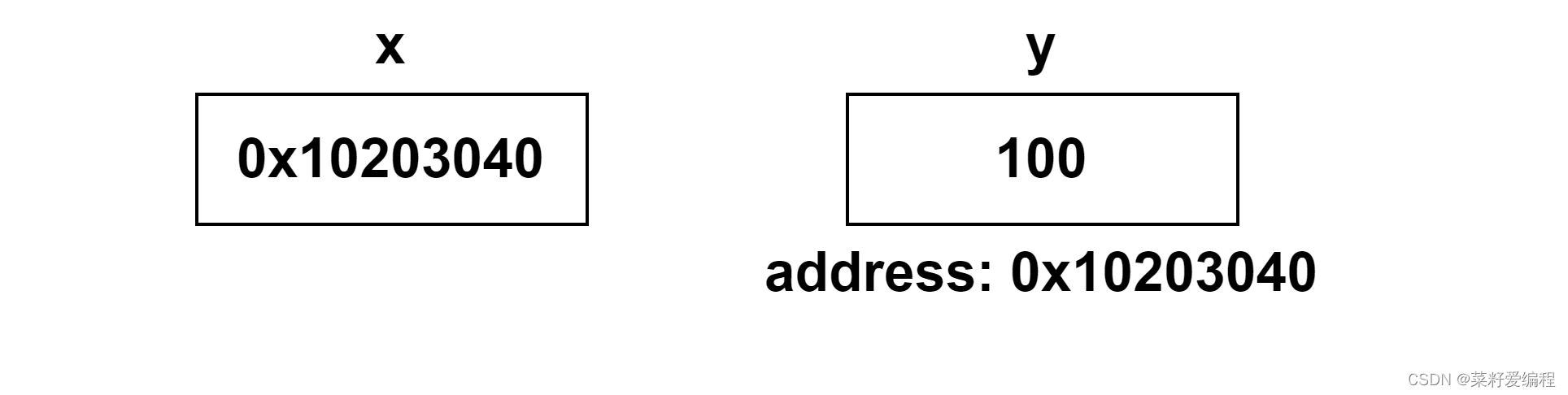
变量 y 的值为 100 ,而变量 y 的内存地址为 0x10203040 。变量 x 存储的是变量 y 的地址,即 0x10203040 ,所以我们称 x 指向了 y , x 变量为指针变量,简称指针。
创建指针
指针变量的类型为 *Type ,该指针指向一个 Type 类型的变量。创建指针有三种方法。
第一种方法
首先定义普通变量,再通过获取该普通变量的地址创建指针:
// 定义普通变量 x
x := 100
// 取普通变量 x 的地址创建指针 p
p := &x
第二种方法
先创建指针并分配好内存,再给指针指向的内存地址写入对应的值:
// 创建指针
p := new(int)
// 给指针指向的内存地址写入对应的值
*p = 100
第三种方法
首先声明一个指针变量,再从其他变量获取内存地址给指针变量:
// 定义变量 x
x := 100
// 声明指针变量
var p *int
// 指针初始化
p = &x
上面举的创建指针的三种方法对学过 C 语言的人来说可能很简单,但没学过指针相关知识的人可能不太明白,特别是上面代码中出现的指针操作符 & 和 * 。
&操作符可以从一个变量中取到其内存地址。*操作符如果在赋值操作值的左边,指该指针指向的变量;*操作符如果在赋值操作符的右边,指从一个指针变量中取得变量值,又称指针的解引用。
通过下面的例子,你应该就会比较清楚的理解上面两个指针操作符了。
package main
import "fmt"
func main() {
x := 100
p := &x
fmt.Println("x = ", x) // x = 100
fmt.Println("*p = ", *p) // *p = 100
fmt.Println("&x = ", &x) // &x = 0xc0000ae058
fmt.Println("p = ", p) // p = 0xc0000ae058
}
指针的类型
*(指向变量值的数据类型) 就是对应的指针类型。
package main
import "fmt"
func main() {
mystr := "hello"
myint := 1
mybool := false
myfloat := 1.2
fmt.Printf("type of &mystr is %T\n", &mystr)
fmt.Printf("type of &myint is %T\n", &myint)
fmt.Printf("type of &mybool is %T\n", &mybool)
fmt.Printf("type of &myfloat is %T\n", &myfloat)
}
运行程序输出如下:
type of &mystr is *string
type of &myint is *int
type of &mybool is *bool
type of &myfloat is *float64
指针的零值
如果指针声明后没有进行初始化,其默认零值是 nil 。
package main
import "fmt"
func main() {
x := 100
var p *int
fmt.Println("p is ", p)
p = &x
fmt.Println("p is ", p)
}
运行程序输出如下:
p is <nil>
p is 0xc00000a098
向函数传递指针参数
在函数中对指针参数所做的修改,在函数返回后会保存相应的修改。
package main
import (
"fmt"
)
func change(value *int) {
*value = 200
}
func main() {
x := 100
p := &x
fmt.Println("before execute func change *p is ", *p)
change(p)
fmt.Println("after execute func change *p is ", *p)
}
运行程序输出如下,函数传入的是指针参数,即内存地址,所以在函数内的修改是在内存地址上的修改,在函数执行后还会保留结果。
before execute func change *p is 100
after execute func change *p is 200
指针与切片
切片与指针一样是引用类型,如果我们想通过一个函数改变一个数组的值,可以将该数组的切片当作参数传给函数,也可以将这个数组的指针当作参数传给函数。但 Go 中建议使用第一种方法,即将该数组的切片当作参数传给函数,因为这么写更加简洁易读。
package main
import "fmt"
// 使用切片
func changeSlice(value []int) {
value[0] = 200
}
// 使用数组指针
func changeArray(value *[3]int) {
(*value)[0] = 200
}
func main() {
x := [3]int{10, 20, 30}
changeSlice(x[:])
fmt.Println(x)
y := [3]int{10, 20, 30}
changeArray(&y)
fmt.Println(y)
}
Go 中不支持指针运算
学过 C 语言的人肯定知道在 C 中支持指针的运算,例如: p++ ,但这在 Go 中是不支持的。
package main
func main() {
x := [...]int{20, 30, 40}
p := &x
p++ // error
}
Go 语言系列14:结构体
结构体(struct) 是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员。学过 C 或 C++ 的人都应该熟悉结构体,但在 Go 中,没有像 C++ 中的 class 类的概念,只有 struct 结构体的概念,所以也没有继承。
结构体的声明
在 Go 中使用下面的语法是对结构体的声明。
type struct_name struct {
attribute_name1 attribute_type
attribute_name2 attribute_type
...
}
例如下面是定义一个存储个人资料名为 Person 的结构体。
type Person struct {
name string
age int
gender string
}
上面的代码声明了一个结构体类型 Person ,它有 name 、 age 和 gender 三个属性。可以把相同类型的属性声明在同一行,这样可以使结构体变得更加紧凑,如下面的代码所示。
type Person struct {
name, gender string
age int
}
上面的结构体 Person 称为 命名的结构体(Named Structure) 。我们创建了名为 Person 的新类型,而它可以用于创建 Person 类型的结构体变量。
声明结构体时也可以不用声明一个新类型,这样的结构体类型称为 匿名结构体(Anonymous Structure) 。
var person struct {
name, gender string
age int
}
上面的代码创建了一个匿名结构体 person 。
创建命名的结构体
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
// 使用字段名创建结构体
per1 := Person{
name: "John",
gender: "male",
age: 18,
}
// 不使用字段名创建结构体
per2 := Person{"Mary", "female", 20}
fmt.Println("person 1 ", per1)
fmt.Println("person 2 ", per2)
}
上面的例子使用了两种方法创建了结构体,第一种是在创建结构体时使用字段名对每个字段进行初始化,而第二种方法是在创建结构体时不使用字段名,直接按字段声明的顺序对字段进行初始化。
运行该程序会输出:
person 1 {John male 18}
person 2 {Mary female 20}
创建匿名结构体
package main
import "fmt"
func main() {
// 创建匿名结构体变量
per3 := struct {
name, gender string
age int
} {
name: "John",
gender: "male",
age: 20,
}
fmt.Println("person 3 ", per3)
}
上面的程序定义了一个匿名结构体变量 per3 。运行该程序会输出:
person 3 {John male 20}
结构体的零值(Zero Value)
当定义好的结构体没有被显式初始化时,结构体的字段将会默认赋为相应类型的零值。
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
// 不初始化结构体
var per4 = Person{}
fmt.Println("person 4 ", per4)
}
上面的程序定义了 per4 ,但没有对其进行初始化,所以, name 和 gender 字段赋值为 string 类型的零值 "" ,而 age 字段赋值为 int 类型的零值 0 。运行该程序会输出:
person 4 { 0}
为结构体指定字段赋初值
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
// 为结构体指定字段赋初值
var per5 = Person{
name: "John",
gender: "male",
}
fmt.Println("person 5 ", per5)
}
上面的结构体变量 per5 只初始化了 name 和 gender 字段, age 字段没有初始化,所以会被初始化为零值。运行该程序输出如下:
person 5 {John male 0}
访问结构体的字段
点操作符 . 用于访问结构体的字段。
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
var per6 = Person{
name: "John",
gender: "male",
age: 30,
}
fmt.Println("person 6 name: ", per6.name)
fmt.Println("person 6 gender: ", per6.gender)
fmt.Println("person 6 age: ", per6.age)
}
上面的程序访问了结构体变量 per6 的每个字段,运行该程序输出如下:
person 6 name: John
person 6 gender: male
person 6 age: 30
当然,使用点操作符 . 可以用于对结构体的字段的赋值。
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
var per7 = Person{}
per7.name = "John"
per7.gender = "male"
per7.age = 30
fmt.Println("person 7 ", per7)
}
运行该程序输出如下:
person 7 {John male 30}
指向结构体的指针
package main
import "fmt"
type Person struct {
name, gender string
age int
}
func main() {
per8 := &Person{"John", "male", 30}
fmt.Println("person 8 name: ", (*per8).name)
fmt.Println("person 8 name: ", per8.name)
}
在上面的程序中, per8 是一个指向结构体 Person 的指针,上面用 (*per8).name 访问 per8 的 name 字段,上面的 per8.name 代替显式的解引用 (*per8).name 访问 per8 的 name 字段。
person 8 name: John
person 8 name: John
匿名字段
在创建结构体时,字段可以只有类型没有字段名,这种字段称为 匿名字段(Anonymous Field) 。
package main
import "fmt"
type Person struct {
string
int
}
func main() {
per9 := Person{"John", 30}
fmt.Println("person 9 ", per9)
fmt.Println("person 9 string: ", per9.string)
fmt.Println("person 9 int: ", per9.int)
}
上面的程序结构体定义了两个匿名字段,虽然这两个字段没有字段名,但其实匿名字段的名称默认就是它的类型。所以上面的结构体 Person 有两个名为 string 和 int 的字段。运行上面的程序输出如下:
person 9 {John 30}
person 9 string: John
person 9 int: 30
嵌套结构体
结构体的字段也可能是一个结构体,这样的结构体称为 嵌套结构体(Nested Structs) 。
package main
import "fmt"
type Date struct {
year int
month int
day int
}
type Person struct {
name string
age int
birthday Date
}
func main() {
per10 := Person{
name: "John",
age: 11,
}
per10.birthday = Date{
year: 2010,
month: 1,
day: 20,
}
fmt.Println("person 10 name:", per10.name)
fmt.Println("person 10 age:", per10.age)
fmt.Println("person 10 birthday year:", per10.birthday.year)
fmt.Println("person 10 birthday month:", per10.birthday.month)
fmt.Println("person 10 birthday day:", per10.birthday.day)
}
上面的程序 Person 结构体有一个字段 birthday ,而且它的类型也是一个结构体 Date ,运行该程序输出如下:
person 10 name: John
person 10 age: 11
person 10 birthday year: 2010
person 10 birthday month: 1
person 10 birthday day: 20
提升字段
结构体中如果有匿名的结构体类型字段,则该匿名结构体里的字段就称为 提升字段(Promoted Fields) 。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。就像刚刚上面的程序,如果我们把 Person 结构体中的字段 birthday 直接用匿名字段 Date 代替, Date 结构体的字段例如 year 就不用像上面那样使用 per10.birthday.year 访问,而是使用 per10.year 就能访问 Date 结构体中的 year 字段。现在结构体 Date 有 year 、 month和 day 三个字段,访问这三个字段就像在 Person 里直接声明的一样,因此我们称之为提升字段。
package main
import "fmt"
type Date struct {
year int
month int
day int
}
type Person struct {
name string
age int
Date
}
func main() {
per10 := Person{
name: "John",
age: 11,
}
per10.Date = Date{
year: 2010,
month: 1,
day: 20,
}
fmt.Println("person 10 name:", per10.name)
fmt.Println("person 10 age:", per10.age)
fmt.Println("person 10 birthday year:", per10.year)
fmt.Println("person 10 birthday month:", per10.month)
fmt.Println("person 10 birthday day:", per10.day)
}
运行上面的程序输出如下:
person 10 name: John
person 10 age: 11
person 10 birthday year: 2010
person 10 birthday month: 1
person 10 birthday day: 20
结构体比较
如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用 == 或 != 运算符进行比较。相等比较运算符 == 将比较两个结构体的每个成员,因此下面两个比较的表达式是等价的:
package main
import "fmt"
type Person struct {
name string
age int
}
func main() {
per11 := Person{
name: "John",
age: 11,
}
per12 := Person{
name: "John",
age: 11,
}
fmt.Println(per11.name == per12.name && per11.age == per12.age) // true
fmt.Println(per11 == per12) // true
}
给结构体定义方法
在 Go 中无法在结构体内部定义方法,当我们可以使用组合函数的方式来定义结构体方法。
package main
import "fmt"
// Person 定义一个名为 Person 的结构体
type Person struct {
name string
age int
}
// PrintPersonInfo 定义一个与 Person 的绑定的方法
func (person Person) PrintPersonInfo() {
fmt.Println("name:", person.name)
fmt.Println("age:", person.age)
}
func main() {
per13 := Person{
name: "John",
age: 30,
}
per13.PrintPersonInfo()
}
上面的程序中定义了一个与结构体 Person 绑定的方法 PrintPersonInfo() ,其中 PrintPersonInfo 是方法名, (person Person) 表示将此方法与 Person 的实例绑定,这里我们把 Person 称为方法的接收者,而 person 表示实例本身,相当于 Python 中的 self ,在方法内可以使用 person.attribute_name 来访问实例属性。运行该程序输出如下:
name: John
age: 30
方法的参数传递方式
如果绑定结构体的方法中要改变实例的属性时,必须使用指针作为方法的接收者。
package main
import "fmt"
// Person 定义一个名为 Person 的结构体
type Person struct {
name string
age int
}
// PrintPersonInfo 定义一个与 Person 的绑定的方法
func (person Person) PrintPersonInfo() {
fmt.Println("name:", person.name)
fmt.Println("age:", person.age)
}
// AddPersonAge 定义一个与 Person 的绑定的方法,使 age 值加 n
func (person *Person) AddPersonAge(n int) {
person.age = person.age + n
}
func main() {
per13 := Person{
name: "John",
age: 30,
}
fmt.Println("before add age")
per13.PrintPersonInfo()
per13.AddPersonAge(5)
fmt.Println("after add age")
per13.PrintPersonInfo()
}
运行该程序输出如下:
before add age
name: John
age: 30
after add age
name: John
age: 35
内部方法与外部方法
在 Go 语言中,函数名通过首字母大小写实现控制对方法的访问权限。
- 当方法的首字母为 大写 时,这个方法对于 所有包 都是 Public ,其他包可以随意调用。
- 当方法的首字母为 小写 时,这个方法是 Private ,其他包是无法访问的。
Go 语言系列15:函数
函数 是基于功能或逻辑进行封装的可复用的代码结构。将一段功能复杂、很长的一段代码封装成多个代码片段(即函数),有助于提高代码可读性和可维护性。由于 Go 语言是编译型语言,所以函数编写的顺序是无关紧要的。
函数的声明
在 Go 语言中,函数声明语法如下:
func function_name(parameter_list) (result_list) {
body
}
函数的声明使用 func 关键词,后面依次接 function_name(函数名) , parameter_list(参数列表) , result_list(返回值列表) 以及 函数体 。
- 形式参数列表描述了函数的参数名以及参数类型,这些参数作为局部变量,其值由参数调用者提供,函数中的参数列表和返回值并非是必须的。
- 返回值列表描述了函数返回值的变量名以及类型,如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的。
- 如果有连续若干个参数的类型一致,那么只需在最后一个参数后添加该类型。
package main
import "fmt"
// 函数返回一个无名变量,返回值列表的括号省略
func sum(x int, y int) int {
return x + y
}
// 无参数列表和返回值
func printHello() {
fmt.Println("Hello")
}
// 参数的类型一致,只在最后一个参数后添加该类型
func sub(x , y int) int {
return x - y
}
func main() {
fmt.Println("3 + 4 =", sum(3, 4))
printHello()
fmt.Println("5 - 2 =", sub(5, 2))
}
运行该程序输出如下:
3 + 4 = 7
Hello
5 - 2 = 3
可变参数
上面的程序参数个数都是固定的,在 Go 中我们也能像 Python 中一样实现可变参数的函数。
多个类型一致的参数
在参数类型前面加 ... 表示一个切片,用来接收调用者传入的参数。注意,如果该函数下有其他类型的参数,这些其他参数必须放在参数列表的前面,切片必须放在最后。
package main
import "fmt"
func sum(args ...int) int {
sum := 0
for _,x := range args{
sum += x
}
return sum
}
func main() {
fmt.Println(sum(3, 4, 5, 6, 7)) // 25
}
多个类型不一致的参数
如果传多个参数的类型都不一样,可以指定类型为 ...interface{} ,然后再遍历。
package main
import "fmt"
func PrintType(args ...interface{}) {
for _, arg := range args {
switch arg.(type) {
case int:
fmt.Println(arg, "type is int.")
case string:
fmt.Println(arg, "type is string.")
case float64:
fmt.Println(arg, "type is float64.")
default:
fmt.Println(arg, "is an unknown type.")
}
}
}
func main() {
PrintType(1, 3.14, "abc")
}
运行上面的程序输出如下:
1 type is int.
3.14 type is float64.
abc type is string.
解序列
使用 ... 可以用来解序列,能将函数的可变参数(即切片)一个一个取出来,传递给另一个可变参数的函数,而不是传递可变参数变量本身。
package main
import "fmt"
func sum(args ...int) int {
res := 0
for _,value := range args {
res += value
}
return res
}
func Sum(args ...int) int {
return sum(args...)
}
func main() {
fmt.Println(Sum(4, 5, 6)) // 15
}
函数的返回值
当函数没有返回值时,函数体可以使用 return 语句返回。在 Go 中一个函数可以返回多个值。
package main
import "fmt"
func RectInfo(len, width int) (int, int) {
per := 2 * (len + width)
area := len * width
return area, per
}
func main() {
area, perimeter := RectInfo(10, 5)
fmt.Printf("area = %d, perimeter = %d", area, perimeter)
}
运行该程序输出如下:
area = 50, perimeter = 30
当然,在 Go 中支持返回带有变量名的值。可以将上面的函数修改如下:
func RectInfo(len, width int) (area int, perimeter int) {
// 不使用 := 因为已经在返回值那里声明了
area = len * width
perimeter = 2 * (len + width)
// 直接返回即可
return
}
匿名函数
没有名字的函数就叫 匿名函数 ,它只有函数逻辑体,而没有函数名。匿名函数只拥有短暂的生命,一般都是定义后立即使用。
func (parameter_list) (result_list) {
body
}
Go 语言系列16:包
包(package) 用于组织 Go 源代码,提供了更好的可重用性与可读性。 Go 语言有超过 100 个的标准包,可以用 go list std | wc -l 命令查看标准包的具体数目,标准库为大多数的程序提供了必要的基础构件。
main 包
首先,我们先来看看 main 包,该包中包含一个 main() 函数,该函数是程序运行的入口。
package packagename 代码指定了某一源文件属于某一个包。它应该放在每一个源文件的第一行。例如我们 Go 的第一个程序。
// hello.go
package main
import "fmt"
func main() {
fmt.Println("Let's go!")
}
package main 这一行指定该文件属于 main 包。 import "fmt" 语句用于导入一个已存在的名为 fmt 的包。
创建包
下面我们创建自定义的 mymath 包,其中,属于某一个包的源文件都应该放置于一个单独命名的文件夹里,按照 Go 的惯例,应该用包名命名该文件夹。所以在 GoPath 的 src 目录下创建一个 mymath 文件夹,位于该目录下创建一个 mymath.go 源文件,里面实现我们自定义的数学加法函数。请注意函数名的首字母要大写。
// mymath.go
package mymath
func Add(a, b float64) float64 {
return a + b
}
导出名字(Exported Names)
我们将 mymath 包中的函数 Add 首字母大写。在 Go 中这具有特殊意义。在 Go 中,任何以大写字母开头的变量或者函数都是被导出的名字。其它包只能访问被导出的函数和变量。在这里,我们需要在 main 包中访问 Add 函数,因此会将它们的首字母大写。
如果在 mymath.go 中将函数名从 Add 变为 add ,并且在 main.go 中调用 mymath.add 函数,则该程序编译不通过。因为如果想在包外访问一个函数,它应该首字母大写。
导入包
使用包之前我们需要导入包,在 GoLand 中会帮你自动导入所需要的包。导入包的语法为 import path ,其中 path 可以是相对于工作区文件夹的相对路径,也可以是绝对路径。
package main
import (
"fmt"
"mymath"
)
func main() {
a := 10.34
b := 20.48
c := mymath.Add(a, b)
fmt.Println("c =", c) // c = 30.82
}
导入包可以单行导入也可以多行导入,像上面的程序代码就是多行导入的例子,一般我们也建议使用多行导入,当然你也可以使用单行导入:
import "fmt"
import "mymath"
使用别名
如果我们导入了两个具有同一包名的包时会产生冲突,这时我们可以为其中一个包定义别名:
import (
"crypto/rand"
mrand "math/rand" // 将名称替换为 mrand 避免冲突
)
当然,我们也可以使用别名代替名字很长的包名。
使用点操作
导入一个包后,如果要使用该包中的函数,都要使用 包名.方法名 语法进行调用,对于一些使用高频的包,例如 fmt 包,每次调用打印函数时都要使用 fmt.Println() 进行调用,很不方便。我们可以在导入包的时,使用 import . package_path 语法,将此包定义为 "自己人" ,自己人的话,不分彼此,它的方法,就是我们的方法。从此,我们打印再也不用加 fmt 了。
import . "fmt"
func main() {
Println("hello, world")
}
但这种用法,会有一定的隐患,就是导入的包里可能有函数,会和我们自己的函数发生冲突。
包的初始化
每个包都允许有一个或多个 init 函数, init 函数不应该有任何返回值类型和参数,在代码中也不能显式调用它,当这个包被导入时,就会执行这个包的 init 函数,做初始化任务, init 函数优先于 main 函数执行。该函数形式如下:
func init() {
}
包的初始化顺序:首先初始化 包级别(Package Level) 的变量,紧接着调用 init 函数。包可以有多个 init 函数(在一个文件或分布于多个文件中),它们按照编译器解析它们的顺序进行调用。如果一个包导入了另一个包,会先初始化被导入的包。尽管一个包可能会被导入多次,但是它只会被初始化一次。
包的匿名导入
之前说过,导入一个没有使用的包编译会报错。但有时候我们只是想执行包里的 init 函数来执行一些初始化任务的话应该怎么办呢?
我们可以使用匿名导入的方法,使用 空白标识符(Blank Identifier) :
import _ "fmt"
由于导入时会执行该包里的 init 函数,所以编译仍会将此包编译到可执行文件中。
Go 语言系列17:条件语句
在 Go 中 条件语句模型 如下:
if condition 1 {
branch 1
} else if condition 2 {
branch 2
} else if condition ... {
branch ...
} else {
branch else
}
如果分支的 condition 为真,则执行该分支 { 和 } 之间的代码。在 Go 中,对于 { 和 } 的位置有严格的要求,它要求 else if (或 else ) 和两边的花括号,必须在同一行。特别注意,即使在 { 和 } 之间只有一条语句,这两个花括号也是不能省略的。
单分支判断
只有一个 if 为单分支判断:
score := 88
if score >= 60 {
fmt.Println("成绩及格")
}
两分支判断
有 if 和一个 else 为两分支判断:
score := 88
if score >= 60 {
fmt.Println("成绩及格")
} else {
fmt.Println("成绩不及格")
}
多分支判断
有 if 、 else if 以及 else 为多分支判断:
score := 88
if score >= 90 {
fmt.Println("成绩等级为A")
} else if score >= 80 {
fmt.Println("成绩等级为B")
} else if score >= 70 {
fmt.Println("成绩等级为C")
} else if score >= 60 {
fmt.Println("成绩等级为D")
} else {
fmt.Println("成绩等级为E 成绩不及格")
}
条件语句高级写法
if 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在条件判断之前运行。它的语法是:
if statement; condition {
}
上面单分支判断的那个例子可以重写如下:
if score := 88; score >= 60 {
fmt.Println("成绩及格")
}
Go 语言系列18:选择语句
在 Go 选择语句模型 如下:
switch expression {
case expression 1:
code
case expression 2:
code
case expression 3:
code
case expression ...:
code
default:
code
}
switch 语句是一个选择语句,用于将 switch 后的表达式的值与可能匹配的选项 case 后的表达式进行比较,并根据匹配情况执行相应的代码块,执行完匹配的代码块后,直接退出 switch-case 。如果没有任何一个匹配,就会执行 default 的代码块。它可以被认为是替代多个 if-else 子句的常用方式。注意: case 不允许出现重复项。例如,下面的例子会输出 Your score is between 80 and 90. 。
grade := "B"
switch grade {
case "A":
fmt.Println("Your score is between 90 and 100.")
case "B":
fmt.Println("Your score is between 80 and 90.")
case "C":
fmt.Println("Your score is between 70 and 80.")
case "D":
fmt.Println("Your score is between 60 and 70.")
default:
fmt.Println("Your score is below 60.")
}
一个 case 多个条件
在 Go 中, case 后可以接多个条件,多个条件之间是 或 的关系,用逗号 , 相隔。
month := 5
switch month {
case 1, 3, 5, 7, 8, 10, 12:
fmt.Println("该月份有 31 天")
case 4, 6, 9, 11:
fmt.Println("该月份有 30 天")
case 2:
fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
default:
fmt.Println("输入有误!")
}
选择语句另一种写法
switch 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在表达式之前运行。它的语法是:
switch statement; expression {
}
可以将上面的例子改写为:
switch month := 5; month {
case 1, 3, 5, 7, 8, 10, 12:
fmt.Println("该月份有 31 天")
case 4, 6, 9, 11:
fmt.Println("该月份有 30 天")
case 2:
fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
default:
fmt.Println("输入有误!")
}
这里 month 变量的作用域就仅限于这个 switch 内。
switch 后可接函数
switch 后面可以接一个函数,只要保证 case 后的值类型与函数的返回值一致即可。
package main
import "fmt"
func getResult(args ...int) bool {
for _, v := range args {
if v < 60 {
return false
}
}
return true
}
func main() {
chinese := 88
math := 90
english := 95
switch getResult(chinese, math, english) {
case true:
fmt.Println("Pass all exams")
case false:
fmt.Println("Part of the exam failed")
}
}
无表达式的 switch
switch 后面的表达式是可选的。如果省略该表达式,则表示这个 switch 语句等同于 switch true ,并且每个 case 表达式都被认定为有效,相应的代码块也会被执行。
score := 88
switch {
case score >= 90 && score <= 100:
fmt.Println("grade A")
case score >= 80 && score < 90:
fmt.Println("grade B")
case score >= 70 && score < 80:
fmt.Println("grade C")
case score >= 60 && score < 70:
fmt.Println("grade D")
case score < 60:
fmt.Println("grade E")
}
该 switch-case 语句相当于 if-elseif-else 语句。
fallthrough 语句
正常情况下 switch-case 语句在执行时只要有一个 case 满足条件,就会直接退出 switch-case ,如果一个都没有满足,才会执行 default 的代码块。不同于其他语言需要在每个 case 中添加 break 语句才能退出。使用 fallthrough 语句可以在已经执行完成的 case 之后,把控制权转移到下一个 case 的执行代码中。 fallthrough 只能穿透一层,不管你有没有匹配上,都要退出了。 fallthrough 语句是 case 子句的最后一个语句。如果它出现在了 case 语句的中间,编译会不通过。
s := "hello"
switch {
case s == "hello":
fmt.Println("hello")
fallthrough
case s == "my":
fmt.Println("my")
case s != "world":
fmt.Println("world")
}
上面的程序输出如下:
hello
my
Go 语言系列19:循环语句
循环语句 可以用来重复执行某一段代码。在 C 语言中,循环语句有 for 、 while 和 do while 三种循环。但在 Go 中只有 for 一种循环语句。下面是 for 循环语句的四种基本模型:
// for 接三个表达式
for initialisation; condition; post {
code
}
// for 接一个条件表达式
for condition {
code
}
// for 接一个 range 表达式
for range_expression {
code
}
// for 不接表达式
for {
code
}
接下来我们对每一种模型进行讲解。
接一个条件表达式
下面的例子利用 for 循环打印 0 到 3 的数值:
num := 0
for num < 4 {
fmt.Println(num)
num++
}
运行该程序输出如下:
0
1
2
3
接三个表达式
for 后面接的这三个表达式,各有各的用途:
- 第一个表达式(
initialisation):初始化控制变量,在整个循环生命周期内,只执行一次; - 第二个表达式(
condition):设置循环控制条件,该表达式值为true时循环,值为false时结束循环; - 第三个表达式(
post):每次循环完都会执行此表达式,可以利用其让控制变量增量或减量。
这三个表达式,使用 ; 分隔。
for num := 0; num < 4; num++ {
fmt.Println(num)
}
该程序的输出和上面的例子是等价的。这里注意一点,在第一个表达式声明的变量 num 的作用域只在 for 循环里面有效。
接一个 range 表达式
在 Go 中遍历一个可迭代的对象一般使用 for-range 语句实现,其中 range 后面可以接数组、切片、字符串等, range 会返回两个值,第一个是索引值,第二个是数据值。
str := "abcd"
for index, value := range str{
fmt.Printf("index %d, value %c\n", index, value)
}
运行该程序输出如下:
index 0, value a
index 1, value b
index 2, value c
index 3, value d
不接表达式
for 后面不接表达式就相当于无限循环,当然,可以使用 break 语句退出循环。
下面两种无限循环的写法等价,但一般使用第一种写法。
// 第一种写法
for {
code
}
// 第二种写法
for ;; {
code
}
下面是一个输出数字 0 到 3 的例子:
i := 0
for {
if i > 3 {
break
}
fmt.Println(i)
i++
}
运行该程序输出如下:
0
1
2
3
break 语句
break 语句用于终止 for 循环,之后程序将执行在 for 循环后的代码。上面的例子已经演示了 break 语句的使用。
continue 语句
continue 语句用来跳出 for 循环中的当前循环。在 continue 语句后的所有的 for 循环语句都不会在本次循环中执行,执行完 continue 语句后将会继续执行一下次循环。下面的程序会打印出 10 以内的奇数。
for num := 1; num <= 10; num++ {
if num % 2 == 0 {
continue
}
fmt.Println(num)
}
运行该程序输出如下:
1
3
5
7
9
Go 语言系列20:defer 延迟调用
含有 defer 语句的函数,会在该函数将要返回之前,调用另一个函数。简单点说就是 defer 语句后面跟着的函数会延迟到当前函数执行完后再执行。
下面是一个简单的例子:
package main
import "fmt"
func myPrint() {
fmt.Println("Go")
}
func main() {
defer myPrint()
fmt.Println("Let's")
}
首先,执行 main 函数,因为 myPrint() 函数前有 defer 关键字,所以会在执行完 main 函数后再执行 myPrint() 函数,所以先打印出 Let's ,再执行 myPrint() 函数打印 Go 。运行该程序输出如下:
Let's
Go
上面的程序等价于下面的程序:
defer fmt.Println("Go")
fmt.Println("Let's")
即时求值的变量快照
使用 defer 只是延时调用函数,传递给函数里的变量,不应该受到后续程序的影响。
str := "Go"
defer fmt.Println(str)
str = "Let's"
fmt.Println(str)
同理,运行该程序会输出如下:
Let's
Go
延迟方法
defer 不仅能够延迟函数的执行,也能延迟方法的执行。
package main
import "fmt"
type Person struct {
firstName, lastName string
}
func (p Person) printName() {
fmt.Printf("%s %s", p.firstName, p.lastName)
}
func main() {
p := Person{"John", "Smith"}
defer p.printName()
fmt.Printf("Hello ")
}
运行该程序输出如下:
Hello John Smith
defer 栈
当一个函数内多次调用 defer 时,Go 会把 defer 调用放入到一个栈中,随后按照 后进先出(Last In First Out, LIFO) 的顺序执行。
package main
import "fmt"
func main() {
defer fmt.Printf("Caizi.")
defer fmt.Printf("am ")
defer fmt.Printf("I ")
fmt.Printf("Hello! ")
}
运行上面的程序输出如下:
Hello! I am Caizi.
defer 在 return 后调用
看看下面的例子你就知道了:
package main
import "fmt"
var x int = 100
func myfunc() int {
defer func() {x = 200}()
fmt.Println("myfunc: x =", x)
return x
}
func main() {
myx := myfunc()
fmt.Println("main: x =", x)
fmt.Println("main: myx =", myx)
}
运行该程序输出如下:
myfunc: x = 100
main: x = 200
main: myx = 100
defer 可以使代码更简洁
如果没有使用 defer ,当在一个操作资源的函数里调用多个 return 时,每次都得释放资源,你可能这样写代码:
func f() {
r := getResource() //0,获取资源
......
if ... {
r.release() //1,释放资源
return
}
......
if ... {
r.release() //2,释放资源
return
}
......
if ... {
r.release() //3,释放资源
return
}
......
r.release() //4,释放资源
return
}
有了 defer 之后,你可以简洁地写成下面这样:
func f() {
r := getResource() //0,获取资源
defer r.release() //1,释放资源
......
if ... {
...
return
}
......
if ... {
...
return
}
......
if ... {
...
return
}
......
return
}
Go 语言系列21:goto 无条件跳转
在 Go 语言中保留 goto 这点我确实没想到,毕竟很多人不建议使用 goto 语句。 goto 后面接的是标签,表示下一步要执行哪里的代码。
goto label
...
label: code
下面是使用 goto 的例子:
package main
import "fmt"
func main() {
fmt.Println("A")
goto label
fmt.Println("B")
label:
fmt.Println("C")
}
在打印完字符 A 之后,执行了 goto 语句,跳转到 label 标签处,继续执行打印字符 C 的语句,所以运行该程序输出如下:
A
C
goto 语句通常与条件语句配合使用。可用来实现条件转移,构成循环,跳出循环体等功能。例如下面的程序输出数字 0 到 3 :
package main
import "fmt"
func main() {
num := 0
label:
if num < 4 {
fmt.Println(num)
num++
goto label
}
}
我们也可以使用 goto 实现类似 break 的效果:
package main
import "fmt"
func main() {
num := 0
for {
if num > 3 {
goto label
}
fmt.Println(num)
num++
}
label:
fmt.Println("finish")
}
运行该程序输出如下:
0
1
2
3
finish
当然,我们也可以使用 goto 实现类似 continue 的效果:
package main
import "fmt"
func main() {
num := 0
label:
for num < 11 {
if num % 2 == 1 {
num++
goto label
}
fmt.Println(num)
num++
}
}
运行该程序输出如下:
0
2
4
6
8
10
goto 语句与标签之间不能有变量声明,否则编译错误。编译下面的程序会报错:
package main
import "fmt"
func main() {
fmt.Println("A")
goto label
fmt.Println("B")
var x int = 0
label:
fmt.Println("C")
}
Go 语言系列22:方法
方法其实在之前结构体那边简单讲过, 方法 其实就是一个函数,在 func 这个关键字和方法名中间加入了一个特殊的接收器类型。接收器可以是结构体类型或者是非结构体类型。接收器是可以在方法的内部访问的。
func (t Type) methodName(parameter list) {
}
上面的代码片段创建了一个接收器类型为 Type 的方法 methodName 。
摘抄当时给结构体定义方法的例子,你就可能更加明白了。
package main
import "fmt"
// Person 定义一个名为 Person 的结构体
type Person struct {
name string
age int
}
// PrintPersonInfo 定义一个与 Person 的绑定的方法
func (person Person) PrintPersonInfo() {
fmt.Println("name:", person.name)
fmt.Println("age:", person.age)
}
func main() {
per13 := Person{
name: "John",
age: 30,
}
per13.PrintPersonInfo()
}
上面的程序中定义了一个与结构体 Person 绑定的方法 PrintPersonInfo() ,其中 PrintPersonInfo 是方法名, (person Person) 表示将此方法与 Person 的实例绑定,这里我们把 Person 称为方法的接收者,而 person 表示实例本身,相当于 Python 中的 self ,在方法内可以使用 person.attribute_name 来访问实例属性。运行该程序输出如下:
name: John
age: 30
当然,你可以把上面程序的方法改成一个函数,如下:
package main
import "fmt"
type Person struct {
name string
age int
}
func PrintPersonInfo(person Person) {
fmt.Println("name:", person.name)
fmt.Println("age:", person.age)
}
func main() {
per13 := Person{
name: "John",
age: 30,
}
PrintPersonInfo(per13)
}
运行这个程序,也同样会输出上面一样的答案,那么我们为什么还要用方法呢?因为在 Go 中,相同的名字的方法可以定义在不同的类型上,而相同名字的函数是不被允许的。如果你在上面这个程序添加一个同名函数,就会报错。但是在不同的结构体上面定义同名的方法就是可行的。
package main
import "fmt"
type Person struct {
name string
age int
}
func (person Person) PrintInfo() {
fmt.Println("person name:", person.name)
fmt.Println("person age:", person.age)
}
type City struct {
name string
}
func (city City) PrintInfo() {
fmt.Println("city name:", city.name)
}
func main() {
person := Person{name: "John", age: 30}
person.PrintInfo()
city := City{"Beijing"}
city.PrintInfo()
}
运行该程序输出如下:
person name: John
person age: 30
city name: Beijing
指针接收器与值接收器
值接收器和指针接收器之间的区别在于,在指针接收器的方法内部的改变对于调用者是可见的,然而值接收器的方法内部的改变对于调用者是不可见的,所以若要改变实例的属性时,必须使用指针作为方法的接收者。看看下面的例子就知道了:
package main
import "fmt"
// Person 定义一个名为 Person 的结构体
type Person struct {
name string
age int
}
// PrintPersonInfo 定义一个与 Person 的绑定的方法
func (person Person) PrintPersonInfo() {
fmt.Println("name:", person.name)
fmt.Println("age:", person.age)
}
func (person Person) ChangePersonName(name string) {
person.name = name
}
// AddPersonAge 定义一个与 Person 的绑定的方法,使 age 值加 n
func (person *Person) AddPersonAge(n int) {
person.age = person.age + n
}
func main() {
person := Person{
name: "John",
age: 30,
}
fmt.Println("before change")
person.PrintPersonInfo()
fmt.Println("after change")
person.AddPersonAge(5)
person.ChangePersonName("Mary")
person.PrintPersonInfo()
}
在上面的程序中, AddPersonAge 使用指针接收器最终能改变实例的 age 值,然而使用值接收器的 ChangePersonName 最终没有改变实例 name 的值。运行该程序输出如下:
before change
name: John
age: 30
after change
name: John
age: 35
在方法中使用值接收器 与 在函数中使用值参数
当一个函数有一个值参数,它只能接受一个值参数。当一个方法有一个值接收器,它可以接受值接收器和指针接收器。
package main
import "fmt"
type Person struct {
name string
}
func (person Person) PrintInfo() {
fmt.Println(person.name)
}
func PrintInfo(person Person) {
fmt.Println(person.name)
}
func main() {
person := Person{"John"}
PrintInfo(person)
person.PrintInfo()
p := &person
//PrintInfo(p) // error
p.PrintInfo()
}
在上面的程序中,使用值参数 PrintInfo(person) 来调用这个函数是合法的,使用值接收器来调用 person.PrintInfo() 也是合法的。
然后在程序中我们创建了一个指向 person 的指针 p ,通过使用指针接收器来调用 p.PrintInfo() 是合法的,但使用值参数调用 PrintInfo(p) 是非法的。
在非结构体上的方法
不仅可以在结构体类型上定义方法,也可以在非结构体类型上定义方法,但是有一个问题。为了在一个类型上定义一个方法,方法的接收器类型定义和方法的定义应该在同一个包中。例如:
package main
import "fmt"
type myInt int
func (a myInt) add(b myInt) myInt {
return a + b
}
func main() {
var x myInt = 10
var y myInt = 20
fmt.Println(x.add(y)) // 30
}
Go 语言系列23:接口
在 Go 语言中, 接口 就是方法签名(Method Signature)的集合。在面向对象的领域里,接口定义一个对象的行为,接口只指定了对象应该做什么,至于如何实现这个行为,则由对象本身去确定。当一个类型定义了接口中的所有方法,我们称它实现了该接口。接口指定了一个类型应该具有的方法,并由该类型决定如何实现这些方法。
接口的定义
使用 type 关键字可以定义接口:
type interface_name interface {
method()
}
接口的实现
创建类型或者结构体,并为其绑定接口定义的方法,接收者为该类型或结构体,方法名为接口中定义的方法名,这样就说该类型或者结构体实现了该接口。例如:
package main
import "fmt"
type Usb interface {
link()
}
type Computer struct {
name string
}
func (computer Computer) link() {
fmt.Println("电脑 USB 接口连接到 U 盘")
}
func main() {
myComputer := Computer{"菜籽的电脑"}
myComputer.link()
}
上面的程序定义了一个名为 Usb 的接口,接口中有未实现的方法 link() ,这里还定义了名为 Computer 的结构体,其绑定了方法 link() ,也就隐式实现了 Usb 接口,实现的内容是打印 电脑 USB 接口连接到 U 盘 语句,运行该程序输出如下:
电脑 USB 接口连接到 U 盘
上面的例子使用了值接受者实现接口,下面的例子使用了指针接受者实现接口。
package main
import "fmt"
type Describer interface {
Describe()
}
type Person struct {
name string
age int
}
func (person Person) Describe() {
fmt.Printf("%s is %d years old\n", person.name, person.age)
}
type Date struct {
year int
month int
day int
}
func (date *Date) Describe() {
fmt.Printf("Today is %d-%d-%d\n", date.year, date.month, date.day)
}
func main() {
var d1 Describer
var d2 Describer
person1 := Person{"John", 30}
d1 = person1
d1.Describe()
person2 := Person{"Mary", 25}
d1 = &person2
d1.Describe()
date := Date{2022, 1, 1}
// d2 = date // error
d2 = &date
d2.Describe()
}
该程序定义了结构体 Person ,使用其作为值接受者实现 Describer 接口。 person1 的类型为 Person , person1 赋值给 d1 ,由于 Person 实现了接口变量 d1 所以会有输出。而接下来 d1 又被赋值为 &person2 ,同样有输出。接下来的结构体 Date 使用指针接受者实现 Describer 接口。 date 的类型为 Date , d2 被赋值为 &date ,所以会有输出。但如果把 d2 赋值为 date 会报错,对于使用指针接受者的方法,用一个指针或者一个可取得地址的值来调用都是合法的。但接口中存储的具体值(Concrete Value)并不能取到地址,因此对于编译器无法自动获取 date 的地址,于是程序报错。运行该程序输出如下:
John is 30 years old
Mary is 25 years old
Today is 2022-1-1
接口实现多态
使用接口可以实现多态,例如下面的程序,定义了名为 Animal 的接口,接口中有方法 bark() ,也就是说动物会发出不同的叫声。程序中还定义了结构体 Cat 和 Dog ,分别实现了 Animal 接口,猫的叫声为 喵喵喵... 而狗的叫声为 汪汪汪... ,利用的接口实现了不同的功能,这就是多态。
package main
import "fmt"
type Animal interface {
bark()
}
type Cat struct {
name string
}
type Dog struct {
name string
}
func (cat Cat) bark() {
fmt.Println("喵喵喵...")
}
func (dog Dog) bark() {
fmt.Println("汪汪汪...")
}
func main() {
myCat := Cat{"哆啦A梦"}
myDog := Dog{"史努比"}
myCat.bark() // 喵喵喵...
myDog.bark() // 汪汪汪...
}
接口的内部表示
可以把接口看作内部的一个元组 (type, value)。 type 是接口底层的具体类型(Concrete Type),而 value 是具体类型的值。
package main
import "fmt"
type Animal interface {
bark()
}
type Cat struct {
name string
}
func (cat Cat) bark() {
fmt.Println("喵喵喵...")
}
func describe(animal Animal) {
fmt.Printf("Interface type: %T\nInterface value: %v\n", animal, animal)
}
func main() {
var animal Animal
myCat := Cat{"哆啦A梦"}
animal = myCat
describe(animal)
animal.bark()
}
在上面的程序中,定义了 Animal 接口,其中有 bark() 方法,结构体 Cat 实现了该接口。使用 animal = myCat 语句我们把 myCat ( Cat 类型)赋值给了 animal ( Animal 类型),现在打印出 animal 的具体类型为 Cat ,而 Cat 的值为 {哆啦A梦} 。运行该程序输出如下:
Interface type: main.Cat
Interface value: {哆啦A梦}
喵喵喵...
空接口
空接口 是特殊形式的接口类型,没有定义任何方法的接口就称为空接口,可以说所有类型都至少实现了空接口,空接口表示为 interface{} 。例如,我们之前的写过的空接口参数函数,可以接受任何类型的参数:
package main
import "fmt"
func describe(int interface {}) {
fmt.Printf("Type: %T, value: %v\n", int, int)
}
func main() {
str := "Let's go"
describe(str)
num := 3.14
describe(num)
}
上面的程序中我们定义了函数 describe 使用空接口作为参数,所以可以给这个函数传递任何类型的参数,运行该程序输出如下:
Type: string, value: Let's go
Type: float64, value: 3.14
通过上面的例子不难发现接口都有两个属性,一个是值,而另一个是类型。对于空接口来说,这两个属性都为 nil :
package main
import "fmt"
func main() {
var in interface{}
fmt.Printf("Type: %T, Value: %v", in, in)
// Type: <nil>, Value: <nil>
}
除了上面讲到的使用空接口作为函数参数的用法,空接口还有以下两种用法。
直接使用 interface{} 作为类型声明一个实例,这个实例就能承载任何类型的值:
package main
import "fmt"
func main() {
var in interface{}
in = "Let's go"
fmt.Println(in) // Let's go
in = 3.14
fmt.Println(in) // 3.14
}
我们也可以定义一个接收任何类型的 array 、 slice 、 map 、 strcut 。例如:
package main
import "fmt"
func main() {
x := make([]interface{}, 3)
x[0] = "Let's go"
x[1] = 3.14
x[2] = []int{1, 2, 3}
for _, value := range x {
fmt.Println(value)
}
}
运行该程序输出如下:
Let's go
3.14
[1 2 3]
空接口可以承载任何值,但是空接口类型的对象是不能赋值给另一个固定类型对象的。
package main
func main() {
var num = 1
var in interface{} = num
var str string = in // error
}
当空接口承载数组和切片后,该对象无法再进行切片。
package main
import "fmt"
func main() {
var slice = []int{1, 2, 3}
var in interface{} = slice
var newSlice = in[1:2] // error
fmt.Println(newSlice)
}
类型断言
类型断言用于提取接口的底层值(Underlying Value)。使用 interface.(Type) 可以获取接口的底层值,其中接口 interface 的具体类型是 Type 。
package main
import "fmt"
func assert(in interface{}) {
value, ok := in.(int)
fmt.Println(value, ok)
}
func main() {
var x interface{} = 3
assert(x)
var y interface{} = "Let's go"
assert(y)
}
运行上面的程序输出如下:
3 true
0 false
类型选择
类型选择用于将接口的具体类型与 case 语句所指定的类型进行比较。它其实就是一个 switch 语句,但在 switch 后面跟的是 in.(type) ,并且每个 case 后面跟的是类型。
package main
import "fmt"
func getTypeValue(in interface{}) {
switch in.(type) {
case int:
fmt.Printf("Type: int, Value: %d\n", in.(int))
case string:
fmt.Printf("Type: string, Value: %s\n", in.(string))
default:
fmt.Printf("Unknown type\n")
}
}
func main() {
getTypeValue(3)
getTypeValue("abc")
getTypeValue(true)
}
运行上面的程序输出如下:
Type: int, Value: 3
Type: string, Value: abc
Unknown type
实现多个接口
类型或者结构体可以实现多个接口,例如:
package main
import "fmt"
type Describer interface {
Describe()
}
type Animal interface {
bark()
}
type Cat struct {
name string
}
func (cat Cat) Describe() {
fmt.Printf("Cat name: %s\n", cat.name)
}
func (cat Cat) bark() {
fmt.Printf("喵喵喵...\n")
}
func main() {
myCat := Cat{"哆啦A梦"}
myCat.Describe()
myCat.bark()
}
上面的程序定义了两个接口,结构体 Cat 分别实现了这两个接口,运行该程序输出如下:
Cat name: 哆啦A梦
喵喵喵...
接口的嵌套
虽然在 Go 中没有继承机制,但可以通过接口的嵌套实现类似功能。例如:
package main
import "fmt"
type Animal interface {
Describer
Bark
}
type Describer interface {
Describe()
}
type Bark interface {
bark()
}
type Cat struct {
name string
}
func (cat Cat) Describe() {
fmt.Printf("Cat name: %s\n", cat.name)
}
func (cat Cat) bark() {
fmt.Printf("喵喵喵...\n")
}
func main() {
myCat := Cat{"哆啦A梦"}
myCat.Describe()
myCat.bark()
}
Cat 结构体实现了 Animal 接口。运行该程序输出如下:
Cat name: 哆啦A梦
喵喵喵...
Go 语言系列24:go 协程
Go 协程 是与其他函数或方法一起并发运行的函数或方法。Go 协程可以看作是轻量级线程。与线程相比,创建一个 Go 协程的成本很小。因此在 Go 应用中,常常会看到有数以千计的 Go 协程并发地运行。
启动一个 go 协程
调用函数或者方法时,如果在前面加上关键字 go ,就可以让一个新的 Go 协程并发地运行。
// 定义一个函数
func function_name() {
code
}
// 执行一个函数
function_name()
// 开启一个协程执行这个函数
go function_name()
下面是启动一个协程的例子, go PrintfA() 语句启动了一个新的协程, PrintfA() 函数与 main() 函数会并发执行,主函数运行在一个特殊的协程上,这个协程称之为 主协程(Main Goroutine) 。
启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也不会继续运行。为了让新的协程能继续运行,我们在 main() 函数添加了 time.Sleep(1 * time.Second) 使主协程休眠 1 秒,但这种做法并不推荐,这里只是为了演示而添加。
package main
import (
"fmt"
"time"
)
func PrintfA() {
fmt.Println("A")
}
func main() {
// 开启一个协程执行 PrintfA 函数
go PrintfA()
// 使主协程休眠 1 秒
time.Sleep(1 * time.Second)
// 打印 main
fmt.Println("main")
}
运行上面的程序输出如下:
A
main
启动多个 go 协程
通过下面的例子,可以观察到两个协程就如两个线程一样,并发执行:
package main
import (
"fmt"
"time"
)
func Print(num int) {
for i := 0; i < 5; i++ {
fmt.Println(num)
// 避免观察不到并发效果 加个休眠
time.Sleep(time.Millisecond)
}
}
func main() {
// 开启 1 号协程
go Print(1)
// 开启 2 号协程
go Print(2)
// 使主协程休眠 1 秒
time.Sleep(time.Second)
}
运行该程序的一种输出如下:
2
1
1
2
2
1
1
2
2
1
Go 语言系列25:channel 信道
信道(channel)(又称为通道) ,就是一个管道,可以想像成 Go 协程之间通信的管道。它是一种队列式的数据结构,遵循先入先出的规则。
信道的声明
每个信道都只能传递一种数据类型的数据,在你声明的时候,我们要指定信道的类型。 chan Type 表示 Type 类型的信道。信道的零值为 nil 。
var channel_name chan channel_type
下面的语句声明了一个类型为 int 的信道 a ,该信道 a 的值为 nil 。
var a chan int
信道的初始化
声明完信道后,信道的值为 nil ,我们不能直接使用,必须先使用 make 函数对信道进行初始化操作。
channel_name = make(chan channel_type)
使用下面的语句我们可以对上面声明过的信道 a 进行初始化:
a = make(chan int)
这样,我们就已经定义好了一个 int 类型的信道 a 。
当然,也可以使用下面的简短声明语句一次性定义一个信道:
a := make(chan int)
使用信道发送和接收数据
往信道发送数据使用的是下面的语法:
// 把 data 数据发送到 channel_name 信道中
// 即把 data 数据写入到 channel_name 信道中
channel_name <- data
从信道接收数据使用的是下面的语法:
// 从 channel_name 信道中接收数据到 value
// 即从 channel_name 信道中读取数据到 value
value := <- channel_name
信道旁的箭头方向指定了是发送数据还是接收数据。箭头指向信道,代表数据写入到信道中;箭头往信道指向外,代表从信道读数据出去。
下面的例子演示了信道的使用:
package main
import (
"fmt"
)
func John(c chan string) {
// 往信道传入数据 "John: Hi"
c <- "John: Hi"
}
func main() {
// 创建一个信道
c := make(chan string)
// 打印 "Mary: Hello"
fmt.Println("Mary: Hello")
// 开启协程
go John(c)
// 从信道接收数据
rec := <- c
// 打印从信道接收到的数据
fmt.Println(rec)
// 打印 "Mary: Nice to meet you"
fmt.Println("Mary: Nice to meet you")
}
该程序模仿了两个人见面的场景,在 main 函数中,创建了一个信道,在 main 函数中先打印了 Mary: Hello ,然后开启协程运行 John 函数,而 main 函数通过协程接收数据,主协程发生了阻塞,等待信道 c 发送的数据,在函数中,数据 John: Hi 传入信道中,当写入完成时,主协程接收了数据,解除了阻塞状态,打印出从信道接收到的数据 John: Hi ,最后打印 Mary: Nice to meet you 。运行该程序输出如下:
Mary: Hello
John: Hi
Mary: Nice to meet you
发送与接收默认是阻塞的
从上面的例子我们知道,如果从信道接收数据没接收完主协程是不会继续执行下去的。当把数据发送到信道时,程序控制会在发送数据的语句处发生阻塞,直到有其它 Go 协程从信道读取到数据,才会解除阻塞。与此类似,当读取信道的数据时,如果没有其它的协程把数据写入到这个信道,那么读取过程就会一直阻塞着。
信道的关闭
对于一个已经使用完毕的信道,我们要将其进行关闭。
close(channel_name)
这里要注意,对于一个已经关闭的信道如果再次关闭会导致报错,我们可以在接收数据时,判断信道是否已经关闭,从信道读取数据返回的第二个值表示信道是否没被关闭,如果已经关闭,返回值为 false ;如果还未关闭,返回值为 true 。
value, ok := <- channel_name
信道的容量与长度
我们在前面讲过 make 函数是可以接收两个参数的,同理,创建信道可以传入第二个参数——容量。
- 当容量为
0时,说明信道中不能存放数据,在发送数据时,必须要求立马有人接收,否则会报错。此时的信道称之为无缓冲信道。 - 当容量为
1时,说明信道只能缓存一个数据,若信道中已有一个数据,此时再往里发送数据,会造成程序阻塞。利用这点可以利用信道来做锁。 - 当容量大于
1时,信道中可以存放多个数据,可以用于多个协程之间的通信管道,共享资源。
既然信道有容量和长度,那么我们可以通过 cap 函数和 len 函数获取信道的容量和长度。
package main
import (
"fmt"
)
func main() {
// 创建一个信道
c := make(chan int, 3)
fmt.Println("初始化后:")
fmt.Println("cap =", cap(c))
fmt.Println("len =", len(c))
c <- 1
c <- 2
fmt.Println("传入两个数后:")
fmt.Println("cap =", cap(c))
fmt.Println("len =", len(c))
<- c
fmt.Println("取出一个数后:")
fmt.Println("cap =", cap(c))
fmt.Println("len =", len(c))
}
程序中 <- c 通过信道接收数据但没有存入变量中也是合法的,运行该程序后输出如下:
初始化后:
cap = 3
len = 0
传入两个数后:
cap = 3
len = 2
取出一个数后:
cap = 3
len = 1
缓冲信道与无缓冲信道
按照是否可缓冲数据可分为: 缓冲信道 与 无缓冲信道 。
无缓冲信道在信道里无法存储数据,接收端必须先于发送端准备好,以确保你发送完数据后,有人立马接收数据,否则发送端就会造成阻塞,原因很简单,信道中无法存储数据。也就是说发送端和接收端是同步运行的。
c := make(chan int)
// 或者
c := make(chan int, 0)
缓冲信道允许信道里存储一个或多个数据,设置缓冲区后,发送端和接收端可以处于异步的状态。
c := make(chan int, 3)
双向信道
到目前为止,上面定义的都是双向信道,既可以发送数据也可以接收数据。例如:
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个信道
c := make(chan int)
// 发送数据
go func() {
fmt.Println("send: 1")
c <- 1
}()
// 接收数据
go func() {
n := <- c
fmt.Println("receive:", n)
}()
// 主协程休眠
time.Sleep(time.Millisecond)
}
运行上面的程序输出如下:
send: 1
receive: 1
单向信道
单向信道只能发送或者接收数据。所以可以具体细分为只读信道和只写信道。
<-chan 表示这个信道,只能发送出数据,即只读:
// 定义只读信道
c := make(chan int)
// 定义类型
type Receiver = <-chan int
var receiver Receiver = c
// 或者简单写成下面的形式
type Receiver = <-chan int
receiver := make(Receiver)
chan<- 表示这个信道,只能接收数据,即只写:
// 定义只写信道
c := make(chan int)
// 定义类型
type Sender = chan<- int
var sender Sender = c
// 或者简单写成下面的形式
type Sender = chan<- int
sender := make(Sender)
下面是一个例子:
package main
import (
"fmt"
"time"
)
// Sender 只写信道类型
type Sender = chan<- string
// Receiver 只读信道类型
type Receiver = <-chan string
func main() {
// 创建一个双向信道
var pipe = make(chan string)
// 开启一个协程
go func() {
// 只能写信道
var sender Sender = pipe
fmt.Println("send: 2333")
sender <- "2333"
}()
// 开启一个协程
go func() {
// 只能读信道
var receiver Receiver = pipe
message := <-receiver
fmt.Println("receive: ", message)
}()
time.Sleep(time.Millisecond)
}
运行上面的程序输出如下:
send: 2333
receive: 2333
遍历信道
使用 for range 循环可以遍历信道,但在遍历时要确保信道是处于关闭状态,否则循环会被阻塞。
package main
import (
"fmt"
)
func f(c chan int) {
for i := 0; i < 10; i++ {
c <- i
}
// 记得要关闭信道
// 否则主协程遍历完不会结束,而会阻塞
close(c)
}
func main() {
// 创建一个信道
var pipe = make(chan int, 5)
go f(pipe)
for v := range pipe {
fmt.Println(v)
}
}
运行上面的程序输出数字 0 至 9 。
用信道做锁
上面讲过,当信道容量为 1 时,说明信道只能缓存一个数据,若信道中已有一个数据,此时再往里发送数据,会造成程序阻塞。例如:
package main
import (
"fmt"
"time"
)
// 由于 x = x+1 不是原子操作
// 所以应避免多个协程对 x 进行操作
// 使用容量为 1 的信道可以达到锁的效果
func increment(ch chan bool, x *int) {
ch <- true
*x = *x + 1
<- ch
}
func main() {
pipe := make(chan bool, 1)
var x int
for i := 0; i < 10000; i++ {
go increment(pipe, &x)
}
time.Sleep(time.Millisecond)
fmt.Println("x =", x)
}
运行该程序输出如下:
x = 10000
但如果把容量改大,例如 1000 ,可能输出的数值会小于 10000 。
死锁
讲完了锁,不得不提死锁。当 Go 协程给一个信道发送数据时,照理说会有其他 Go 协程来接收数据。如果没有的话,程序就会在运行时触发 panic ,形成死锁。同理,当有 Go 协程等着从一个信道接收数据时,我们期望其他的 Go 协程会向该信道写入数据,要不然程序也会触发 panic 。
package main
func main() {
ch := make(chan bool)
ch <- true
}
运行上面的程序,会触发 panic ,报下面的错误:
fatal error: all goroutines are asleep - deadlock!
下面再来看看几个例子。
package main
import "fmt"
func main() {
ch := make(chan bool)
ch <- true
fmt.Println(<-ch)
}
上面的代码你看起来可能觉得没啥问题,创建一个信道,往里面写入数据,再从里面读出数据,但运行后会报同样的错误:
fatal error: all goroutines are asleep - deadlock!
那么为什么会出现死锁呢?前面的基础学的好的就不难想到使用 make 函数创建信道时默认不传递第二个参数,信道中不能存放数据,在发送数据时,必须要求立马有人接收,即该信道为无缓冲信道。所以在接收者没有准备好前,发送操作会被阻塞。
分析完引发异常的原因后,我们可以将代码修改如下,使用协程,将接收者代码放在另一个协程里:
package main
import (
"fmt"
"time"
)
func f(c chan bool) {
fmt.Println(<-c)
}
func main() {
ch := make(chan bool)
go f(ch)
ch <- true
time.Sleep(time.Millisecond)
}
当然,还有一种更加直接的方法,把无缓冲信道改为缓冲信道就行了:
package main
import "fmt"
func main() {
ch := make(chan bool, 1)
ch <- true
fmt.Println(<-ch)
}
有时候我们定义了信道的容量,但信道里的容量已经放不下新的数据,而没有接收者接收数据,就会造成阻塞,而对于一个协程来说就会造成死锁:
package main
import "fmt"
func main() {
ch := make(chan bool, 1)
ch <- true
ch <- false
fmt.Println(<-ch)
}
同理,当程序一直在等待从信道里读取数据,而此时并没有发送者会往信道中写入数据。此时程序就会陷入死循环,造成死锁。
Go 语言系列26:WaitGroup
之前写的协程有关的例子,为了保证所有协程都执行完毕后退出,我们都使用了 time.Sleep(time.Millisecond) 使主协程休眠,但在实际开发中我们并不能保证要休眠多久才能执行完毕,用多了主程序就阻塞了,用少了又会导致子协程的任务可能没法完成。下面我们介绍处理这种情况的方式。
使用信道
信道可以实现多个协程间的通信,于是乎我们可以定义一个信道,在任务执行完成后,往信道中写入 true ,然后在主协程中获取到 true ,就可以认为子协程已经执行完毕。
package main
import "fmt"
func main() {
isDone := make(chan bool)
go func() {
for i := 0; i < 5; i++{
fmt.Println(i)
}
isDone <- true
}()
<- isDone
}
运行上面的程序,主协程就会等待创建的协程执行完毕后退出,运行后输出如下:
0
1
2
3
4
使用 WaitGroup
使用上面的信道方法,虽然可行,但在你程序中使用很多协程的话,你的代码就会看起来很复杂,这里就要介绍一种更好的方法,那就是使用 sync 包中提供的 WaitGroup 类型。 WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。当然 WaitGroup 也可以用于实现工作池。
WaitGroup 实例化后就能使用:
var name sync.WaitGroup
WaitGroup 有几个方法:
Add:初始值为 0 ,这里直接传入子协程的数量,你传入的值会往计数器上加。
Done:当某个子协程完成后,可调用此方法,会从计数器上减一,即子协程的数量减一,通常使用 defer 来调用。
Wait:阻塞当前协程,直到实例里的计数器归零。
package main
import (
"fmt"
"sync"
)
func task(taskNum int, waitGroup *sync.WaitGroup) {
// 延迟调用 执行完子协程计数器减一
defer waitGroup.Done()
// 输出任务号
for i := 0; i < 3; i++ {
fmt.Printf("task %d: %d\n", taskNum, i)
}
}
func main() {
// 实例化 sync.WaitGroup
var waitGroup sync.WaitGroup
// 传入子协程的数量
waitGroup.Add(3)
// 开启一个子协程 协程 1 以及 实例 waitGroup
go task(1, &waitGroup)
// 开启一个子协程 协程 2 以及 实例 waitGroup
go task(2, &waitGroup)
// 开启一个子协程 协程 3 以及 实例 waitGroup
go task(3, &waitGroup)
// 实例 waitGroup 阻塞当前协程 等待所有子协程执行完
waitGroup.Wait()
}
运行上面的程序一种输出如下:
task 3: 0
task 3: 1
task 3: 2
task 1: 0
task 1: 1
task 1: 2
task 2: 0
task 2: 1
task 2: 2
Go 语言系列27:Select
select 语句用于在多个发送/接收信道操作中进行选择。 select 语句会一直阻塞,直到发送/接收操作准备就绪。如果有多个信道操作准备完毕, select 会随机地选取其中之一执行。 select-case 跟 switch-case 相比,用法比较单一,它仅能用于 信道/通道 的相关操作。 select-case 模型如下:
select {
case expression1:
code
case expression2:
code
default:
code
}
下面是使用 select-case 的一个简单例子:
package main
import "fmt"
func main() {
// 创建两个信道
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
// 往信道 1 发送数据 100
ch1 <- 100
// 往信道 2 发送数据 200
ch2 <- 200
select {
// 如果从信道 1 收到数据
case message1 := <-ch1:
fmt.Println("ch1 received:", message1)
// 如果从信道 2 收到数据
case message2 := <-ch2:
fmt.Println("ch2 received:", message2)
// 默认输出
default:
fmt.Println("No data received.")
}
}
上面的程序创建了两个信道,并在执行 select 语句之前往信道 1 和信道 2 分别发送数据,在执行 select 语句时,如果有机会的话会运行所有表达式,只要其中一个信道接收到数据,那么就会执行对应的 case 代码,然后退出。所以运行该程序可能输出下面的语句:
ch1 received: 100
也有可能输出下面的这条语句,具体看哪个信道首先接收到数据:
ch2 received: 200
select 的应用
利用 select 的特性,可以将其使用在获取服务器响应上。
假设某个应用的数据库复制并且存储在世界各地的服务器上。假设函数 server1 和 server2 与这样不同区域的两台服务器进行通信。每台服务器的负载和网络时延决定了它的响应时间。我们向两台服务器发送请求,并使用 select 语句等待相应的信道发出响应。 select 会选择首先响应的服务器,而忽略其它的响应。使用这种方法,我们可以向多个服务器发送请求,并给用户返回最快的响应。
下面的程序模拟了这种服务:
package main
import (
"fmt"
"time"
)
func server1(ch chan string) {
time.Sleep(3 * time.Second)
ch <- "server 1"
}
func server2(ch chan string) {
time.Sleep(6 * time.Second)
ch <- "server 2"
}
func main() {
// 创建两个信道
ch1 := make(chan string)
ch2 := make(chan string)
go server1(ch1)
go server2(ch2)
select {
// 如果从信道 1 收到数据
case message1 := <-ch1:
fmt.Println("ch1 received:", message1)
// 如果从信道 2 收到数据
case message2 := <-ch2:
fmt.Println("ch2 received:", message2)
}
}
运行该程序输出如下:
ch1 received: server 1
当然,比较上面两个程序会发现,下面这个例子中没有 default 分支,因为如果加了该默认分支,如果还没从信道接收到数据, select 语句就会直接执行 default 分支然后退出,而不是被阻塞。
造成死锁
上面的例子引出了一个新的问题,那就是如果没有 default 分支, select 就会阻塞,如果一直没有命中其中的某个 case 最后会造成死锁。
package main
import (
"fmt"
)
func main() {
// 创建两个信道
ch1 := make(chan string, 1)
ch2 := make(chan string, 1)
select {
// 如果从信道 1 收到数据
case message1 := <-ch1:
fmt.Println("ch1 received:", message1)
// 如果从信道 2 收到数据
case message2 := <-ch2:
fmt.Println("ch2 received:", message2)
}
}
运行上面的程序会造成死锁。解决该问题的方法是写好 default 分支。
当然还有另一种情况会导致死锁的发生,那就是使用空 select :
package main
func main() {
select {}
}
运行上面的程序会抛出 panic 。
随机性
前面学习 switch-case 的时候,里面的 case 是顺序执行的,但在 select 里并不是顺序执行的。在上面的第一个例子就可以看出,当 select 由多个 case 准备就绪时,将会随机地选取其中之一去执行。
select 的超时
当 case 里的信道始终没有接收到数据时,而且也没有 default 语句时, select 整体就会阻塞,但是有时我们并不希望 select 一直阻塞下去,这时候就可以手动设置一个超时时间。
package main
import (
"fmt"
"time"
)
func makeTimeout(ch chan bool, t int) {
time.Sleep(time.Second * time.Duration(t))
ch <- true
}
func main() {
c1 := make(chan string, 1)
c2 := make(chan string, 1)
timeout := make(chan bool, 1)
go makeTimeout(timeout, 2)
select {
case msg1 := <-c1:
fmt.Println("c1 received: ", msg1)
case msg2 := <-c2:
fmt.Println("c2 received: ", msg2)
case <-timeout:
fmt.Println("Timeout, exit.")
}
}
运行上面的程序输出如下:
Timeout, exit.
读取/写入数据
select 里的 case 表达式只能对信道进行操作,不管你是往信道写入数据,还是从信道读出数据。
package main
import (
"fmt"
)
func main() {
c1 := make(chan int, 2)
c1 <- 2
select {
case c1 <- 4:
fmt.Println("c1 received: ", <-c1)
fmt.Println("c1 received: ", <-c1)
default:
fmt.Println("channel blocking")
}
}
运行上面的程序输出如下:
c1 received: 2
c1 received: 4
Go 语言系列28:互斥锁与读写锁
在 Go 语言中,经常会遇到并发的问题,当然我们会优先考虑使用信道,但在这里我们会讨论如何通过 Mutex(互斥锁) 和 RWMutex(读写锁) 来处理竞争条件。
临界区
首先我们要理解并发编程中临界区的概念。当程序并发地运行时,多个 Go 协程不应该同时访问那些修改共享资源的代码。这些修改共享资源的代码称为 临界区 。
我们这里举一个简单的例子,假如要实现一个功能,使当前变量的值加 100 ,我们会写出下面的代码:
x = x +100
当然,对于只有一个协程的程序来说,上面的代码没有任何问题。但是,如果有多个协程并发运行时,就会发生错误,为了简单起见,这里只用两个协程。
第一个协程获取当前 x 的值,并计算 x + 100 ,最后将计算后的值赋给 x 。同理,第二个协程也是按照第一个协程的步骤做。
一种可能发生的情况是第一个协程获取到 x 的值,然后对其加上 100 再赋给 x ,此时 x 的值更新为 x + 100 。第一个协程执行完毕后执行第二个协程,获取到 x 的值为 x + 100 ,然后再对其加上 100 再赋给 x ,此时 x 的值更新为 x + 200 。最后 x 的结果为 x + 200 。
但是,这里也有可能会发生另一种情况,那就是第一个协程获取完 x 的值后,还没执行完该协程,就切换到第二个协程执行,第二个协程同样获取到 x 的值,然后对 x 的值加 100 ,并赋值给 x ,x 更新为 x + 100 。在第二个协程执行完后,又切换到第一个协程执行,此时第一个协程 x 的值还为 x ,对其进行加 100 的操作后, x 的值更新为 x + 100 ,再赋值给 x 变量,最后导致执行完两个协程结果变量 x 的值为 x + 100 。
所以,由于上下文切换的不同, x 的值可能更新为 x + 100 或者 x + 200 ,这种情况就称之为竞争条件。使用下面的互斥锁 Mutex 就能避免这种情况的发生。
互斥锁 Mutex
互斥锁(Mutex,mutual exclusion) 用于提供一种 加锁机制(Locking Mechanism) ,可确保在某时刻只有一个协程在临界区运行,以防止出现竞争条件。使用其是为了来保护一个资源不会因为并发操作而引起冲突导致数据不准确。
Mutex 的定义有以下两种方法:
var lock *sync.Mutex
lock = new(sync.Mutex)
或者
lock := &sync.Mutex{}
Mutex 有两个方法,分别是 Lock 和 Unlock ,即对应的加锁和解锁。在 Lock 和 Unlock 之间的代码,都只能由一个协程执行,就能避免竞争条件。
lock.Lock()
x = x + 100
lock.Unlock()
如果有一个协程已经持有了 锁(Lock) ,当其他协程试图获得该锁时,这些协程会被阻塞,直到 Mutex 解除锁定为止。
下面使用一个例子来讲一讲互斥锁的使用,首先看到下面的代码,使用两个协程,分别计算 x 加上 1000 次 1 ,分析代码不难看出,执行完两个协程后 x 的结果应该为 2000 :
package main
import (
"fmt"
"sync"
)
func add(x *int, waitgroup *sync.WaitGroup) {
defer waitgroup.Done()
for i := 0; i < 1000; i++ {
*x = *x + 1
}
}
func main() {
var waitGroup sync.WaitGroup
x := 0
waitGroup.Add(2)
go add(&x, &waitGroup)
go add(&x, &waitGroup)
waitGroup.Wait()
fmt.Println("x =", x)
}
但运行完该程序后,输出的结果值每次都不同,而且都不等于 2000 。通过上面的讲解,相信你应该知道为什么会出现这种情况了,为了解决这个问题,我们就要对 add 这个函数加上互斥锁,使同一时刻,只能有一个协程对 x 进行操作:
package main
import (
"fmt"
"sync"
)
func add(x *int, waitgroup *sync.WaitGroup, lock *sync.Mutex) {
defer waitgroup.Done()
for i := 0; i < 1000; i++ {
lock.Lock()
*x = *x + 1
lock.Unlock()
}
}
func main() {
var waitGroup sync.WaitGroup
lock := &sync.Mutex{}
x := 0
waitGroup.Add(2)
go add(&x, &waitGroup, lock)
go add(&x, &waitGroup, lock)
waitGroup.Wait()
fmt.Println("x =", x)
}
更改后的代码不管运行多少次,都只会输出一个结果,那就是 2000 。
当然,使用互斥锁很简单,但要注意同一协程里不要在尚未解锁时再次加锁,也不要对已经解锁的锁再次解锁。
当然,使用信道也可以处理竞争条件,把信道作为锁在前面讲信道的时候已经讲过,这里就不再赘述。
读写锁 RWMutex
sync.RWMutex 类型实现读写互斥锁,为了保证数据的安全,它规定了当有人还在读取数据(即读锁占用)时,不允许有人更新这个数据(即写锁会阻塞);为了保证程序的效率,多个人(线程)读取数据(拥有读锁)时,互不影响不会造成阻塞,它不会像 Mutex 那样只允许有一个人(线程)读取同一个数据。
RWMutex 是基于 Mutex 的,在 Mutex 的基础之上增加了读、写的信号量,并使用了类似引用计数的读锁数量。读锁与读锁兼容,读锁与写锁互斥,写锁与写锁互斥,只有在锁释放后才可以继续申请互斥的锁:
- 可以同时申请多个读锁;
- 有读锁时申请写锁将阻塞,有写锁时申请读锁将阻塞;
- 只要有写锁,后续申请读锁和写锁都将阻塞。
定义一个 RWMuteux 读写锁,同样有两种方法:
var lock *sync.RWMutex
lock = new(sync.RWMutex)
或者
lock := &sync.RWMutex{}
RWMutex 里提供了两种锁,每种锁分别对应两个方法,为了避免死锁,两个方法应成对出现,必要时请使用 defer 。
- 读锁:调用
RLock方法开启锁,调用RUnlock释放锁; - 写锁:调用
Lock方法开启锁,调用Unlock释放锁。
下面是摘自网络上的一个例子:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
// 创建读写互斥锁
lock := &sync.RWMutex{}
// 写锁开启
lock.Lock()
// 开启四个协程
for i := 0; i < 4; i++ {
go func(i int) {
fmt.Printf("第 %d 个协程准备开始... \n", i)
// 读锁开启
lock.RLock()
fmt.Printf("第 %d 个协程获得读锁, sleep 1s 后,释放锁\n", i)
time.Sleep(time.Second)
// 读锁释放
lock.RUnlock()
}(i)
}
time.Sleep(time.Second * 2)
fmt.Println("准备释放写锁,读锁不再阻塞")
// 写锁释放 读锁自由
lock.Unlock()
// 由于会等到读锁全部释放,才能获得写锁
// 因为这里一定会在上面 4 个协程全部完成才能往下走
lock.Lock()
fmt.Println("程序退出...")
lock.Unlock()
}
运行输出如下:
第 3 个协程准备开始...
第 1 个协程准备开始...
第 2 个协程准备开始...
第 0 个协程准备开始...
准备释放写锁,读锁不再阻塞
第 0 个协程获得读锁, sleep 1s 后,释放锁
第 2 个协程获得读锁, sleep 1s 后,释放锁
第 3 个协程获得读锁, sleep 1s 后,释放锁
第 1 个协程获得读锁, sleep 1s 后,释放锁
程序退出...
Go 语言系列29:错误处理
在 Go 中, 错误 使用内建的 error 类型表示。 error 类型是一个接口类型,它的定义如下:
type error interface {
Error() string
}
error 有了一个签名为 Error() string 的方法。所有实现该接口的类型都可以当作一个错误类型。 Error() 方法给出了错误的描述。 fmt.Println 在打印错误时,会在内部调用 Error() string 方法来得到该错误的描述。
下面的例子演示了程序尝试打开一个不存在的文件导致的报错:
package main
import (
"fmt"
"os"
)
func main() {
// 尝试打开文件
file, err := os.Open("/a.txt")
// 如果打开文件时发生错误 返回一个不等于 nil 的错误
if err != nil {
fmt.Println(err)
return
}
// 如果打开文件成功 返回一个文件句柄 和 一个值为 nil 的错误
fmt.Println(file.Name(), "opened successfully")
}
我们这里没有存在一个文件 a.txt ,所以尝试打开文件将会返回一个不等于 nil 的错误,在程序中我们简单的将其进行输出。所以运行程序输出如下:
open /a.txt: The system cannot find the file specified.
自定义错误
使用 errors 包中的 New 函数可以创建自定义错误。下面是 errors 包中 New 函数的实现代码:
package errors
// New returns an error that formats as the given text.
// Each call to New returns a distinct error value even if the text is identical.
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
errorString 是一个结构体类型,只有一个字符串字段 s 。它使用了 errorString 指针接受者,来实现 error 接口的 Error() string 方法。 New 函数有一个字符串参数,通过这个参数创建了 errorString 类型的变量,并返回了它的地址。于是它就创建并返回了一个新的错误。
下面是一个简单的自定义错误例子,该例子创建了一个计算矩形面积的函数,当矩形的长和宽两者有一个为负数时,就会返回一个错误:
package main
import (
"errors"
"fmt"
)
func rectangleArea(a, b int) (int, error) {
if a < 0 || b < 0 {
return 0, errors.New("area calculation failed, Length or width is less than zero")
}
return a * b, nil
}
func main() {
a := 100
b := -10
area, err := rectangleArea(a, b)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Area =", area)
}
运行上面的程序会报出自定义的错误:
area calculation failed, Length or width is less than zero
给错误添加更多信息
上面的程序能报出我们自定义的错误,但是没有具体说明是哪个数据出了问题,所以下面就来改进一下这个程序,我们使用 fmt 包中的 Errorf 函数,规定错误格式,并返回一个符合该错误的字符串。
package main
import (
"fmt"
)
func rectangleArea(a, b int) (int, error) {
if a < 0 || b < 0 {
return 0, fmt.Errorf("area calculation failed, Length %d or width %d is less than zero", a, b)
}
return a * b, nil
}
func main() {
a := 100
b := -10
area, err := rectangleArea(a, b)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Area =", area)
}
运行上面的程序,我们可以看到输出的错误中打印了长度和宽度的具体值:
area calculation failed, Length 100 or width -10 is less than zero
当然,给错误添加更多信息还可以 使用结构体类型和字段 实现。下面还是通过改进上面的程序来讲解这种方法的实现:
首先创建一个表示错误的结构体类型,一般错误类型名称都是以 Error 结尾,上面的错误是由于面积计算中长度或宽度错误导致的,所以这里把结构体命名为 areaError :
type areaError struct {
// 错误信息
err string
// 错误有关的长度
length int
// 错误有关的宽度
width int
}
接下来当然是实现 error 接口啦:
// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
func (e *areaError) Error() string {
// 打印长度和宽度以及错误的描述
return fmt.Sprintf("length %d, width %d : %s", e.length, e.width, e.err)
}
下面是整个程序的代码:
package main
import (
"fmt"
)
type areaError struct {
// 错误信息
err string
// 错误有关的长度
length int
// 错误有关的宽度
width int
}
// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
func (e *areaError) Error() string {
// 打印长度和宽度以及错误的描述
return fmt.Sprintf("length %d, width %d : %s", e.length, e.width, e.err)
}
func rectangleArea(a, b int) (int, error) {
if a < 0 || b < 0 {
return 0, &areaError{"length or width is negative", a, b}
}
return a * b, nil
}
func main() {
a := 100
b := -10
area, err := rectangleArea(a, b)
// 检查了错误是否为 nil
if err != nil {
// 断言 *areaError 类型
if err, ok := err.(*areaError); ok {
// 如果错误是 *areaError 类型
// 用 err.length 和 err.width 来获取错误的长度和宽度 打印出自定义错误的消息
fmt.Printf("length %d or width %d is less than zero", err.length, err.width)
return
}
fmt.Println(err)
return
}
fmt.Println("Area =", area)
}
运行该程序输出如下:
length 100 or width -10 is less than zero
当然,我们还可以使用 结构体类型的方法 来给错误添加更多信息。下面我们继续完善上面的程序,让程序更加精确的定位是长度引发的错误还是宽度引发的错误。
首先,我们还是跟上面一样创建一个表示错误的结构体:
type areaError struct {
// 错误信息
err string
// 长度引发的错误
length int
// 宽度引发的错误
width int
}
下面还是一样实现 error 接口,这里给错误类型添加了两个方法,使它提供更多的错误信息:
// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
func (e *areaError) Error() string {
return e.err
}
// 长度为负数返回 true
func (e *areaError) lengthNegative() bool {
return e.length < 0
}
// 宽度为负数返回 true
func (e *areaError) widthNegative() bool {
return e.width < 0
}
接下来就是修改计算面积的函数了:
func rectangleArea(length, width int) (int, error) {
err := ""
if length < 0 {
err += "length is less than zero"
}
if width < 0 {
if err == "" {
err = "width is less than zero"
} else {
err += " and width is less than zero"
}
}
if err != "" {
return 0, &areaError{err, length, width}
}
return length * width, nil
}
最后我们编写主函数,整个程序如下:
package main
import (
"fmt"
)
type areaError struct {
// 错误信息
err string
// 长度引发的错误
length int
// 宽度引发的错误
width int
}
// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
func (e *areaError) Error() string {
return e.err
}
// 长度为负数返回 true
func (e *areaError) lengthNegative() bool {
return e.length < 0
}
// 宽度为负数返回 true
func (e *areaError) widthNegative() bool {
return e.width < 0
}
func rectangleArea(length, width int) (int, error) {
err := ""
if length < 0 {
err += "length is less than zero"
}
if width < 0 {
if err == "" {
err = "width is less than zero"
} else {
err += " and width is less than zero"
}
}
if err != "" {
return 0, &areaError{err, length, width}
}
return length * width, nil
}
func main() {
length := 100
width := -10
area, err := rectangleArea(length, width)
// 检查了错误是否为 nil
if err != nil {
// 断言 *areaError 类型
if err, ok := err.(*areaError); ok {
// 如果错误是 *areaError 类型
// 如果长度为负数 打印错误长度具体值
if err.lengthNegative() {
fmt.Printf("error: length %d is less than zero\n", err.length)
}
// 如果宽度为负数 打印错误宽度具体值
if err.widthNegative() {
fmt.Printf("error: width %d is less than zero\n", err.width)
}
return
}
fmt.Println(err)
return
}
fmt.Println("Area =", area)
}
还是使用之前的例子中的参数,但我们这次报错结果更加具体,运行该程序输出如下:
error: width -10 is less than zero
Go 语言系列30:异常处理
错误和 异常 是两个不同的概念,非常容易混淆。错误指的是可能出现问题的地方出现了问题;而异常指的是不应该出现问题的地方出现了问题。
panic
在有些情况,当程序发生异常时,无法继续运行。在这种情况下,我们会使用 panic 来终止程序。当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序控制返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。
我们应该尽可能地使用错误,而不是使用 panic 和 recover 。只有当程序不能继续运行的时候,才应该使用 panic 和 recover 机制。
panic 有两个合理的用例:
- 发生了一个不能恢复的错误,此时程序不能继续运行。一个例子就是 web 服务器无法绑定所要求的端口。在这种情况下,就应该使用
panic,因为如果不能绑定端口,啥也做不了。 - 发生了一个编程上的错误。假如我们有一个接收指针参数的方法,而其他人使用
nil作为参数调用了它。在这种情况下,我们可以使用panic,因为这是一个编程错误:用nil参数调用了一个只能接收合法指针的方法。
触发 panic
下面是内建函数 panic 的签名:
func panic(v interface{})
当程序终止时,会打印传入 panic 的参数。
package main
func main() {
panic("runtime error")
}
运行上面的程序,会打印出传入 panic 函数的信息,并打印出堆栈跟踪:
panic: runtime error
goroutine 1 [running]:
main.main()
(...)/main.go:4 +0x27
发生 panic 时的 defer
上面已经提到了,当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序控制返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。下面通过一个简单的例子看看是不是这样:
package main
import "fmt"
func myTest() {
defer fmt.Println("defer in myTest")
panic("runtime error")
}
func main() {
defer fmt.Println("defer in main")
myTest()
}
运行该程序后输出如下:
defer in myTest
defer in main
panic: runtime error
goroutine 1 [running]:
main.myTest()
(...)/main.go:7 +0x73
main.main()
(...)/main.go:11 +0x70
recover
recover 是一个内建函数,用于重新获得 panic 协程的控制。下面是内建函数 recover 的签名:
func recover() interface{}
recover 必须在 defer 函数中才能生效,在其他作用域下,它是不工作的。在延迟函数内调用 recover ,可以取到 panic 的错误信息,并且停止 panic 续发事件,程序运行恢复正常。下面是网上找的一个例子:
package main
import "fmt"
func myTest(x int) {
defer func() {
// recover() 可以将捕获到的 panic 信息打印
if err := recover(); err != nil {
fmt.Println(err)
}
}()
var array [10]int
array[x] = 1
}
func main() {
// 故意制造数组越界 触发 panic
myTest(20)
// 如果能执行到这句 说明 panic 被捕获了
// 后续的程序能继续运行
fmt.Println("everything is ok")
}
虽然该程序触发了 panic ,但由于我们使用了 recover() 捕获了 panic 异常,并输出 panic 信息,即使 panic 会导致整个程序退出,但在退出前,有 defer 延迟函数,还是得执行完 defer 。然后程序还会继续执行下去:
runtime error: index out of range [20] with length 10
everything is ok
这里要注意一点,只有在相同的协程中调用 recover 才管用, recover 不能恢复一个不同协程的 panic 。
package main
import (
"fmt"
"time"
)
func main() {
// 这个 defer 并不会执行
defer fmt.Println("in main")
go func() {
defer println("in goroutine")
panic("")
}()
time.Sleep(time.Second)
}
运行后输出如下:
in goroutine
panic:
goroutine 19 [running]:
main.main.func1()
(...)/main.go:13 +0x7b
created by main.main
(...)/main.go:11 +0x79
Go 语言系列31:make 和 new
new 函数
内置函数 new 分配内存。该函数只接受一个参数,该参数是一个任意类型(包括自定义类型),而不是值,返回指向该类型新分配零值的指针。
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type
使用 new 函数首先会分配内存,并设置类型零值,最后返回指向该类型新分配零值的指针。
package main
import (
"fmt"
)
func main() {
num := new(int)
// 打印出类型的值
fmt.Println(*num)
}
运行上面的程序输出的就是类型零值:
0
make 函数
内置函数 make 只能分配和初始化类型为 slice 、 map 或 chan 的对象。与 new 一样,第一个参数是类型,而不是值。与 new 不同, make 的返回类型与其参数的类型相同,而不是指向它的指针。结果取决于类型:
slice:size 指定长度。切片的容量等于其长度。可提供第二整数参数以指定不同的容量;它不能小于长度。
map:为空映射分配足够的空间来容纳指定数量的元素。可以省略大小,在这种情况下,分配一个小的起始大小。
chan:使用指定的缓冲区容量初始化通道的缓冲区。如果为零,或者忽略了大小,则通道是无缓冲的。
func make(t Type, size ...IntegerType) Type
注意,使用 make 函数必须初始化。例如:
// slice
a := make([]int, 2, 10)
// map
b := make(map[string]int)
// chan
c := make(chan int, 10)
new 和 make 的区别
new:为所有的类型分配内存,并初始化为零值,返回指针。
make:只能为 slice 、 map 、 chan 分配内存,并初始化,返回的是类型。
Go 语言系列32:头等函数
Go 语言拥有 头等函数(First-class Function) ,头等函数是指函数可以被当作变量一样使用,即函数可以被当作参数传递给其他函数,可以作为另一个函数的返回值,还可以被赋值给一个变量。
把函数赋值给变量
下面是一个把函数赋值给变量的例子,该函数没有名称,调用该函数的唯一方法就是使用赋值后的变量。
package main
import "fmt"
func main() {
f := func() {
fmt.Println("First-class Function")
}
f()
fmt.Printf("type f is %T", f)
}
运行该程序输出如下:
First-class Function
type f is func()
传递一个函数作为参数
我们把 接收一个或多个函数作为参数 或者 返回值也是一个函数 的函数称为 高阶函数(Hiher-order Function) 。
下面的是把函数作为参数,并传递给其他函数的例子:
package main
import "fmt"
// printRes 接收一个函数参数
func printRes(add func(x, y int) int) {
fmt.Println(add(1, 5))
}
func main() {
// 创建匿名函数
f := func(x, y int) int {
return x + y
}
// 把匿名函数作为参数传入另一个函数
printRes(f)
}
运行程序输出如下:
6
返回一个函数
下面的是函数返回一个函数的例子:
package main
import "fmt"
// add 返回一个函数
func add() func(x, y int) int{
return func(x, y int) int {
return x + y
}
}
func main() {
// 变量获取返回的函数
a := add()
// 调用返回的函数
fmt.Println(a(50, 6))
}
运行程序输出如下:
56
闭包
闭包(Closure) 是匿名函数的一个特例。当一个匿名函数所访问的变量定义在函数体的外部时,就称这样的匿名函数为闭包。
package main
import "fmt"
func main() {
x := 100
func() {
fmt.Println(x)
}()
}
运行该程序会输出:
100
Go 语言系列33:静态类型与动态类型
静态类型
静态类型(static type) 就是变量声明时候的类型。例如:
// int 是静态类型
var number int
// string 也是静态类型
var name string
动态类型
动态类型(concrete type) 是程序运行时系统才能看见的类型。例如:
// in 的静态类型为 interface{}
var in interface{}
// in 的静态类型为 interface{} 动态类型为 int
in = 100
// in 的静态类型为 interface{} 动态类型为 string
in = "菜籽爱编程"
通过上面的例子,可以看到我们定义了一个空接口 in ,它的静态类型永远是 interface{} ,但它可以接受任何类型,接受整型数据时,它的动态类型就为 int ;接受字符串型数据时,它的动态类型就变为 string 。
接口组成
每个接口变量实际上都是由一 pair 对组成,其中记录了实际变量的值和类型。例如:
var number int = 100
这里声明了一个类型为 int 的变量,变量名叫 number 值为 100 。知道了接口的组成,我们也可以使用下面的方式定义一个变量:
package main
import "fmt"
func main() {
number := (int)(100)
// 或者写成 number := (interface{})(100)
fmt.Printf("number type: %T, data: %v", number, number)
}
运行上面的程序输出如下:
number type: int, data: 100
Go 语言系列34:协程池
在其他语言中,为了减少线程频繁创建销毁带来的开销,通常我们会使用线程池来复用线程。在 Go 中, goroutine 是一个轻量级的线程,他的创建、调度都是在用户态进行,并不需要进入内核,这意味着创建销毁协程带来的开销是非常小的。因此,在大多数情况下是不太需要使用协程池的。但这一期我们还是讲一讲协程池,说不定哪天要用上了呢?
创建协程池结构体
第一步,我们定义一个 协程池(Pool) 结构体,其中包含两个属性。
type Pool struct {
work chan func() // 接收 task 任务
sem chan struct{} // 设置协程池大小 即可同时执行的协程数量
}
创建协程池对象函数
定义一个 New 函数,用于创建一个协程池对象。
// New 创建一个协程池对象 size 为协程池大小
func New(size int) *Pool {
return &Pool{
work: make(chan func()),
sem: make(chan struct{}, size),
}
}
执行任务函数
绑定一个执行任务的函数 worker ,这里使用了 for 无限循环,使协程在执行完任务后,也不退出,而是一直在接收新的任务。
// worker 执行任务
func (p *Pool) worker(task func()) {
defer func() { <-p.sem }()
for {
task()
task = <-p.work
}
}
添加任务函数
绑定一个往协程池中添加任务的函数 NewTask 。第一次调用 NewTask 添加任务的时候,由于 work 是无缓冲通道,所以会一定会走第二个 case 的分支:使用 go worker 开启一个协程。
// NewTask 添加任务
func (p *Pool) NewTask(task func()) {
select {
case p.work <- task:
case p.sem <- struct{}{}:
go p.worker(task)
}
}
协程池的使用
下面是一个协程池的例子:
func main() {
pool := New(128)
pool.NewTask(func(){
fmt.Println("run task")
})
}
当然,这一期讲的也只是一个最最简单的实现,如果要了解更多关于协程池的知识,还请自行上网查阅相关资料。
Go 语言系列35:使用 GDB 调试
对于 C 语言学习者来说,使用 GDB 调试应该是很熟悉的事情。这一期我们就来简单讲一讲在 Go 语言中如何使用 GDB 在 Linux 上进行调试。
在 Linux 上安装 Go
首先还是来到 Go 语言官网,找到下载地址并复制:
https://go.dev/dl/go1.17.5.linux-amd64.tar.gz
在 Linux 命令行下使用 wget 下载:
$ wget https://go.dev/dl/go1.17.5.linux-amd64.tar.gz
下载完成后,使用 tar 命令把包解压到 /usr/local 目录下:
$ tar -C /usr/local -xzf go1.17.5.linux-amd64.tar.gz
解压后再设置环境变量:
$ export PATH=$PATH:/usr/local/go/bin
再使用 which 命令检查 go 环境配置。
$ which go
/usr/local/go/bin/go
接着使用下面命令检查 go 是否安装成功:
$ go version
go version go1.17.5 linux/amd64
开始调试
首先要在 Linux 上安装 GDB ,我用的是 Ubuntu ,使用的命令如下:
$ apt-get update
$ apt-get install gdb
安装完成后,我们检查是否安装成功:
$ which gdb
/usr/bin/gdb
一切准备就绪,先创建一个目录,在该目录下写一个 main.go 测试文件:
package main
import "fmt"
func main(){
message := "Let's go"
fmt.Println(message)
}
首先,我们编译刚刚的测试文件:
$ go build -gcflags "-N -l" main.go
编译完成后使用下面的命令调试 main 程序:
$ gdb main
接下来我们设置断点,这里设置为 main 包的 main 函数:
GNU gdb (Ubuntu 9.2-0ubuntu1~20.04) 9.2
Copyright (C) 2020 Free Software Foundation, Inc.
...
(gdb) b main.main
Breakpoint 1 at 0x47e2e0: file /home/caizi/go-36/main.go, line 5.
然后执行 run 命令执行程序:
(gdb) run
Starting program: /home/caizi/go-36/main
[New LWP 2814]
[New LWP 2815]
[New LWP 2816]
Thread 1 "main" hit Breakpoint 1, main.main () at /home/caizi/go-36/main.go:5
5 func main(){
然后使用 c 命令继续执行到下一个断点,因为我们没有设置其他断点,所以运行完整个程序后退出:
(gdb) c
Continuing.
Let's go
[LWP 2815 exited]
[LWP 2814 exited]
[LWP 2810 exited]
[Inferior 1 (process 2810) exited normally]
使用 q 命令退出 gdb :
(gdb) q
$
当然,你也可以使用下面的命令以 TUI 模式调试程序:
$ gdb -tui main
运行此命令你会看到一个可视化调试界面:
同样,我们设置断点后执行程序,这次我们使用 n 命令执行下一步:

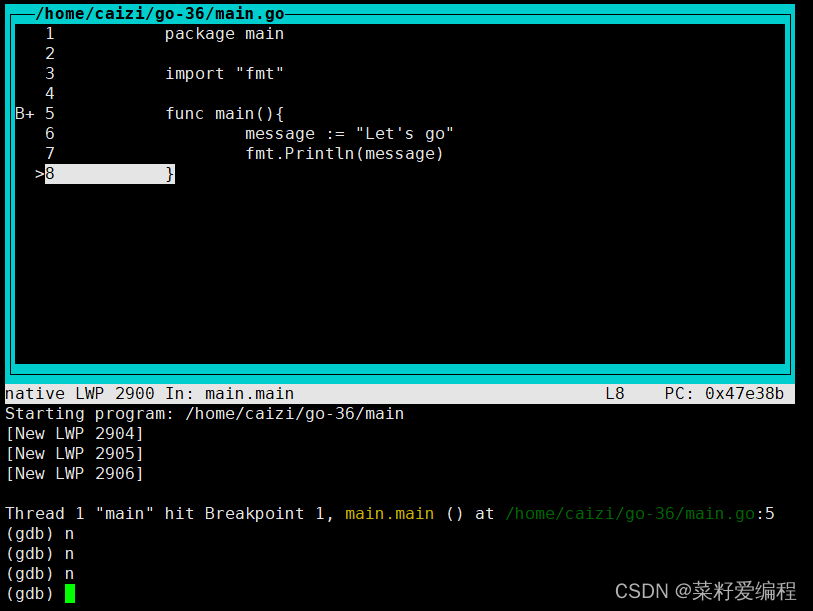
GDB 调试指令
下面简单的列出了 GDB 常用的指令,要想熟练掌握 GDB 调试,看这一篇文章肯定是不够的,以后有机会再详细讲一讲 GDB 调试。
| 命令 | 含义 |
|---|---|
| r | (run)执行程序 |
| n | (next)下一步(不进入函数) |
| s | (step)下一步(会进入函数) |
| b | (breakponit)设置断点 |
| l | (list)查看指定源码指定行数范围/查看函数 |
| c | (continue)继续执行到下一断点 |
| bt | (backtrace)查看当前调用栈 |
| p | (print)打印查看变量 |
| q | (quit)退出GDB |
| whatis | 查看对象类型 |
| info breakpoints | 查看所有的断点 |
| info locals | 查看局部变量 |
| info args | 查看函数的参数值及要返回的变量值 |
| info frame | 堆栈帧信息 |
| 回车 | 重复执行上一次操作 |
Go 语言系列36:反射
Go 语言提供了一种机制,能够在运行时更新变量和检查它们的值、调用它们的方法和它们支持的内在操作,而不需要在编译时就知道这些变量的具体类型。这种机制被称为 反射 。
但反射是把双刃剑,功能强大但代码可读性并不理想,若非必要并不推荐使用反射。
在 Go 中, reflect 包实现了运行时反射。 reflect 包会帮助识别 interface{} 变量的底层具体类型和具体值。
reflect.Type
reflect.Type 表示 interface{} 的具体类型。 reflect.TypeOf() 方法返回 reflect.Type 。
像我们之前讲过的空接口参数的函数,可以通过类型断言来判断传入变量的类型,也可以借助反射来确定传入变量的类型。
package main
import (
"fmt"
"reflect"
)
func reflectType(x interface{}) {
obj := reflect.TypeOf(x)
fmt.Println(obj)
}
func main() {
var a int64 = 123
reflectType(a)
var b float64 = 3.14
reflectType(b)
}
该程序运行后输出结果如下:
int64
float64
reflect.Value
reflect.Value 表示 interface{} 的具体值。 reflect.ValueOf() 方法返回 reflect.Value 。
package main
import (
"fmt"
"reflect"
)
func reflectType(x interface{}) {
typeX := reflect.TypeOf(x)
valueX := reflect.ValueOf(x)
fmt.Println(typeX)
fmt.Println(valueX)
}
func main() {
var a int64 = 123
reflectType(a)
var b float64 = 3.14
reflectType(b)
}
该程序运行后输出结果如下:
int64
123
float64
3.14
relfect.Kind
relfect.Kind 表示的是种类。在使用反射时,需要理解类型(Type)和种类(Kind)的区别。编程中,使用最多的是类型,但在反射中,当需要区分一个大品种的类型时,就会用到种类(Kind)。
Go 语言程序中的类型(Type)指的是系统原生数据类型,如 int 、 string 、 bool 、 float32 等类型,以及使用 type 关键字定义的类型,这些类型的名称就是其类型本身的名称。例如使用 type A struct{} 定义结构体时,A 就是 struct{} 的类型。
种类(Kind)指的是对象归属的品种,在 reflect 包中有如下定义:
// A Kind represents the specific kind of type that a Type represents.
// The zero Kind is not a valid kind.
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
通过下面这个程序,相信你会很容易明白这两者的区别:
package main
import (
"fmt"
"reflect"
)
func reflectType(x interface{}) {
typeX := reflect.TypeOf(x)
fmt.Println(typeX.Kind()) // struct
fmt.Println(typeX) // main.cat
}
type cat struct {
}
func main() {
var a cat
reflectType(a)
}
该程序运行后输出结果如下:
struct
main.cat
relfect.NumField()
relfect.NumField() 方法返回结构体中字段的数量。
package main
import (
"fmt"
"reflect"
)
func reflectNumField(x interface{}) {
// 检查 x 的类别是 struct
if reflect.ValueOf(x).Kind() == reflect.Struct {
v := reflect.ValueOf(x)
fmt.Println("Number of fields", v.NumField())
}
}
type cat struct {
name string
age int
}
func main() {
var a cat
reflectNumField(a)
}
该程序运行后输出结果如下:
Number of fields 2
relfect.Field()
relfect.Field(i int) 方法返回字段 i 的 reflect.Value 。
package main
import (
"fmt"
"reflect"
)
func reflectNumField(x interface{}) {
// 检查 x 的类别是 struct
if reflect.ValueOf(x).Kind() == reflect.Struct {
v := reflect.ValueOf(x)
fmt.Println("Number of fields", v.NumField())
for i := 0; i < v.NumField(); i++ {
fmt.Printf("Field:%d type:%T value:%v\n", i, v.Field(i), v.Field(i))
}
}
}
type cat struct {
name string
age int
}
func main() {
var a = cat{"哆啦A梦", 10}
reflectNumField(a)
}
该程序运行后输出结果如下:
Number of fields 2
Field:0 type:reflect.Value value:哆啦A梦
Field:1 type:reflect.Value value:10
Go 语言系列37:反射三大定律
在上面我们讲过,一个接口变量,实际上都是由一 pair 对(type 和 data)组合而成,pair 对中记录着实际变量的值和类型。也就是说在真实世界(反射前环境)里,type 和 value 是合并在一起组成接口变量的。
而在反射的世界(反射后的环境)里,type 和 data 却是分开的,他们分别由 reflect.Type 和 reflect.Value 来表现。
Go 语言里有反射三定律,是你在学习反射时,很重要的参考:
- Reflection goes from interface value to reflection object.
- Reflection goes from reflection object to interface value.
- To modify a reflection object, the value must be settable.
接下来我们就来讲一讲反射三大定律。
反射第一定律
Reflection goes from interface value to reflection object.
反射第一定律:反射可以将“接口类型变量”转换为“反射类型对象”。
这里反射类型指 reflect.Type 和 reflect.Value 。
通过之前我们讲过的 reflect.TypeOf() 方法和 reflect.ValueOf() 方法可以分别获得接口值的类型和接口值的值。这两个方法返回的对象,我们称之为反射对象。
package main
import (
"fmt"
"reflect"
)
func main() {
var a interface{} = 3.14
fmt.Printf("接口变量的类型为 %T ,值为 %v\n", a, a)
t := reflect.TypeOf(a)
v := reflect.ValueOf(a)
fmt.Printf("从接口变量到反射对象:Type对象类型为 %T\n", t)
fmt.Printf("从接口变量到反射对象:Value对象类型为 %T\n", v)
}
运行该程序输出结果如下:
接口变量的类型为 float64 ,值为 3.14
从接口变量到反射对象:Type对象类型为 *reflect.rtype
从接口变量到反射对象:Value对象类型为 reflect.Value
可以看到,使用 reflect.TypeOf() 和 reflect.ValueOf() 方法完成了从接口类型变量到反射对象的转换。在这里说接口类型是因为 TypeOf 和 ValueOf 两个函数接收的是 interface{} 空接口类型, Go 语言函数都是值传递,会将类型隐式转换成接口类型。
反射第二定律
Reflection goes from reflection object to interface value.
反射第二定律:反射可以将“反射类型对象”转换为“接口类型变量”
第二定律刚好和第一定律相反,第一定律讲的是从接口变量到反射对象的转换,而第二定律讲的是从反射对象到接口变量的转换。
一个 reflect.Value 类型的变量,我们可以使用 Interface 方法恢复其接口类型的值。事实上,这个方法会把 type 和 value 信息打包并填充到一个接口变量中,然后返回。
其函数声明如下:
// Interface returns v's current value as an interface{}.
// It is equivalent to:
// var i interface{} = (v's underlying value)
// It panics if the Value was obtained by accessing
// unexported struct fields.
func (v Value) Interface() (i interface{}) {
return valueInterface(v, true)
}
最后转换后的对象静态类型为 interface{} ,我们可以使用类型断言转换为原始类型。
package main
import (
"fmt"
"reflect"
)
func main() {
var a interface{} = 3.14
fmt.Printf("接口变量的类型为 %T ,值为 %v\n", a, a)
t := reflect.TypeOf(a)
v := reflect.ValueOf(a)
// 反射第一定律
fmt.Printf("从接口变量到反射对象:Type对象类型为 %T\n", t)
fmt.Printf("从接口变量到反射对象:Value对象类型为 %T\n", v)
// 反射第二定律
i := v.Interface()
fmt.Printf("从反射对象到接口变量:对象类型为 %T,值为 %v\n", i, i)
// 使用类型断言进行转换
x := v.Interface().(float64)
fmt.Printf("x 类型为 %T,值为 %v\n", x, x)
}
运行该程序输出结果如下:
接口变量的类型为 float64 ,值为 3.14
从接口变量到反射对象:Type对象类型为 *reflect.rtype
从接口变量到反射对象:Value对象类型为 reflect.Value
从反射对象到接口变量:对象类型为 float64,值为 3.14
x 类型为 float64,值为 3.14
反射第三定律
To modify a reflection object, the value must be settable.
反射第三定律:如果要修改“反射类型对象”其值必须是“可写的”
我们首先来看一看下面这段代码:
package main
import "reflect"
func main() {
var a float64 = 3.14
v := reflect.ValueOf(a)
v.SetFloat(2.1)
}
运行该代码段将会抛出异常:
panic: reflect: reflect.Value.SetFloat using unaddressable value
这里你可能会疑惑,为什么这里会抛出寻址的异常,其实是因为这里的变量 v 是“不可写的”。 settable(“可写性”)是反射类型变量的一个属性,但也不是说所有的反射类型变量都有这个属性。
要想知道一个 reflect.Value 类型变量的“可写性”,我们可以使用 CanSet 方法来进行检查:
package main
import (
"fmt"
"reflect"
)
func main() {
var a float64 = 3.14
v := reflect.ValueOf(a)
fmt.Println("是否可写:", v.CanSet())
}
运行该程序输出结果如下:
是否可写: false
可以看到,我们这个变量 v 是不可写的。对于一个不可写的变量,使用 Set 方法会报错。这里实质上还是 Go 语言里的函数都是值传递问题,想象一下这里传递给 reflect.ValueOf 函数的是变量 a 的一个拷贝,而非 a 本身,所以如果对反射对象进行更新,其原始变量 a 根本不会受到影响,所以是不合法的,“可写性”就是为了避免这个问题而设计出来的。
所以,要让反射对象具备“可写性”,一定要注意创建反射对象时要传入变量的指针,于是乎我们修改代码如下:
package main
import (
"fmt"
"reflect"
)
func main() {
var a float64 = 3.14
v := reflect.ValueOf(&a)
fmt.Println("是否可写:", v.CanSet())
}
但运行该程序还是会输出不可写:
是否可写: false
因为事实上我们这里要修改的是该指针指向的数据,使用还要使用 Value 类型的 Elem() 方法,对指针进行“解引用”,该方法返回指针指向的数据。
package main
import (
"fmt"
"reflect"
)
func main() {
var a float64 = 3.14
v := reflect.ValueOf(&a).Elem()
fmt.Println("是否可写:", v.CanSet())
v.SetFloat(2)
fmt.Println(v)
}
运行该程序输出如下:
是否可写: true
2
Go 语言系列38:结构体里的 Tag 标签
在之前 Go 语言系列14:结构体 我们讲过结构体的使用,一般情况下,我们定义结构体每个字段都是由字段名字以及字段的类型构成,例如:
type Person struct {
Name string
Age int
Gender string
}
Tag 的使用
但这一期要讲的是在字段上增加一个属性,这个属性是用反引号括起来的一个字符串,我们称之为 Tag(标签) 。例如:
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Gender string `json:"gender,omitempty"`
}
结构体的 Tag 可以是任意的字符串面值,但是通常是一系列用空格分隔的 key:"value" 键值对序列;因为值中含有双引号字符,因此成员 Tag 一般用原生字符串面值的形式书写。一般我们常用在 JSON 的数据处理方面。
json 开头键名对应的值用于控制 encoding/json 包的编码和解码的行为,并且 encoding/… 下面其它的包也遵循这个约定。 Tag 中 json 对应值的第一部分用于指定 JSON 对象的名字,比如将 Go 语言中的 TotalCount 成员对应到 JSON 中的 total_count 对象。
上面的例子中 gender 字段的 Tag 还带了一个额外的 omitempty 选项,表示当 Go 语言结构体成员为空或零值时不生成该 JSON 对象(这里 false 为零值)。例如:
package main
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Gender string `json:"gender,omitempty"`
}
func main() {
// Person 1 without Gender
person1 := Person{
Name: "菜籽",
Age: 25,
}
// 结构体转为 JSON
data1, err := json.Marshal(person1)
if err != nil {
panic(err)
}
// person1 won't print Gender attribute
fmt.Printf("%s\n", data1)
// Person 2 have Gender attribute
person2 := Person{
Name: "Tom",
Age: 18,
Gender: "male",
}
// 结构体转为 JSON
data2, err := json.Marshal(person2)
if err != nil {
panic(err)
}
// person2 will print Gender attribute
fmt.Printf("%s\n", data2)
}
运行该程序输出如下的结果:
{"name":"菜籽","age":25}
{"name":"Tom","age":18,"gender":"male"}
可以看到,因为 Gender 字段里有 omitempty 属性,因此 encoding/json 在将此结构体对象转化为 JSON 字符串时,发现对象里面的 Gender 为 false , 0 ,空指针,空接口,空数组,空切片,空映射,空字符串中的一种,就会被忽略。
Tag 的获取
Tag 的格式上面已经说了,它是由反引号括起来的一系列用空格分隔的 key:"value" 键值对序列:
`key1:"value1" key2:"value2" key3:"value3"`
那么我们如何获取到结构体中的 Tag 呢?这里我们用反射的方法。
使用反射的方法获取 Tag 步骤如下:
- 获取字段
- 获取 Tag
- 获取键值对
其中获取字段有三种方式,而获取键值对有两种方式。
// 三种获取 field
field := reflect.TypeOf(obj).FieldByName("Name")
field := reflect.ValueOf(obj).Type().Field(i) // i 表示第几个字段
field := reflect.ValueOf(&obj).Elem().Type().Field(i) // i 表示第几个字段
// 获取 Tag
tag := field.Tag
// 获取键值对
labelValue := tag.Get("label")
labelValue,ok := tag.Lookup("label")
// Get 当没有获取到对应 Tag 的内容,会返回空字符串
下面是一个获取 Tag 以及键值对的例子:
package main
import (
"fmt"
"reflect"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Gender string `json:"gender,omitempty"`
}
func main() {
p := reflect.TypeOf(Person{})
name, _ := p.FieldByName("Name")
tag := name.Tag
fmt.Println("Name Tag :", tag)
keyValue, _ := tag.Lookup("json")
fmt.Println("key: json, value:", keyValue)
}
运行上面的程序输出如下:
Name Tag : json:"name"
key: json, value: name
Go 语言系列39: Go 语言中的 Context
什么是 Context
Go 1.7 标准库引入 Context(上下文) ,准确说它是 goroutine 的上下文,包含 goroutine 的运行状态、环境、现场等信息。 Context 主要用来在 goroutine 之间传递上下文信息。 Context 几乎成为了并发控制和超时控制的标准做法。
Context 接口定义如下:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
可以看到 Context 接口共有 4 个方法:
Deadline():返回的第一个值是 context 的截止时间,到了这个时间点,Context 会自动触发 Cancel 动作。返回的第二个值是布尔值,true表示设置了截止时间,false表示没有设置截止时间,如果没有设置截止时间,就要手动调用 cancel 函数取消 Context 。Done():返回一个只读的通道(只有在被 cancel 后才会返回),类型为struct{}。在子协程里读这个 channel ,除非被关闭,否则读不出任何东西,根据这一点,就可以做一些清理动作,退出 goroutine 。Err():返回 context 被 cancel 的原因。例如是被取消,还是超时。Value():返回被绑定到 Context 的值,是一个键值对,所以要通过一个 Key 才可以获取对应的值,这个值一般是线程安全的。
上面这些方法都是用于读取的,不能进行设置。
使用 Context 控制协程
一个协程开启后,我们无法强制关闭,一般关闭协程的原因有以下几种:
- 协程执行完正常退出
- 主协程退出,子协程被迫退出
- 通过信道发送信号,引导协程关闭
下面是一个使用信道控制协程的例子:
package main
import (
"fmt"
"time"
)
func main() {
// 定义 chan
c := make(chan bool)
go func() {
for {
select {
case <- c:
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("监控子协程中...")
time.Sleep(2 * time.Second)
}
}
}()
time.Sleep(10 * time.Second)
fmt.Println("通知监控停止")
c <- true
// 为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
上面的程序中,我们定义了一个 chan ,通过该 chan 引导子协程关闭。开启子协程后,我们让主协程休眠 10s ,子协程不断循环,使用 select 判断 chan 是否可以接收到值,如果可以接收到,则退出子协程;否则执行 default 继续监控,直到接收到值为止。该程序运行后输出如下:
监控子协程中...
监控子协程中...
监控子协程中...
监控子协程中...
监控子协程中...
通知监控停止
监控退出,停止了...
这证明了我们可以通过信道引导协程的关闭。
当然,使用信道可以控制多个协程,下面是使用一个信道控制多个子协程的例子:
package main
import (
"fmt"
"time"
)
func monitor(c chan bool, num int) {
for {
select {
case value := <- c:
fmt.Printf("监控器%v 接收值%v 监控结束\n", num, value)
return
default:
fmt.Printf("监控器%v 监控中...\n", num)
time.Sleep(2 * time.Second)
}
}
}
func main() {
c := make(chan bool)
for i := 0; i < 3; i++ {
go monitor(c, i)
}
time.Sleep(time.Second)
// 关闭所有的子协程
close(c)
// 为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
fmt.Println("主程序退出")
}
上面的代码中,我们使用 close 关闭通道后,如果该通道是无缓冲的,则它会从原来的阻塞变成非阻塞,也就是可读的,不过读到的会一直是零值,因此根据这个特性就可以判断拥有该通道的协程是否要关闭。运行该程序输出如下:
监控器0 监控中...
监控器1 监控中...
监控器2 监控中...
监控器2 接收值false 监控结束
监控器0 接收值false 监控结束
监控器1 接收值false 监控结束
主程序退出
到这里,我们一直讲的是使用信道控制协程,还没提到 Context 呢。那么既然能用信道控制协程,为什么还要用 Context 呢?因为使用 Context 更好用而且更优雅,下面是基于上面例子使用 Context 控制协程的代码:
package main
import (
"context"
"fmt"
"time"
)
func monitor(con context.Context, num int) {
for {
select {
// 判断 con.Done() 是否可读
// 可读就说明该 context 已经取消
case value := <- con.Done():
fmt.Printf("监控器%v 接收值%v 监控结束\n", num, value)
return
default:
fmt.Printf("监控器%v 监控中...\n", num)
time.Sleep(2 * time.Second)
}
}
}
func main() {
// 为 parent context 定义一个可取消的 context
con, cancel := context.WithCancel(context.Background())
for i := 0; i < 3; i++ {
go monitor(con, i)
}
time.Sleep(time.Second)
// 关闭所有的子协程
// 取消 context 的时候,只要调用一下 cancel 方法即可
// 这个 cancel 就是在创建 con 的时候返回的第二个值
cancel()
// 为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
fmt.Println("主程序退出")
}
运行该程序输出如下:
监控器2 监控中...
监控器0 监控中...
监控器1 监控中...
监控器0 接收值{} 监控结束
监控器2 接收值{} 监控结束
监控器1 接收值{} 监控结束
主程序退出
可以看到和上面使用信道控制协程的效果相同。
根 Context
创建 Context 必须要指定一个父 Context,创建第一个 Context 时,指定的父 Context 是 Go 中已经实现的 Context ,Go 中内置的 Context 有以下两个:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}
可以看到,其中一个内置的 Context 是 Background ,其主要用于 main 函数、初始化以及测试代码中,作为 Context 这个树结构的最顶层的 Context ,也就是根 Context ,它不能被取消。
而另一个内置的 Context 是 TODO ,当你不知道要使用什么 Context 的时候就可以使用这个,但其实看源码和上面那个内置的 Context 只是名称不一样罢了,一般使用上面那个。
再者,我们看到内置的 Context 都是 emptyCtx 结构体类型,查看源码不难发现,它是一个不可取消,没有设置截止时间,没有携带任何值的 Context 。
// An emptyCtx is never canceled, has no values, and has no deadline. It is not
// struct{}, since vars of this type must have distinct addresses.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}
Context API
context 包有几个 With 系列的函数,它们可以可以返回新 Context :
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context
以上函数都有一个共同点,第一个参数都接收一个父 context 。下面简要介绍上面这几个函数。
WithCancel()
它返回一个 context ,并返回一个 CancelFunc 无参函数,如果调用该函数,其会往 context.Done() 这个方法的 chan 发送一个取消信号。让所有监听这个 chan 的都知道该 context 被取消了。上面使用 Context 控制协程的例子已经演示了这一点。
WithDeadline()
它同样会返回一个 CancelFunc 无参函数,但它参数带有一个时间戳(time.Time),即截止时间,当到达截止时间, context.Done() 这个方法的 chan 就会自动接收到一个完成的信号。
WithTimeout()
这个函数和上面的 WithDeadline() 差不多,但它带有一个具体的时间段(time.Duration)。
WithDeadline() 传入的第二个参数是 time.Time 类型,它是一个绝对的时间,意思是在什么时间点超时取消。
而 WithTimeout() 传入的第二个参数是 time.Duration 类型,它是一个相对的时间,意思是多长时间后超时取消。
WithValue()
使用该函数可以在原有的 context 中可以添加一些值,然后返回一个新的 context 。这些数据以 Key-Value 的方式传入,Key 必须有可比性,Value 必须是线程安全的。
Request Context
下面简单讲一讲请求上下文, Request 有一个方法:
func (r *Request) Context() context.Context {
if r.ctx != nil {
return r.ctx
}
return context.Background()
}
该方法返回当前请求的上下文。还有一个方法:
func(*Request) WithContext(ctx context.Context) context.Context
该方法基于当前的 Context 进行“修改”,实际上是创建一个新的 Context ,因为 Context 是不允许修改的。下面是一个使用 Context 处理请求超时的例子,这个例子基于上一期的中间件的例子,先在 middleware 目录下补充中间件 TimeoutMiddleware :
package middleware
import (
"context"
"net/http"
"time"
)
type TimeoutMiddleware struct {
Next http.Handler
}
func (tm *TimeoutMiddleware) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if tm.Next == nil {
tm.Next = http.DefaultServeMux
}
// 获取当前请求的上下文
ctx := r.Context()
// “修改” Context 设置 2s 超时
ctx, _ = context.WithTimeout(ctx, 2 * time.Second)
// 创建一个新的 Context 代替当前请求的 Context
r.WithContext(ctx)
// 接收信号的信道
ch := make(chan struct{})
go func() {
tm.Next.ServeHTTP(w, r)
// 执行完给信道发送执行完信号
ch <- struct{}{}
}()
select {
// 正常处理能得到执行完信号 返回
case <-ch:
return
// 从 ctx.Done() 得到信号证明超时
// 返回超时响应
case <-ctx.Done():
w.WriteHeader(http.StatusRequestTimeout)
}
ctx.Done()
}
修改 main.go 把 TimeoutMiddleware 中间件套在 AuthMiddleware 外面:
package main
import (
"encoding/json"
"goweb/middleware"
"net/http"
"time"
)
type Person struct {
Name string
Age int64
}
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
p := Person{
Name: "Caizi",
Age: 18,
}
enc := json.NewEncoder(w)
enc.Encode(p)
})
http.ListenAndServe("localhost:8080", &middleware.TimeoutMiddleware{
Next: new(middleware.AuthMiddleware),
})
}
同样,我们利用上次的 test.http 进行测试:
GET http://localhost:8080/ HTTP/1.1
Authorization: a
测试的结果是正常的,接下来再修改 main.go 增加休眠 3s 代码,使其响应超时:
package main
import (
"encoding/json"
"goweb/middleware"
"net/http"
"time"
)
type Person struct {
Name string
Age int64
}
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
p := Person{
Name: "Caizi",
Age: 18,
}
// 休眠 3s
time.Sleep(3 * time.Second)
enc := json.NewEncoder(w)
enc.Encode(p)
})
http.ListenAndServe("localhost:8080", &middleware.TimeoutMiddleware{
Next: new(middleware.AuthMiddleware),
})
}
测试后结果返回 408 Request Timeout 。
Go 语言系列40:编码规范
这一期我们谈一谈 Go 语言的 编码规范 。一个统一的代码风格有利于提高代码的可读性、规范性和统一性。首先声明一点,这里的编码规范并不代表官方,只是参考网络上的一些文章以及 Go 语言官方代码风格的制定进行整理。
命名
包命名
- 保持
package的名字和目录保持一致 - 尽量采取有意义的包名
- 命名应该简短且有意义
- 命名尽量和标准库不要冲突
- 应该为小写单词
- 不要使用下划线或者混合大小写
文件命名
- 尽量采取有意义的文件名
- 文件名应该简短且有意义
- 由于
Windows平台文件名不区分大小写,所以文件名命名应该统一为小写 - 应该使用下划线分隔各个单词,而不是使用驼峰式命名
- 测试文件以
_test.go结尾 - 文件如果具有平台特性,应以
文件名_平台.go命名,例如utils_windows.go和utils_linux.go,可用平台有:windows, unix, posix, plan9, darwin, bsd, linux, freebsd, nacl, netbsd, openbsd, solaris, dragonfly, bsd, notbsd, android, stubs - 一般情况下应用主入口为
main.go或者以应用的全小写形式命名
常量命名
- 使用全大写且用下划线分隔各个单词,比如
APP_VERSION - 如果要定义多个常量,要使用
括号来组织
const (
APP_VERSION = "0.1.0"
CONF_PATH = "/etc/xx.conf"
)
当然网上还有另一种命名风格,那就是使用驼峰命名法,但我个人并不推荐这种命名风格。
变量命名
- 使用驼峰命名法
- 在相对简单的环境(对象数量少、针对性强)中,可以将完整单词简写为单个字母,例如:
user写为u - 首字母根据访问控制原则大写或者小写
- 如果变量为私有,且特有名词为首个单词,则使用小写,例如:
apiClient - 如果变量不是私有,但有特有名词,那首单词就要全部变成大写,例如:
APIClient - 如果变量类型为
bool类型,则名称应以has、is、can或allow开头,例如:isExist、canManage
结构体命名
- 使用驼峰命名法
- 首字母根据访问控制原则大写或者小写
struct声明和初始化格式采用多行
// 多行声明
type Person struct {
name string
gender string
age int
}
// 多行初始化
person := Person{
name: "John",
gender: "male",
age: 18,
}
接口命名
- 使用驼峰命名法
- 单个函数的结构名以
er作为后缀,例如:Reader、Writer
type Reader interface {
Read(p []byte) (n int, err error)
}
函数命名
- 使用驼峰命名法
- 对于需要在包外访问的函数要以大写字母开头命名
- 对于不需要在包外访问的函数要以小写字母开头命名
函数内部的参数的排列顺序也有几点原则:
- 参数的重要程度越高,应排在越前面
- 简单的类型应优先复杂类型
- 尽可能将同种类型的参数放在相邻位置,则只需写一次类型
注释
包注释
- 每个包都应该有一个包注释,它位于
package语句之前,可以是块注释或者行注释。如果一个包中有多个文件,则只需要在一个文件中编写,该文件一般是和包同名的文件 - 包注释应该包含下面基本信息(严格按照下面的顺序,简介,创建人,创建时间):
// 包的基本简介(包名,简介)
// 创建人: name
// 创建时间: yyyyMMdd
- 如果是特别复杂的包,可单独创建
doc.go文件说明 - 如果你想在每个文件中的头部加上注释,需要在版权注释和
package前面加一个空行,否则版权注释会作为package的注释
// Copyright 2010 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package fmt
结构体/接口注释
每个自定义的结构体或者接口都应该有注释说明,该注释对结构进行简要介绍,放在结构体定义的前一行,格式为: 结构体名, 结构体说明 。同时结构体内的每个成员变量都要有说明,该说明放在成员变量的后面(注意对齐),例如:
// User , 用户对象,定义了用户的基础信息
type User struct{
Username string // 用户名
Email string // 邮箱
}
函数/方法注释
每个函数或者方法都应该有注释说明,函数、方法和类型的注释说明都是一个完整的句子。当然还有下面这种注释习惯,该函数注释包括三个方面(严格按照下面的顺序):
// 函数名, 简要说明
// 参数:
// 参数1:参数说明
// 参数2:参数说明
// 返回值:
// 每行一个返回值
特别注释
TODO :提醒维护人员此部分代码待完成
FIXME :提醒维护人员此处有 BUG 待修复
NOTE :维护人员要关注的一些问题说明
其他注意点
- 所有导出对象都需要注释说明其用途;非导出对象根据情况进行注释
- 如果对象可数且无明确指定数量的情况下,一律使用单数形式和一般进行时描述;否则使用复数形式
- 句子类型的注释首字母均需大写;短语类型的注释首字母需小写
- 注释的单行长度不能超过
80个字符 - 若函数或方法为判断类型(返回值主要为
bool类型),则以<name> returns true if开头
代码风格
缩进和折行
- 使用
tab键进行缩进,或者直接使用gofmt工具格式化即可 - 折行方面,一行最长不超过
120个字符,超过的请使用换行展示
括号和空格
- 在 Go 语言中一定要注意括号的放置位置,大括号不换行
- 运算符和操作数之间要留空格
包的导入
- 单个包导入直接
import一行解决 - 多个包导入,要使用
()来组织 - 根据包的来源,标准库要排最前面,第三方包次之、项目内的其它包和当前包的子包排最后,每种分类以一空行分隔
- 不要使用相对路径来导入包
错误处理
- 不能丢弃任何有返回
err的调用,不要使用_丢弃,必须全部处理 - 接收到错误,要么返回
err,或者使用log记录下来 - 尽早
return,一旦有错误发生,马上返回 - 尽量不要使用
panic,除非你知道你在做什么 - 错误描述如果是英文必须为小写,不需要标点结尾
- 采用独立的错误流进行处理
参考文献:
[1] Alan A. A. Donovan; Brian W. Kernighan, Go 程序设计语言, Translated by 李道兵, 高博, 庞向才, 金鑫鑫 and 林齐斌, 机械工业出版社, 2017.















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









